Регулярные выражения в Python: синтаксис, полезные функции и задачи
Исчерпывающий гайд по работе с мощным инструментом для анализа и обработки строк.

Иллюстрация: Оля Ежак для SKillbox Media

Само словосочетание «регулярные выражения» звучит непонятно и выглядит страшно, но на самом деле ничего сложного в работе с ними нет. В этой статье мы познакомим вас с их логикой и основными принципами и научим разговаривать на языке шаблонов. В хорошем смысле слова.
Что такое регулярные выражения
Представьте, что вы снова в школе, на уроке истории. Вам нужно решить итоговую контрольную работу по всем датам, которые проходили в четверти.
Но тут вас поджидает препятствие: все даты разбросаны по нескольким главам учебника по десятку страниц каждая. Читать полкниги в поисках нужных вам крупиц информации — такое себе удовольствие. Тем более когда каждая минута на счету.
К счастью, вы — человек неглупый (не зря же пошли в IT), тренированный и быстро соображающий. Поэтому моментально замечаете основные закономерности:
- даты обозначаются цифрами: арабскими, если это год и месяц, и римскими, если век;
- учебник — по истории позднего Средневековья и Нового времени, поэтому все даты, написанные арабскими цифрами, — четырёхсимвольные;
- после римских цифр всегда идёт слово «век».
Теперь у вас есть шаблон нужной информации. Остаётся лишь пролистать страницу за страницей и записать даты в смартфон (или себе на подкорку). Вуаля: пятёрка за четверть у вас в дневнике, а премия от родителей за отличную учёбу — в кармане.
По такому же принципу работают и регулярные выражения: они ведут поиск фрагментов текста по определённому шаблону. Если фрагмент совпадает с шаблоном — с ним можно работать.
Запишем логику поиска исторических дат в виде регулярных выражений (они ещё называются Regular Expressions, сокращённо regex или regexp). Выглядеть он будет так:
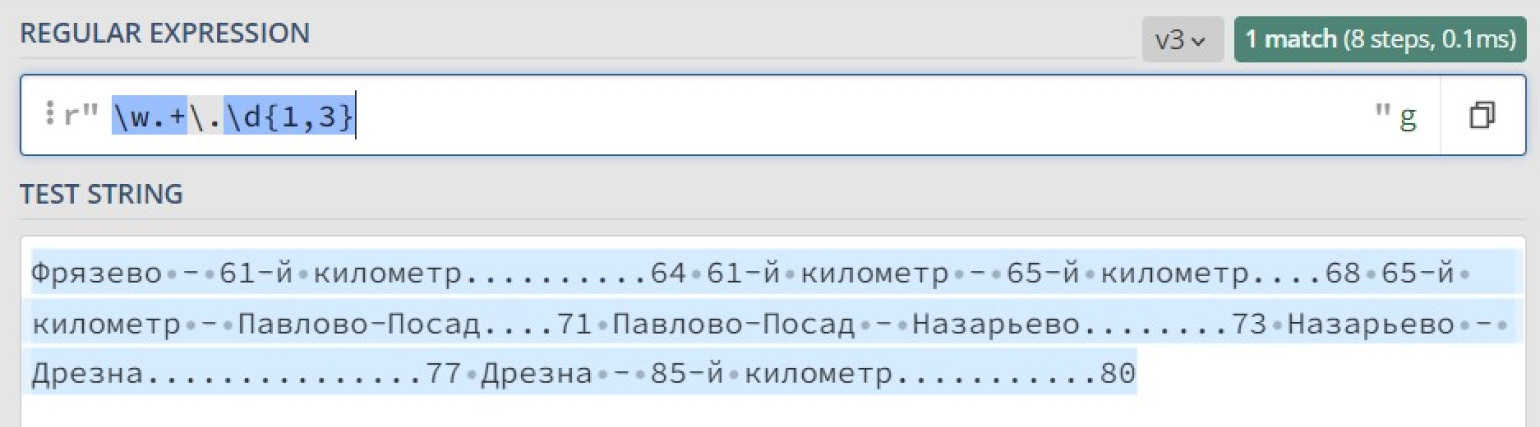
Что же произошло? Почему найдено только одно совпадение, причем за него посчитали весь текст сразу? Всё дело в жадности квантификатора +, который старается захватить максимально возможное количество подходящих символов.
В итоге шаблон \w находит совпадение с буквой «Ф» в начале текста, шаблон \.\d находит совпадение с «.80» в конце текста, а всё, что между ними, покрывается шаблоном .+.
Чтобы квантификатор захватывал минимально возможное количество символов, его нужно сделать ленивым. В таком случае каждый раз, находя совпадение с шаблоном ., регулярное выражение будет спрашивать: «Подходят ли следующие символы в строке под оставшуюся часть шаблона?»
Если нет, то функция будет искать следующее совпадение с .. А если да, то . закончит свою работу и следующие символы строки будут сравниваться со следующей частью регулярного выражения: \.\d .
Чтобы объявить квантификатор ленивым, после него надо поставить символ ?. Сделаем ленивым квантификатор + в нашем регулярном выражении для поиска строк в оглавлении:
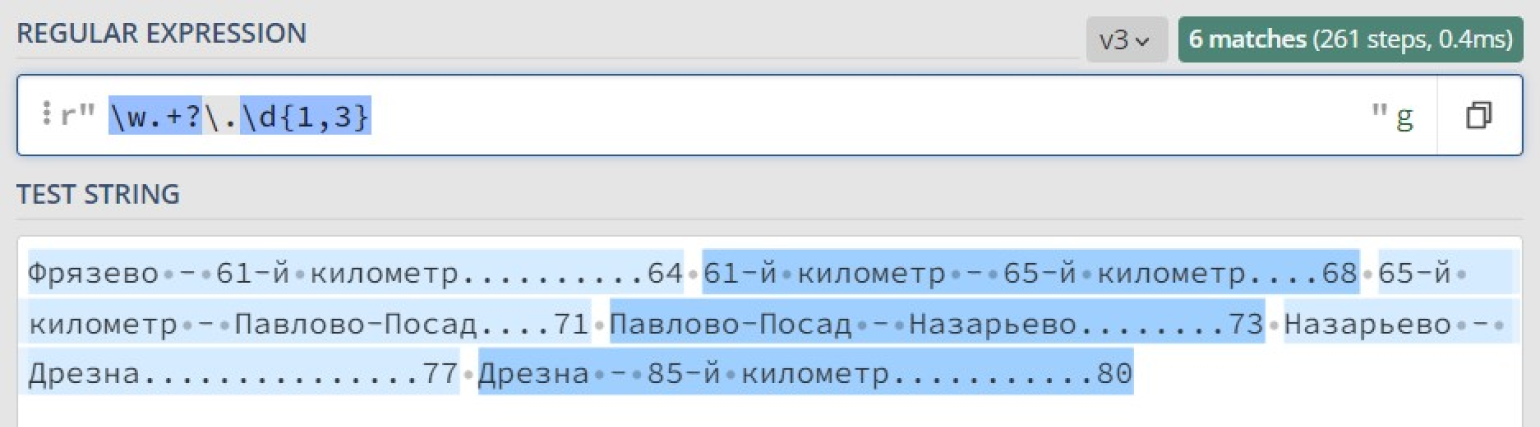
Теперь, когда мы уверены в правильности работы нашего регулярного выражения, используем функцию re.findall, чтобы выписать оглавление построчно:
Задача 3. Метод Довлатова
Писатели в поиске собственного неповторимого стиля нередко изобретают оригинальные творческие приёмы и неукоснительно им следуют. Например, Сергей Довлатов следил за тем, чтобы слова в предложении не начинались с одной и той же буквы.
Даны несколько предложений. Программа должна проверить, встречаются ли в каждом из них слова на одинаковую букву. Если таких нет, она печатает: «Метод Довлатова соблюдён». А если есть: «Вы расстроили Сергея Донатовича».
Важно. Чтобы регулярные выражения не рассматривали заглавные и прописные буквы как разные символы, передайте re-функции дополнительный аргумент flags=re.I или flags=re.IGNORECASE.
Ввод
Здесь все слова начинаются с разных букв.
А в этом предложении есть слова, которые всё-таки начинаются на одну и ту же букву.
А здесь совсем интересно: символ «а» однобуквенный.
Вывод
Вы расстроили Сергея Донатовича
Вы расстроили Сергея Донатовича
Чтобы указать на начало слова, используйте символ \b.
Чтобы в каждом совпадении regex не старалось захватить максимум, используйте ленивый пропуск.
Чтобы найти повторяющийся символ, используйте ссылку на группу в виде \1.
Читайте также:
Python and regular expressions example

