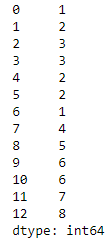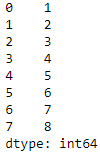- Pandas Drop Duplicate Rows in DataFrame
- 1. Quick Examples of Drop Duplicate Rows
- 2. drop_duplicates() Syntax & Examples
- 3. Pandas Drop Duplicate Rows
- 4. Drop Duplicate Rows and Keep the Last Row
- 5. Remove All Duplicate Rows from Pandas DataFrame
- 6. Delete Duplicate Rows based on Specific Columns
- 7. Drop Duplicate Rows In Place
- 8. Remove Duplicate Rows Using DataFrame.apply() and Lambda Function
- 9. Complete Example For Drop Duplicate Rows in DataFrame
- Conclusion
- Related Articles
- References
- You may also like reading:
- Как удалить повторяющиеся строки в Pandas DataFrame
- Пример 1. Удаление дубликатов во всех столбцах
- Пример 2. Удаление дубликатов в определенных столбцах
- pandas.DataFrame.drop_duplicates#
- How to remove duplicate data from python dataframe
- Create Dataframe with Duplicate data
- Drop the Duplicate rows
- Drop Duplicates from a specific Column and Keep last row
- Drop Duplicates from a specific Column and Keep first row
- Drop all Duplicates from a specific Column
- Drop Duplicates in a group but keep the row with maximum value
- Drop Duplicates in a group but keep the row with minimum value
- Drop Duplicates based on condition
- Drop Duplicates across multiple Columns using Subset parameter
- Drop Duplicates from Series
- Drop Duplicates and reset Index
- Share on
- You may also enjoy
- pandas count duplicate rows
- Pandas value error while merging two dataframes with different data types
- How to get True Positive, False Positive, True Negative and False Negative from confusion matrix in scikit learn
- Pandas how to use list of values to select rows from a dataframe
Pandas Drop Duplicate Rows in DataFrame
By using pandas.DataFrame.drop_duplicates() method you can remove duplicate rows from DataFrame. Using this method you can drop duplicate rows on selected multiple columns or all columns. In this article, we’ll explain several ways of how to drop duplicate rows from Pandas DataFrame with examples by using functions like DataFrame.drop_duplicates() , DataFrame.apply() and lambda function with examples.
1. Quick Examples of Drop Duplicate Rows
If you are in a hurry, below are some quick examples of how to drop duplicate rows in pandas DataFrame.
2. drop_duplicates() Syntax & Examples
Below is the syntax of the DataFrame.drop_duplicates() function that removes duplicate rows from the pandas DataFrame.
- subset – Column label or sequence of labels. It’s default value is none. After passing columns, consider for identifying duplicate rows.
- keep – Allowed values are , default ‘first’.
- ‘first’ – Duplicate rows except for the first one is drop.
- ‘last’ – Duplicate rows except for the last one is drop.
- False – All duplicate rows are drop.
Now, let’s create a DataFrame with a few duplicate rows on columns. Our DataFrame contains column names Courses , Fee , Duration , and Discount .
df = pd.DataFrame(technologies) print(df)3. Pandas Drop Duplicate Rows
You can use DataFrame.drop_duplicates() without any arguments to drop rows with the same values on all columns. It takes defaults values subset=None and keep=‘first’ . The below example returns four rows after removing duplicate rows in our DataFrame.
4. Drop Duplicate Rows and Keep the Last Row
If you want to select all the duplicate rows and their last occurrence, you must pass a keep argument as «last» . For instance, df.drop_duplicates(keep=’last’) .
5. Remove All Duplicate Rows from Pandas DataFrame
You can set ‘keep=False’ in the drop_duplicates() function to remove all the duplicate rows. For E.x, df.drop_duplicates(keep=False) .
6. Delete Duplicate Rows based on Specific Columns
To delete duplicate rows on the basis of multiple columns, specify all column names as a list. You can set ‘keep=False’ in the drop_duplicates() function to remove all the duplicate rows.
Yields the same output as above.
7. Drop Duplicate Rows In Place
8. Remove Duplicate Rows Using DataFrame.apply() and Lambda Function
You can remove duplicate rows using DataFrame.apply() and lambda function to convert the DataFrame to lower case and then apply lower string.
Yields same output as above.
