- pandas.DataFrame.dropna#
- pandas.DataFrame.dropna#
- Drop Rows with NAN / NA Drop Missing value in Pandas Python
- Drop all rows that have any NaN (missing) values:
- Drop only if entire row has NaN values:
- Drop only if a row has more than 2 NaN values:
- Drop NaN in a specific column:
- Author
- Related Posts:
- How To Use Python pandas dropna() to Drop NA Values from DataFrame
- Syntax
- Constructing Sample DataFrames
- Dropping All Rows with Missing Values
- Dropping All Columns with Missing Values
- Dropping Rows or Columns if all the Values are Null with how
- Dropping Rows or Columns if a Threshold is Crossed with thresh
- Dropping Rows or Columns for Specific subsets
- Changing the source DataFrame after Dropping Rows or Columns with inplace
- Conclusion
pandas.DataFrame.dropna#
See the User Guide for more on which values are considered missing, and how to work with missing data.
Parameters axis , default 0
Determine if rows or columns which contain missing values are removed.
- 0, or ‘index’ : Drop rows which contain missing values.
- 1, or ‘columns’ : Drop columns which contain missing value.
Pass tuple or list to drop on multiple axes. Only a single axis is allowed.
how , default ‘any’
Determine if row or column is removed from DataFrame, when we have at least one NA or all NA.
- ‘any’ : If any NA values are present, drop that row or column.
- ‘all’ : If all values are NA, drop that row or column.
Require that many non-NA values. Cannot be combined with how.
subset column label or sequence of labels, optional
Labels along other axis to consider, e.g. if you are dropping rows these would be a list of columns to include.
inplace bool, default False
Whether to modify the DataFrame rather than creating a new one.
ignore_index bool, default False
If True , the resulting axis will be labeled 0, 1, …, n — 1.
DataFrame with NA entries dropped from it or None if inplace=True .
Indicate existing (non-missing) values.
>>> df = pd.DataFrame("name": ['Alfred', 'Batman', 'Catwoman'], . "toy": [np.nan, 'Batmobile', 'Bullwhip'], . "born": [pd.NaT, pd.Timestamp("1940-04-25"), . pd.NaT]>) >>> df name toy born 0 Alfred NaN NaT 1 Batman Batmobile 1940-04-25 2 Catwoman Bullwhip NaT
Drop the rows where at least one element is missing.
>>> df.dropna() name toy born 1 Batman Batmobile 1940-04-25
Drop the columns where at least one element is missing.
>>> df.dropna(axis='columns') name 0 Alfred 1 Batman 2 Catwoman
Drop the rows where all elements are missing.
>>> df.dropna(how='all') name toy born 0 Alfred NaN NaT 1 Batman Batmobile 1940-04-25 2 Catwoman Bullwhip NaT
Keep only the rows with at least 2 non-NA values.
>>> df.dropna(thresh=2) name toy born 1 Batman Batmobile 1940-04-25 2 Catwoman Bullwhip NaT
Define in which columns to look for missing values.
>>> df.dropna(subset=['name', 'toy']) name toy born 1 Batman Batmobile 1940-04-25 2 Catwoman Bullwhip NaT
pandas.DataFrame.dropna#
See the User Guide for more on which values are considered missing, and how to work with missing data.
Parameters axis , default 0
Determine if rows or columns which contain missing values are removed.
- 0, or ‘index’ : Drop rows which contain missing values.
- 1, or ‘columns’ : Drop columns which contain missing value.
Pass tuple or list to drop on multiple axes. Only a single axis is allowed.
how , default ‘any’
Determine if row or column is removed from DataFrame, when we have at least one NA or all NA.
- ‘any’ : If any NA values are present, drop that row or column.
- ‘all’ : If all values are NA, drop that row or column.
Require that many non-NA values. Cannot be combined with how.
subset column label or sequence of labels, optional
Labels along other axis to consider, e.g. if you are dropping rows these would be a list of columns to include.
inplace bool, default False
Whether to modify the DataFrame rather than creating a new one.
ignore_index bool, default False
If True , the resulting axis will be labeled 0, 1, …, n — 1.
DataFrame with NA entries dropped from it or None if inplace=True .
Indicate existing (non-missing) values.
>>> df = pd.DataFrame("name": ['Alfred', 'Batman', 'Catwoman'], . "toy": [np.nan, 'Batmobile', 'Bullwhip'], . "born": [pd.NaT, pd.Timestamp("1940-04-25"), . pd.NaT]>) >>> df name toy born 0 Alfred NaN NaT 1 Batman Batmobile 1940-04-25 2 Catwoman Bullwhip NaT
Drop the rows where at least one element is missing.
