Dask DataFrame¶
A Dask DataFrame is a large parallel DataFrame composed of many smaller pandas DataFrames, split along the index. These pandas DataFrames may live on disk for larger-than-memory computing on a single machine, or on many different machines in a cluster. One Dask DataFrame operation triggers many operations on the constituent pandas DataFrames.
Examples¶
Visit https://examples.dask.org/dataframe.html to see and run examples using Dask DataFrame.
Design¶
Dask DataFrames coordinate many pandas DataFrames/Series arranged along the index. A Dask DataFrame is partitioned row-wise, grouping rows by index value for efficiency. These pandas objects may live on disk or on other machines.
Dask DataFrame copies the pandas DataFrame API¶
Because the dask.DataFrame application programming interface (API) is a subset of the pd.DataFrame API, it should be familiar to pandas users. There are some slight alterations due to the parallel nature of Dask:
>>> import dask.dataframe as dd >>> df = dd.read_csv('2014-*.csv') >>> df.head() x y 0 1 a 1 2 b 2 3 c 3 4 a 4 5 b 5 6 c >>> df2 = df[df.y == 'a'].x + 1 >>> df2.compute() 0 2 3 5 Name: x, dtype: int64
>>> import pandas as pd >>> df = pd.read_csv('2014-1.csv') >>> df.head() x y 0 1 a 1 2 b 2 3 c 3 4 a 4 5 b 5 6 c >>> df2 = df[df.y == 'a'].x + 1 >>> df2 0 2 3 5 Name: x, dtype: int64
As with all Dask collections, you trigger computation by calling the .compute() method.
Common Uses and Anti-Uses¶
Dask DataFrame is used in situations where pandas is commonly needed, usually when pandas fails due to data size or computation speed:
- Manipulating large datasets, even when those datasets don’t fit in memory
- Accelerating long computations by using many cores
- Distributed computing on large datasets with standard pandas operations like groupby, join, and time series computations
Dask DataFrame may not be the best choice in the following situations:
- If your dataset fits comfortably into RAM on your laptop, then you may be better off just using pandas. There may be simpler ways to improve performance than through parallelism
- If your dataset doesn’t fit neatly into the pandas tabular model, then you might find more use in dask.bag or dask.array
- If you need functions that are not implemented in Dask DataFrame, then you might want to look at dask.delayed which offers more flexibility
- If you need a proper database with all that databases offer you might prefer something like Postgres
Scope¶
Dask DataFrame covers a well-used portion of the pandas API. The following class of computations works well:
- Trivially parallelizable operations (fast):
- Element-wise operations: df.x + df.y , df * df
- Row-wise selections: df[df.x > 0]
- Loc: df.loc[4.0:10.5]
- Common aggregations: df.x.max() , df.max()
- Is in: df[df.x.isin([1, 2, 3])]
- Date time/string accessors: df.timestamp.month
- groupby-aggregate (with common aggregations): df.groupby(df.x).y.max() , df.groupby(‘x’).min() (see Aggregate )
- groupby-apply on index: df.groupby([‘idx’, ‘x’]).apply(myfunc) , where idx is the index level name
- value_counts: df.x.value_counts()
- Drop duplicates: df.x.drop_duplicates()
- Join on index: dd.merge(df1, df2, left_index=True, right_index=True) or dd.merge(df1, df2, on=[‘idx’, ‘x’]) where idx is the index name for both df1 and df2
- Join with pandas DataFrames: dd.merge(df1, df2, on=’id’)
- Element-wise operations with different partitions / divisions: df1.x + df2.y
- Date time resampling: df.resample(. )
- Rolling averages: df.rolling(. )
- Pearson’s correlation: df[[‘col1’, ‘col2’]].corr()
- Set index: df.set_index(df.x)
- groupby-apply not on index (with anything): df.groupby(df.x).apply(myfunc)
- Join not on the index: dd.merge(df1, df2, on=’name’)
However, Dask DataFrame does not implement the entire pandas interface. Users expecting this will be disappointed. Notably, Dask DataFrame has the following limitations:
- Setting a new index from an unsorted column is expensive
- Many operations like groupby-apply and join on unsorted columns require setting the index, which as mentioned above, is expensive
- The pandas API is very large. Dask DataFrame does not attempt to implement many pandas features or any of the more exotic data structures like NDFrames
- Operations that were slow on pandas, like iterating through row-by-row, remain slow on Dask DataFrame
See the DataFrame API documentation for a more extensive list.
Execution¶
By default, Dask DataFrame uses the multi-threaded scheduler . This exposes some parallelism when pandas or the underlying NumPy operations release the global interpreter lock (GIL). Generally, pandas is more GIL bound than NumPy, so multi-core speed-ups are not as pronounced for Dask DataFrame as they are for Dask Array. This is particularly true for string-heavy Python DataFrames, as Python strings are GIL bound.