9. Complete Example For Drop Duplicate Rows in DataFrame
df = pd.DataFrame(technologies) print(df) # keep first duplicate row df2 = df.drop_duplicates() print(df2) # Using DataFrame.drop_duplicates() to keep first duplicate row df2 = df.drop_duplicates(keep='first') print(df2) # keep last duplicate row df2 = df.drop_duplicates( keep='last') print(df2) # Remove all duplicate rows df2 = df.drop_duplicates(keep=False) print(df2) # Delete duplicate rows based on specific columns df2 = df.drop_duplicates(subset=["Courses", "Fee"], keep=False) print(df2) # Drop duplicate rows in place df.drop_duplicates(inplace=True) print(df) # Using DataFrame.apply() and lambda function df2 = df.apply(lambda x: x.astype(str).str.lower()).drop_duplicates(subset=['Courses', 'Fee'], keep='first') print(df2)Conclusion
In this article, you have learned how to drop/remove/delete duplicate rows using pandas.DataFrame.drop_duplicates() , DataFrame.apply() and lambda function with examples.
Related Articles
References
You may also like reading:
Как удалить повторяющиеся строки в Pandas DataFrame
Самый простой способ удалить повторяющиеся строки в кадре данных pandas — использовать функцию drop_duplicates() , которая использует следующий синтаксис:
df.drop_duplicates (подмножество = нет, сохранить = «первый», inplace = ложь)
- подмножество: какие столбцы следует учитывать для выявления дубликатов. По умолчанию все столбцы.
- keep: Указывает, какие дубликаты (если они есть) нужно сохранить.
- first: удалить все повторяющиеся строки, кроме первой.
- last: удалить все повторяющиеся строки, кроме последней.
- False : удалить все дубликаты.
- inplace: указывает, следует ли удалить дубликаты на месте или вернуть копию DataFrame.
В этом руководстве представлено несколько примеров практического использования этой функции в следующем кадре данных:
import pandas as pd #create DataFrame df = pd.DataFrame() #display DataFrame print(df) team points assists 0 a 3 8 1 b 7 6 2 b 7 7 3 c 8 9 4 c 8 9 5 d 9 3Пример 1. Удаление дубликатов во всех столбцах
В следующем коде показано, как удалить строки с повторяющимися значениями во всех столбцах:
df.drop_duplicates () team points assists 0 a 3 8 1 b 7 6 2 b 7 7 3 c 8 9 5 d 9 3По умолчанию функция drop_duplicates() удаляет все дубликаты, кроме первого.
Однако мы могли бы использовать аргумент keep=False для полного удаления всех дубликатов:
df.drop_duplicates (keep= False ) team points assists 0 a 3 8 1 b 7 6 2 b 7 7 5 d 9 3Пример 2. Удаление дубликатов в определенных столбцах
В следующем коде показано, как удалить строки с повторяющимися значениями только в столбцах с названиями team и points :
df.drop_duplicates (subset=['team', 'points']) team points assists 0 a 3 8 1 b 7 6 3 c 8 9 5 d 9 3pandas.DataFrame.drop_duplicates#
Considering certain columns is optional. Indexes, including time indexes are ignored.
Parameters subset column label or sequence of labels, optional
Only consider certain columns for identifying duplicates, by default use all of the columns.
keep , default ‘first’
Determines which duplicates (if any) to keep.
- ‘first’ : Drop duplicates except for the first occurrence.
- ‘last’ : Drop duplicates except for the last occurrence.
- False : Drop all duplicates.
Whether to modify the DataFrame rather than creating a new one.
ignore_index bool, default False
If True , the resulting axis will be labeled 0, 1, …, n — 1.
Returns DataFrame or None
DataFrame with duplicates removed or None if inplace=True .
Count unique combinations of columns.
Consider dataset containing ramen rating.
>>> df = pd.DataFrame( . 'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'], . 'style': ['cup', 'cup', 'cup', 'pack', 'pack'], . 'rating': [4, 4, 3.5, 15, 5] . >) >>> df brand style rating 0 Yum Yum cup 4.0 1 Yum Yum cup 4.0 2 Indomie cup 3.5 3 Indomie pack 15.0 4 Indomie pack 5.0
By default, it removes duplicate rows based on all columns.
>>> df.drop_duplicates() brand style rating 0 Yum Yum cup 4.0 2 Indomie cup 3.5 3 Indomie pack 15.0 4 Indomie pack 5.0
To remove duplicates on specific column(s), use subset .
>>> df.drop_duplicates(subset=['brand']) brand style rating 0 Yum Yum cup 4.0 2 Indomie cup 3.5
To remove duplicates and keep last occurrences, use keep .