>>> df.dropna() name toy born 1 Batman Batmobile 1940-04-25
Drop the columns where at least one element is missing.
>>> df.dropna(axis='columns') name 0 Alfred 1 Batman 2 Catwoman
Drop the rows where all elements are missing.
>>> df.dropna(how='all') name toy born 0 Alfred NaN NaT 1 Batman Batmobile 1940-04-25 2 Catwoman Bullwhip NaT
Keep only the rows with at least 2 non-NA values.
>>> df.dropna(thresh=2) name toy born 1 Batman Batmobile 1940-04-25 2 Catwoman Bullwhip NaT
Define in which columns to look for missing values.
>>> df.dropna(subset=['name', 'toy']) name toy born 1 Batman Batmobile 1940-04-25 2 Catwoman Bullwhip NaT
Drop Rows with NAN / NA Drop Missing value in Pandas Python
Drop missing value in Pandas python or Drop rows with NAN/NA in Pandas python can be achieved under multiple scenarios. Which is listed below.
- drop all rows that have any NaN (missing) values
- drop only if entire row has NaN (missing) values
- drop only if a row has more than 2 NaN (missing) values
- drop NaN (missing) in a specific column
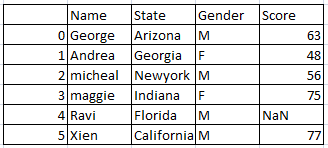
First let’s create a dataframe.
import pandas as pd import numpy as np #Create a DataFrame df1 = < 'Name':['George','Andrea','micheal','maggie','Ravi','Xien','Jalpa',np.nan], 'State':['Arizona','Georgia','Newyork','Indiana','Florida','California',np.nan,np.nan], 'Gender':["M","F","M","F","M","M",np.nan,np.nan], 'Score':[63,48,56,75,np.nan,77,np.nan,np.nan] >df1 = pd.DataFrame(df1,columns=['Name','State','Gender','Score']) print(df1)
so the resultant dataframe will be
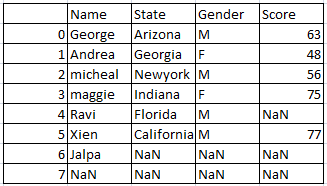
Drop all rows that have any NaN (missing) values:
Drop the rows even with single NaN or single missing values.
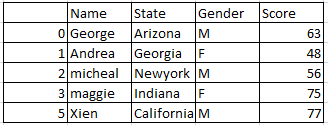
Drop only if entire row has NaN values:
Drop the rows if entire row has NaN (missing) values
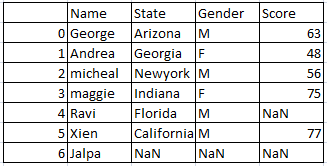
Drop only if a row has more than 2 NaN values:
Drop the rows if that row has more than 2 NaN (missing) values
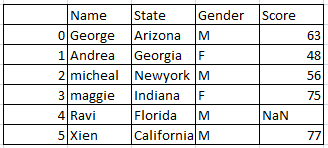
Drop NaN in a specific column:
Drop rows with NaN in a specific column . here we are removing Missing values in Gender column
Author
With close to 10 years on Experience in data science and machine learning Have extensively worked on programming languages like R, Python (Pandas), SAS, Pyspark. View all posts
Related Posts:
How To Use Python pandas dropna() to Drop NA Values from DataFrame

In this tutorial, you’ll learn how to use panda’s DataFrame dropna() function.
NA values are “Not Available”. This can apply to Null , None , pandas.NaT , or numpy.nan . Using dropna() will drop the rows and columns with these values. This can be beneficial to provide you with only valid data.
By default, this function returns a new DataFrame and the source DataFrame remains unchanged.
This tutorial was verified with Python 3.10.9, pandas 1.5.2, and NumPy 1.24.1.
Syntax
dropna() takes the following parameters:
dropna(self, axis=0, how="any", thresh=None, subset=None, inplace=False) - axis : , default 0
- If 0 , drop rows with missing values.
- If 1 , drop columns with missing values.
- how : , default ‘any’
- If ‘any’ , drop the row or column if any of the values is NA .
- If ‘all’ , drop the row or column if all of the values are NA .
- thresh : (optional) an int value to specify the threshold for the drop operation.
- subset : (optional) column label or sequence of labels to specify rows or columns.
- inplace : (optional) a bool value.
- If True , the source DataFrame is changed and None is returned.