There has been recent work on changing the underlying representation of pandas string data types to be backed by PyArrow Buffers, which should release the GIL, however, this work is still considered experimental.
When dealing with text data, you may see speedups by switching to the distributed scheduler either on a cluster or single machine.
Почему каждый Data Scientist должен знать Dask
Возможно, название сегодняшней публикации лучше смотрелось бы с вопросительным знаком — сложно сказать. В любом случае, сегодня мы хотим предложить вам краткий экскурс, который познакомит вас с библиотекой Dask, предназначенной для распараллеливания задач на Python. Надеемся в дальнейшем вернуться к этой теме более основательно.

Снимок взят по адресу
Dask – без преувеличения наиболее революционный инструмент для обработки данных, который мне попадался. Если вам нравятся Pandas и Numpy, но иногда вам не удается справиться с данными, не умещающимися в RAM, то Dask – именно то, что вам нужно. Dask поддерживает фрейм данных Pandas и структуры данных (массивы) Numpy. Dask можно запускать либо на локальном компьютере, либо масштабировать, а затем запускать в кластере. В сущности, вы пишете код всего один раз, а затем выбираете: использовать ли его на локальной машине, либо развертывать в кластере из множества узлов, используя для всего этого самый обычный синтаксис Python. Сама по себе данная возможность великолепна, но я решил написать эту статью именно для того, чтобы подчеркнуть: каждый Data Scientist (как минимум, использующий Python) должен использовать Dask. С моей точки зрения волшебство Dask заключается в том, что, минимально изменив код, можно распараллеливать его, пользуясь вычислительными мощностями, которые уже имеются, например, у меня на ноутбуке. При параллельной обработке данных программа выполняется быстрее, приходится меньше ждать, соответственно, больше времени остается на аналитику. В частности, в этой статье мы поговорим об объекте dask.delayed и о том, как он вписывается в поток задач науки о данных.
Знакомство с Dask
В качестве знакомства с Dask приведу пару примеров, просто чтобы дать вам представление о его полностью ненавязчивом и естественном синтаксисе. Важнейший вывод, который я хочу подсказать в данном случае – уже имеющихся у вас знаний будет достаточно для работы; вам не придется изучать новый инструмент для обращения с большими данными, например, Hadoop или Spark.
В Dask предлагается 3 параллельные коллекции, в которых можно хранить объем данных, превышающий по размеру RAM, а именно: Dataframes, Bags и Arrays. В каждом из этих типов коллекций можно хранить данные, сегментировав их между RAM и жестким диском, а также распределять данные по множеству узлов в кластере.
Dask DataFrame состоит из измельченных датафреймов, таких, как в Pandas, поэтому позволяет использовать подмножество возможностей из синтаксиса запросов Pandas. Ниже приведен пример кода, загружающий все csv-файлы за 2018 год, разбирающий поле с временной меткой и запускающий запрос Pandas:
import dask.dataframe as dd df = dd.read_csv('logs/2018-*.*.csv', parse_dates=['timestamp']) df.groupby(df.timestamp.dt.hour).value.mean().compute()Пример Dask Dataframe
В Dask Bag можно хранить и обрабатывать коллекции питонических объектов, не умещающихся в памяти. Dask Bag отлично подходит для обработки логов и коллекций документов в формате json. В этом примере с кодом все файлы в формате json за 2018 год загружаются в структуру данных Dask Bag, каждая запись json проходит синтаксический разбор, а данные о пользователях фильтруются при помощи лямбда-функции:
import dask.bag as db import json records = db.read_text('data/2018-*-*.json').map(json.loads) records.filter(lambda d: d['username'] == 'Aneesha').pluck('id').frequencies()Структура данных Dask Arrays поддерживает срезы в стиле Numpy. В следующем примере множество данных HDF5 дробится на блоки размерностью (5000, 5000):
import h5py f = h5py.File('myhdf5file.hdf5') dset = f['/data/path'] import dask.array as da x = da.from_array(dset, chunks=(5000, 5000))Параллельная обработка в Dask
Другое не менее точное название этого раздела могло бы звучать «Смерть последовательного цикла». Мне то и дело встречается распространенный паттерн: перебираем список элементов, после чего выполняем с каждым элементом метод Python, но с разными входными аргументами. Среди распространенных сценариев обработки данных – вычисление совокупностей признаков (feature aggregate) для каждого клиента или выполнение агрегации событий из лога для каждого студента. Вместо применения функции к каждому аргументу в рамках последовательного цикла объект Dask Delayed позволяет обрабатывать множество элементов параллельно. При работе с Dask Delayed все вызовы функций ставятся в очередь, ставятся в граф выполнения, после чего планируется их обработка.