>>> df.drop_duplicates(subset=['brand', 'style'], keep='last') brand style rating 1 Yum Yum cup 4.0 2 Indomie cup 3.5 4 Indomie pack 5.0
How to remove duplicate data from python dataframe
Not all data are perfect and we really need to get duplicate data removed from our dataset most of the time. it looks easy to clean up the duplicate data but in reality it isn’t. Sometimes you want to just remove the duplicates from one or more columns and the other time you want to delete duplicates based on some random condition. So we will see in this post how to easily and efficiently you can remove the duplicate data using drop_duplicates() function in pandas
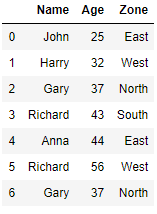
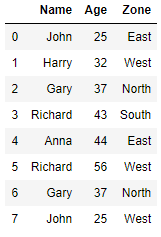
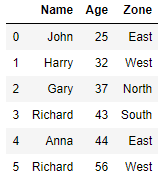
Create Dataframe with Duplicate data
import pandas as pd df = pd.DataFrame()
Drop the Duplicate rows
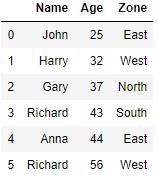
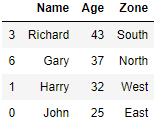
The row at index 2 and 6 in above dataframe are duplicates and all the three columns Name, Age and Zone matches for these two rows. Now we will remove all the duplicate rows from the dataframe using drop_duplicates() function
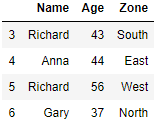
Drop Duplicates from a specific Column and Keep last row
We will group the rows for each zone and just keep the last in each group i.e. For Zone East we have two rows in original dataframe i.e. index 0 and 4 and we want to keep only index 4 in this zone
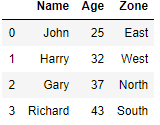
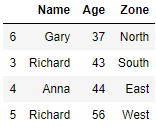
df.drop_duplicates('Zone',keep='last')Drop Duplicates from a specific Column and Keep first row
We will group the rows for each zone and just keep the first in each group i.e. For Zone East we have two rows in original dataframe i.e. index 0 and 4 and we want to keep only index 0 in this zone
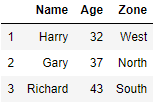
df.drop_duplicates('Zone',keep='first')Drop all Duplicates from a specific Column
We will drop the zone wise duplicate rows in the original dataframe, Just change the value of Keep to False
df.drop_duplicates('Zone',keep=False)Drop Duplicates in a group but keep the row with maximum value
We will keep the row with maximum aged person in each zone. So we will sort the rows by Age first in ascending order and then drop the duplicates in Zone column and set the Keep parameter to Last.
df.sort_values('Age',ascending=True).drop_duplicates('Zone',keep='last')Drop Duplicates in a group but keep the row with minimum value
We will keep the row with minimum aged person in each zone. So we will sort the rows by Age first in descending order and then drop the duplicates in Zone column and set the Keep parameter to Last.
df.sort_values('Age',ascending=False).drop_duplicates('Zone',keep='last')Drop Duplicates based on condition
We will remove duplicates based on the Zone column and where age is greater than 30
df[df.Age.gt(30) & ~(df.duplicated(['Zone'])) ]Drop Duplicates across multiple Columns using Subset parameter
You can drop duplicates from multiple columns as well. just add them as list in subset parameter. Our original dataframe doesn’t have any such value so I will create a dataframe and remove the duplicates from more than one column
Here is a dataframe with row at index 0 and 7 as duplicates with same
import pandas as pd df = pd.DataFrame()Now drop one of the two rows by setting the subset parameter as a list of column
df.drop_duplicates(subset=['Name','Age'])Drop Duplicates from Series
We can also drop duplicates from a Pandas Series . here is a series with multiple duplicate rows
a = pd.Series([1,2,3,3,2,2,1,4,5,6,6,7,8], index=[0,1,2,3,4,5,6,7,8,9,10,11,12]) aDrop Duplicates and reset Index
We will remove the duplicates from series index and reset the index using reset_index() function else it will have the original index from the Series after dropping the Duplicates
a.drop_duplicates().reset_index(drop=True)Updated: October 25, 2019
Share on
You may also enjoy
pandas count duplicate rows
DataFrames are a powerful tool for working with data in Python, and Pandas provides a number of ways to count duplicate rows in a DataFrame. In this article.
Pandas value error while merging two dataframes with different data types
If you’re encountering a “value error” while merging Pandas data frames, this article has got you covered. Learn how to troubleshoot and solve common issues .
How to get True Positive, False Positive, True Negative and False Negative from confusion matrix in scikit learn
In machine learning, we often use classification models to predict the class labels of a set of samples. The predicted labels may or may not match the true .
Pandas how to use list of values to select rows from a dataframe
In this post we will see how to use a list of values to select rows from a pandas dataframe We will follow these steps to select rows based on list of value.