Этот код вернет None , несмотря на то, что в строке есть 5 фрагментов «ку». Это происходит потому, что оба фрагмента расположены не в начале строки.
re.search() – находит первое вхождение фрагмента в любом месте и возвращает объект match. Если в строке есть другие фрагменты, соответствующие запросу, re.search их проигнорирует. У re.search есть дополнительные методы:
.span() – возвращает кортеж, содержащий начальную и конечную позиции искомого фрагмента.
.string – вернет строку, переданную в функцию re.search.
.group() – возвращает фрагмент строки, в котором было обнаружено совпадение.
![<i></noscript></p><p>Конструктор Regex</i>»/></p><h2>Примеры использования регулярных выражений в Python</h2><p>Написать регулярное выражение для извлечения из текста всех email-адресов.</p><pre><code>import re s = 'По всем вопросам пишите на vasiliy-pupkin@gmail.com, или на secondemail@yandex.ru, отвечу сразу. Или пишите моему ассистенту secretary@gmail.com!' emails = re.findall(r'[\w\.-]+@[\w\.-]+', s) for email in emails: print(email)</code> </pre><p>Имеется файл <b>transactions.txt</b>, в котором даты указаны в формате <b>MM/DD/YYYY</b>, при этом в некоторых случаях месяц обозначен первыми тремя буквами: <b>NOV</b>, <b>dec</b>, <b>JAN</b>. Нужно привести даты к формату <b>MM-DD-YYYY</b>.</p><pre><code>#формат дат в файле transactions.txt nov/14/2021 dec/15/2021 12/16/2021 dec/17/2021 jan/03/2022 JAN/10/22</code> </pre><pre><code>import fileinput import re fn =](https://media.proglib.io/posts/2022/02/24/dddd229b2c6e7e87674b177e58743523.png)