Constructing Sample DataFrames
Construct a sample DataFrame that contains valid and invalid values:
import pandas as pd import numpy as np d1 = 'Name': ['Shark', 'Whale', 'Jellyfish', 'Starfish'], 'ID': [1, 2, 3, 4], 'Population': [100, 200, np.nan, pd.NaT], 'Regions': [1, None, pd.NaT, pd.NaT] > df1 = pd.DataFrame(d1) print(df1) This code will print out the DataFrame:
OutputName ID Population Regions 0 Shark 1 100 1 1 Whale 2 200 None 2 Jellyfish 3 NaN NaT 3 Starfish 4 NaT NaT Then add a second DataFrame with additional rows and columns with NA values:
d2 = 'Name': ['Shark', 'Whale', 'Jellyfish', 'Starfish', pd.NaT], 'ID': [1, 2, 3, 4, pd.NaT], 'Population': [100, 200, np.nan, pd.NaT, pd.NaT], 'Regions': [1, None, pd.NaT, pd.NaT, pd.NaT], 'Endangered': [pd.NaT, pd.NaT, pd.NaT, pd.NaT, pd.NaT] > df2 = pd.DataFrame(d2) print(df2) This will output a new DataFrame:
OutputName ID Population Regions Endangered 0 Shark 1 100 1 NaT 1 Whale 2 200 None NaT 2 Jellyfish 3 NaN NaT NaT 3 Starfish 4 NaT NaT NaT 4 NaT NaT NaT NaT NaT You will use the preceding DataFrames in the examples that follow.
Dropping All Rows with Missing Values
Use dropna() to remove rows with any None , NaN , or NaT values:
dfresult = df1.dropna() print(dfresult) OutputName ID Population Regions 0 Shark 1 100 1 A new DataFrame with a single row that didn’t contain any NA values.
Dropping All Columns with Missing Values
Use dropna() with axis=1 to remove columns with any None , NaN , or NaT values:
dfresult = df1.dropna(axis=1) print(dfresult) The columns with any None , NaN , or NaT values will be dropped:
OutputName ID 0 Shark 1 1 Whale 2 2 Jellyfish 3 3 Starfish 4 A new DataFrame with a single column that contained non- NA values.
Dropping Rows or Columns if all the Values are Null with how
Use the second DataFrame and how :
dfresult = df2.dropna(how='all') print(dfresult) The rows with all values equal to NA will be dropped:
OutputName ID Population Regions Endangered 0 Shark 1 100 1 NaT 1 Whale 2 200 None NaT 2 Jellyfish 3 NaN NaT NaT 3 Starfish 4 NaT NaT NaT The fifth row was dropped.
Next, use how and specify the axis :
dfresult = df2.dropna(how='all', axis=1) print(dfresult) The columns with all values equal to NA will be dropped:
OutputName ID Population Regions 0 Shark 1 100 1 1 Whale 2 200 None 2 Jellyfish 3 NaN NaT 3 Starfish 4 NaT NaT 4 NaT NaT NaT NaT The fifth column was dropped.
Dropping Rows or Columns if a Threshold is Crossed with thresh
Use the second DataFrame with thresh to drop rows that do not meet the threshold of at least 3 non- NA values:
dfresult = df2.dropna(thresh=3) print(dfresult) The rows do not have at least 3 non- NA will be dropped:
OutputName ID Population Regions Endangered 0 Shark 1 100 1 NaT 1 Whale 2 200 None NaT The third, fourth, and fifth rows were dropped.
Dropping Rows or Columns for Specific subsets
Use the second DataFrame with subset to drop rows with NA values in the Population column:
dfresult = df2.dropna(subset=['Population']) print(dfresult) The rows that have Population with NA values will be dropped:
OutputName ID Population Regions Endangered 0 Shark 1 100 1 NaT 1 Whale 2 200 None NaT The third, fourth, and fifth rows were dropped.
You can also specify the index values in the subset when dropping columns from the DataFrame:
dfresult = df2.dropna(subset=[1, 2], axis=1) print(dfresult) The columns that contain NA values in subset of rows 1 and 2 :
OutputName ID 0 Shark 1 1 Whale 2 2 Jellyfish 3 3 Starfish 4 4 NaT NaT The third, fourth, and fifth columns were dropped.
Changing the source DataFrame after Dropping Rows or Columns with inplace
By default, dropna() does not modify the source DataFrame. However, in some cases, you may wish to save memory when working with a large source DataFrame by using inplace .
df1.dropna(inplace=True) print(df1) This code does not use a dfresult variable.
OutputName ID Population Regions 0 Shark 1 100 1 The original DataFrame has been modified.
Conclusion
In this article, you used the dropna() function to remove rows and columns with NA values.
Continue your learning with more Python and pandas tutorials — Python pandas Module Tutorial, pandas Drop Duplicate Rows.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.