- 8 примеров использования value_counts из Pandas
- Что такое функция value_counts()?
- Загрузка данных для демонстрации
- 1. value_counts с параметрами по умолчанию
- 2. Сортировка по возрастанию
- 3. Сортировка в алфавитном порядке
- 4. Сортировка по значению, а затем по алфавиту
- 5. Относительная частота уникальных значений
- 6. value_counts() для разбивки данных на дискретные интервалы
- 7. value_counts() с пропусками
- 8. value_counts() как dataframe
- Groupby и value_counts
- Фильтрация значений по минимум и максимум
- Тест на знание функции value_counts
- Как подсчитать уникальные значения в Pandas (с примерами)
- Пример 1. Подсчет уникальных значений в каждом столбце
- Пример 2. Подсчет уникальных значений в каждой строке
- Пример 3. Подсчет уникальных значений по группам
- Дополнительные ресурсы
- pandas.Series.value_counts#
8 примеров использования value_counts из Pandas
Прежде чем начинать работать над проектом, связанным с данными, нужно посмотреть на набор данных. Разведочный анализ данных (EDA) — очень важный этап, ведь данные могут быть запутанными, и очень многое может пойти не по плану в процессе работы.
В библиотеке Pandas есть несколько функций для решения этой проблемы, и value_counts — одна из них. Она возвращает объект, содержащий уникальные значения из dataframe Pandas в отсортированном порядке. Однако многие забывают об этой возможности и используют параметры по умолчанию. В этом материале посмотрим, как получить максимум пользы от value_counts , изменив параметры по умолчанию.
Что такое функция value_counts()?
Функция value_counts() используется для получения Series , содержащего уникальные значения. Она вернет результат, отсортированный в порядке убывания, так что первый элемент в коллекции будет самым встречаемым. NA-значения не включены в результат.
Синтаксис
df[‘your_column’].value_counts() — вернет количество уникальных совпадений в определенной колонке.
Важно заметить, что value_counts работает только с series, но не dataframe. Поэтому нужно указать одни квадратные скобки df[‘your_column’] , а не пару df[[‘your_column’]] .
- normalize (bool, по умолчанию False) — если True , то возвращаемый объект будет содержать значения относительно частоты встречаемых значений.
- sort (bool, по умолчанию True) — сортировка по частоте.
- ascending (bool, по умолчанию False) — сортировка по возрастанию.
- bins (int) — вместе подсчета значений группирует их по отрезкам, но это работает только с числовыми данными.
- dropna (bool, по умолчанию True) — не включать количество NaN.
Загрузка данных для демонстрации
Рассмотрим, как использовать этот метод на реальных данных. Возьмем в качестве примера датасет из курса Coursera на Kaggle.
Для начала импортируем нужные библиотеки и сами данные. Это нужно в любом проекте. После этого проанализируем данные в notebook Jupyter.
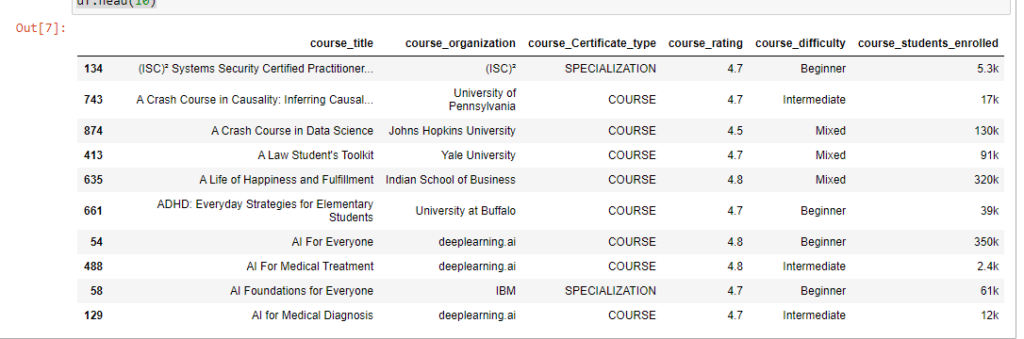
# импорт библиотеки import pandas as pd # Загрузка данных df = pd.read_csv('Downloads/coursea_data.csv', index_col=0) # проверка данных из csv df.head(10)
Проверьте, сколько записей в датасете и есть ли у нас пропуски.
Результат показывает, что в наборе 981 запись, и нет ни одного NA.
Int64Index: 891 entries, 134 to 163 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 course_title 891 non-null object 1 course_organization 891 non-null object 2 course_Certificate_type 891 non-null object 3 course_rating 891 non-null float64 4 course_difficulty 891 non-null object 5 course_students_enrolled 891 non-null object dtypes: float64(1), object(5) memory usage: 48.7+ KB1. value_counts с параметрами по умолчанию
Теперь можно начинать использовать функцию value_counts . Начнем с базового применения функции.
Синтаксис: df['your_column'].value_counts() .
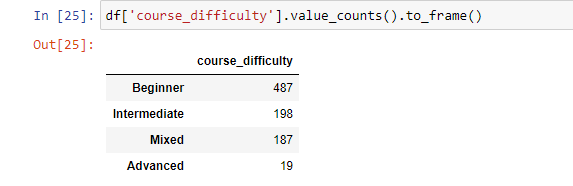
Получим количество каждого значения для колонки «course_difficulty».