Мне всегда было немного лениво писать собственный механизм обработки потоков или использовать asyncio, так что я даже не буду показывать вам подобных примеров для сравнения. С Dask можно не менять ни синтаксиса, ни стиля программирования! Нужно всего лишь аннотировать или обернуть метод, который будет выполнен параллельно с @dask.delayed и вызвать вычислительный метод после выполнения кода цикла.
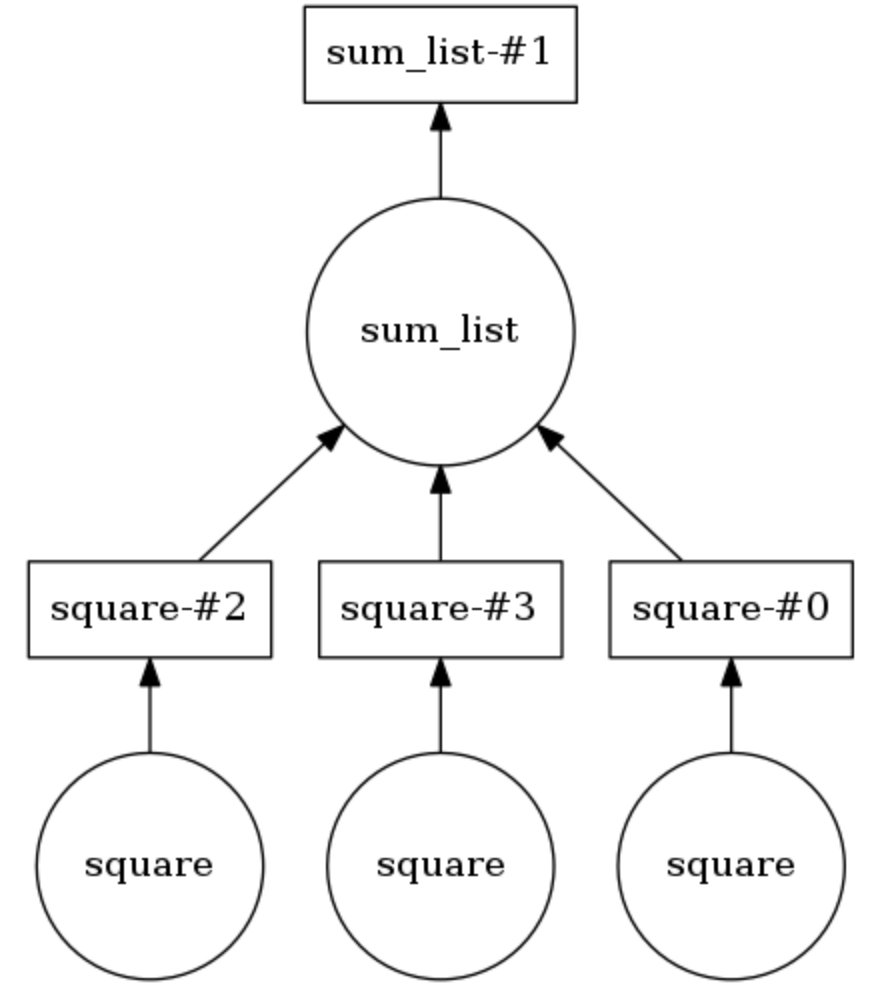
Пример вычислительного графа Dask
В нижеприведенном примере два метода аннотированы @dask.delayed . Три числа хранятся в списке, их нужно возвести в квадрат, а затем все вместе просуммировать. Dask строит вычислительный граф, обеспечивающий параллельное выполнение метода для возведения в квадрат, после чего результат этой операции передается методу sum_list . Вычислительный граф можно вывести на экран, вызвав calling .visualize() . Calling .compute() выполняет вычислительный граф. Как понятно по выводу, элементы списка обрабатываются не по порядку, а параллельно.
Количество потоков можно задать (например, dask.set_options( pool=ThreadPool(10) ), а также их легко подкачивать, чтобы пользоваться процессами у себя на ноутбуке или ПК (напр., dask.config.set( scheduler=’processes’ ).
Итак, я продемонстрировал, насколько тривиально будет добавить параллельную обработку задач в проект из области Data Science при помощи Dask. Незадолго до написания этой статьи я применил Dask, чтобы разделить данные о пользовательских потоках кликов (истории посещений) на 40-минутные сеансы, после чего агрегировать признаки по каждому пользователю для последующей кластеризации. Расскажите, а каким образом вам доводилось использовать Dask!