Функция value_counts вернет количество совпадений всех уникальных значений по заданному индексу без пропусков. Это позволит увидеть, что больше всего курсов с уровнем сложности «Начинающий», после этого идут «Средний» и «Смешанный». А «Сложный» на последнем месте.
df['course_difficulty'].value_counts() --------------------------------------------------- Beginner 487 Intermediate 198 Mixed 187 Advanced 19 Name: course_difficulty, dtype: int64Теперь время поработать с параметрами.
2. Сортировка по возрастанию
По умолчанию value_counts() возвращает данные по убыванию. Изменит поведение можно, задав значение True для параметра ascending .
Синтаксис: df['your_column'].value_counts(ascending=True) .
df['course_difficulty'].value_counts(ascending=True) --------------------------------------------------- Advanced 19 Mixed 187 Intermediate 198 Beginner 487 Name: course_difficulty, dtype: int643. Сортировка в алфавитном порядке
В определенных случаях может существовать необходимость отсортировать записи в алфавитном порядке. Это делается с помощью добавления sort_index(ascending=True) после value_counts() .
По умолчанию функция сортирует «course_difficulty» по количеству совпадений, а с sort_index сортирует по индексу (имени колонки, для которой и используется функция):
df['course_difficulty'].value_counts().sort_index(ascending=True) --------------------------------------------------- Advanced 19 Beginner 487 Intermediate 198 Mixed 187 Name: course_difficulty, dtype: int64Если же требуется отобразить value_counts() в обратном алфавитном порядке, то нужно изменить направление сортировки: .sort_index(ascending=False) .
4. Сортировка по значению, а затем по алфавиту
Для этого примера используем другой датасет.
Так, нужно получить вывод, отсортированный в первую очередь по количеству совпадений значений, а потом уже и по алфавиту. Это можно сделать, объединив value_counts() c sort_index(ascending=False) и sort_values(ascending=False) .
df_fruit['fruit'].value_counts()\ .sort_index(ascending=False)\ .sort_values(ascending=False) ------------------------------------------------- хурма 5 яблоки 5 бананы 3 морковь 3 персики 3 манго 2 абрикосы 1 Name: fruit, dtype: int645. Относительная частота уникальных значений
Иногда нужно получить относительные значения, а не просто количество. С параметром normalize=True объект вернет относительную частоту уникальных значений. По умолчанию значение этого параметра равно False .
Синтаксис: df['your_column'].value_counts(normalize=True) .
df['course_difficulty'].value_counts(normalize=True) ------------------------------------------------- Beginner 0.546577 Intermediate 0.222222 Mixed 0.209877 Advanced 0.021324 Name: course_difficulty, dtype: float646. value_counts() для разбивки данных на дискретные интервалы
Еще один трюк, который часто игнорируют. value_counts() можно использовать для разбивки данных на дискретные интервалы с помощью параметра bin . Это работает только с числовыми данными. Принцип напоминает pd.cut . Посмотрим как это работает на примере колонки «course_rating». Сгруппируем значения колонки на 4 группы.
Синтаксис: df['your_column'].value_counts(bin=количество групп) .
df['course_rating'].value_counts(bins=4) ------------------------------------------------- (4.575, 5.0] 745 (4.15, 4.575] 139 (3.725, 4.15] 5 (3.297, 3.725] 2 Name: course_rating, dtype: int64Бинниг позволяет легко получить инсайты. Так, можно увидеть, что большая часть людей оценивает курс на 4.5. И лишь несколько курсов имеют оценку ниже 4.15.
7. value_counts() с пропусками
По умолчанию количество значений NaN не включается в результат. Но это поведение можно изменить, задав значение False для параметра dropna . Поскольку в наборе данных нет нулевых значений, в этом примере это ни на что не повлияет. Но сам параметр следует запомнить.
Синтаксис: df['your_column'].value_counts(dropna=False) .
8. value_counts() как dataframe
Как уже было отмечено, value_counts() возвращает Series, а не Dataframe. Если же нужно получить результаты в последнем виде, то для этого можно использовать функцию .to_frame() после .value_counts() .
Синтаксис: df['your_column'].value_counts().to_frame() .
Это будет выглядеть следующим образом:
Если нужно задать имя для колонки или переименовать существующую, то эту конвертацию можно реализовать другим путем.
value_counts = df['course_difficulty'].value_counts() # преобразование в df и присвоение новых имен колонкам df_value_counts = pd.DataFrame(value_counts) df_value_counts = df_value_counts.reset_index() df_value_counts.columns = ['unique_values', 'counts for course_difficulty'] df_value_countsGroupby и value_counts
Groupby — очень популярный метод в Pandas. С его помощью можно сгруппировать результат по одной колонке и посчитать значения в другой.
Синтаксис: df.groupby('your_column_1')['your_column_2'].value_counts() .
Так, с помощью groupby и value_counts можно посчитать количество типов сертификатов для каждого уровня сложности курсов.
df.groupby('course_difficulty')['course_Certificate_type'].value_counts() ------------------------------------------------- course_difficulty course_Certificate_type Advanced SPECIALIZATION 10 COURSE 9 Beginner COURSE 282 SPECIALIZATION 196 PROFESSIONAL CERTIFICATE 9 Intermediate COURSE 104 SPECIALIZATION 91 PROFESSIONAL CERTIFICATE 3 Mixed COURSE 187 Name: course_Certificate_type, dtype: int64Это мульти-индекс, позволяющий иметь несколько уровней индексов в dataframe. В этом случае сложность курса соответствует нулевому уровню индекса, а тип сертификата — первому.
Фильтрация значений по минимум и максимум
Работая с набором данных, может потребоваться вернуть количество ограниченных вхождений с помощью value_counts() .
Синтаксис: df['your_column'].value_counts().loc[lambda x : x > 1] .
Этот код отфильтрует все значения уникальных данных и покажет только те, где значение больше единицы.
Для примера ограничим рейтинг курса значением 4.
df.groupby('course_difficulty')['coudf['course_rating']\ .value_counts().loc[lambda x: x > 4] ------------------------------------------------- 4.8 256 4.7 251 4.6 168 4.5 80 4.9 68 4.4 34 4.3 15 4.2 10 Name: course_rating, dtype: int64value_counts() — удобный инструмент, позволяющий делать удобный анализ в одну строку.
Тест на знание функции value_counts
Дана колонка с днями недели, где 1 - понедельник, 7 - воскресенье. Как получить относительное количество только будних дней?
Как подсчитать уникальные значения в Pandas (с примерами)
Вы можете использовать функцию nunique() для подсчета количества уникальных значений в кадре данных pandas.
Эта функция использует следующий базовый синтаксис:
#count unique values in each column df.nunique () #count unique values in each row df.nunique (axis= 1 )В следующих примерах показано, как использовать эту функцию на практике со следующими пандами DataFrame:
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame df team points assists rebounds 0 A 8 5 11 1 A 8 8 8 2 A 13 7 11 3 A 13 9 6 4 B 22 12 6 5 B 22 9 5 6 B 25 9 9 7 B 29 4 12Пример 1. Подсчет уникальных значений в каждом столбце
Следующий код показывает, как подсчитать количество уникальных значений в каждом столбце DataFrame:
#count unique values in each column df.nunique () team 2 points 5 assists 5 rebounds 6 dtype: int64
- Столбец «команда» имеет 2 уникальных значения.
- Столбец «баллы» имеет 5 уникальных значений.
- Столбец «Помощь» имеет 5 уникальных значений.
- Столбец «Подборы» имеет 6 уникальных значений.
Пример 2. Подсчет уникальных значений в каждой строке
В следующем коде показано, как подсчитать количество уникальных значений в каждой строке DataFrame:
#count unique values in each row df.nunique (axis= 1 ) 0 4 1 2 2 4 3 4 4 4 5 4 6 3 7 4 dtype: int64 - Первая строка имеет 4 уникальных значения
- Вторая строка имеет 2 уникальных значения
- Третья строка имеет 4 уникальных значения
Пример 3. Подсчет уникальных значений по группам
В следующем коде показано, как подсчитать количество уникальных значений по группам в DataFrame:
#count unique 'points' values, grouped by team df.groupby('team')['points']. nunique () team A 2 B 3 Name: points, dtype: int64 - Команда «А» имеет 2 уникальных значения «очков».
- Команда «Б» имеет 3 уникальных значения «очков».
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в pandas:
pandas.Series.value_counts#
The resulting object will be in descending order so that the first element is the most frequently-occurring element. Excludes NA values by default.
Parameters normalize bool, default False
If True then the object returned will contain the relative frequencies of the unique values.
sort bool, default True
ascending bool, default False
bins int, optional
Rather than count values, group them into half-open bins, a convenience for pd.cut , only works with numeric data.
dropna bool, default True
Don’t include counts of NaN.
Number of non-NA elements in a Series.
Number of non-NA elements in a DataFrame.
Equivalent method on DataFrames.
>>> index = pd.Index([3, 1, 2, 3, 4, np.nan]) >>> index.value_counts() 3.0 2 1.0 1 2.0 1 4.0 1 Name: count, dtype: int64
With normalize set to True , returns the relative frequency by dividing all values by the sum of values.
>>> s = pd.Series([3, 1, 2, 3, 4, np.nan]) >>> s.value_counts(normalize=True) 3.0 0.4 1.0 0.2 2.0 0.2 4.0 0.2 Name: proportion, dtype: float64
Bins can be useful for going from a continuous variable to a categorical variable; instead of counting unique apparitions of values, divide the index in the specified number of half-open bins.
>>> s.value_counts(bins=3) (0.996, 2.0] 2 (2.0, 3.0] 2 (3.0, 4.0] 1 Name: count, dtype: int64
With dropna set to False we can also see NaN index values.
>>> s.value_counts(dropna=False) 3.0 2 1.0 1 2.0 1 4.0 1 NaN 1 Name: count, dtype: int64