- Scrapy — Простой скрапинг сайтов
- Обзор основ работы со Scrapy
- Скрапинг продуктов из интернет магазина на Python
- Оболочка Scrapy Shell в командной строке
- Извлечение данных с сайта через Scrapy
- Создаем Scrapy Spider
- Собираем данные с помощью Scrapy
- Задача
- Создание проекта
- Паук
- Элементы
- Поиск элементов на странице
- Запуск
Scrapy — Простой скрапинг сайтов
Scrapy является фреймворком, что прекрасно подойдет для скрапинга веб сайтов. Он без особых проблем справляется с самыми популярными случаями веб скрапинга, среди которых:
- Многопоточность;
- Веб-краулер для перехода от ссылке к ссылки;
- Извлечение данных;
- Проверка данных;
- Сохранение в другой формат/базу данных;
- Многое другое.
Главное отличие между Scrapy и другими популярными библиотеками, такими как Requests или BeautifulSoup, заключается в том, что он позволяет решать обычные задачи веб скрапинга при помощи самых элегантных методов.

К недостаткам Scrapy можно отнести и тот факт, что начать ему обучаться бывает довольно сложно. Но мы ведь для этого здесь и собрались
В данном руководстве мы создадим два веб скрапера. Один будет простым, его задачей станет извлечение данных со страницы продукта онлайн магазина. Второй будет несколько сложнее. Его назначением будет скрапинг целого каталога сайта онлайн магазина.
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
Обзор основ работы со Scrapy
Установить Scrapy можно через pip. Но будьте внимательны. В документации Scrapy настоятельно рекомендуется устанавливать его в специальной виртуальной среде во избежание конфликтов с пакетами вашей системы.
Я использую Virtualenv и Virtualenvwrapper :
После активации виртуальной среды, у вас в терминале должен изменится ввод команд. Например:
Теперь у вас изолированная среда разработки, можете установить в ней нужные пакеты:
Теперь можно создать cкрапи проект с помощью этой команды:
Это создаст все необходимые файлы для проекта:
Далее представлено краткое описание файлов и папок:
- items.py является моделью для извлеченных данных. Вы можете определить настраиваемую модель (например Product ), что унаследует класс Item .
- middlewares.py Middleware используется для изменения жизненного цикла запросов и ответов. Например, вы можете создать промежуточное программное обеспечение для ротации пользовательских агентов или использовать API вроде ScrapingBee вместо того, чтобы выполнять запросы самостоятельно.
- pipelines.py В скрапи, пайплайны, или конвейеры используются для обработки извлеченных данных, очистки HTML, проверки данных, их экспорта в пользовательский формат или сохранения в базе данных.
- /spiders является папкой, содержащей классы Spider . В Scrapy Spider являются классом, которые определяют, как должен быть проведен скрапинг сайта, в том числе по какой ссылке следовать и как извлечь данные для этих ссылок.
- scrapy.cfg является файлом конфигурации для изменения некоторых настроек.
Скрапинг продуктов из интернет магазина на Python
В данном примере будет проведен скрапинг одного продукта с фиктивного сайта онлайн магазина. Вот первый товар, скрапингом которого мы займемся:
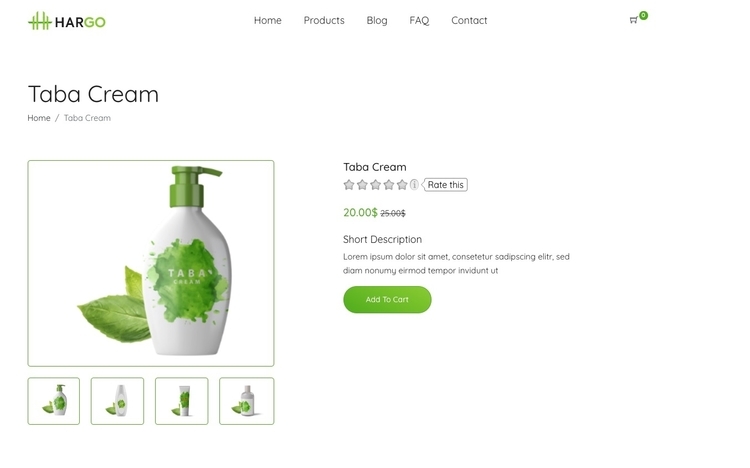
Мы извлечем название продукта, изображение, цену и описание.
Оболочка Scrapy Shell в командной строке
Scrapy поставляется со встроенной оболочкой, что помогает отладить код скрапинга в режиме реального времени. С ним можно быстро протестировать XPath-выражения или CSS селекторы. Это очень крутой инструмент для написания веб скраперов, и я всегда им пользуюсь!
Можно настроить Scrapy Shell на использование другой консоли вместо стандартной консоли Python как IPython. У вас появится возможность автозаполнения и другие приятные бонусы вроде цветного вывода.
Для его использования в оболочке Scrapy Shell нужно добавить следующую строку в файл scrapy.cfg :
После завершения конфигурации можно использовать оболочку Scrapy:
[ s ] fetch ( url [ , redirect = True ] ) Fetch URL and update local objects ( by default , redirects are followed )Можно начать выборку URL следующим простым действием:
Она начнется с загрузки файла /robot.txt
В данном случае нет никакого robot.txt , поэтому мы получаем 404 HTTP код. Если бы у нас был файл robot.txt , по умолчанию Scrapy придерживался бы правил.
Можно отключить такое поведение, изменив boolean параметр в settings.py :
После этого у вас должен появится лог подобного рода:
Теперь можно увидеть объект ответа, заголовки ответа и попробовать различные XPath выражения и CSS селекторы, чтобы извлечь нужные данные.
Увидеть ответ прямо в браузере, можно использовав данную функцию:
Обратите внимание, что страница будет плохо отображаться в браузере по многим причинам. Это могут быть проблемы с CORS, не выполненный Javascript код или относительные URL для ресурсов, которые не будут работать локально.
Оболочка Scrapy похожа на обычную оболочку Python, поэтому не бойтесь загружать в нее свои любимые скрипты или функции.
Извлечение данных с сайта через Scrapy
Scrapy по умолчанию не выполняет Javascript код. По этой причине при попытке сделать скрапинг на сайте, что использует Javascript-фреймворки вроде Angular или React.js, у вас могут возникнуть проблемы с получением доступа к запрашиваемым данным.
Попробуем использовать некоторые XPath выражения для извлечения названия и цены продукта:
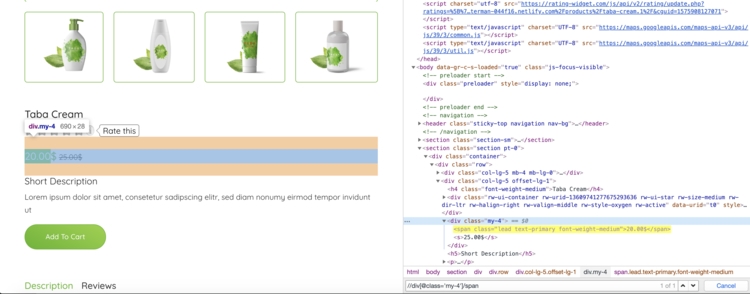
Для извлечения цены мы используем выражение XPath, выберем первый span после div с классом my-4
Я мог также использовать следующий CSS селектор:
Создаем Scrapy Spider
В Scrapy, Spider является классом, где определяется поведение при анализе (какие ссылки или URL должны пройти через скрапинг) и при скрапинге (что нужно извлечь).
Предусмотрено несколько этапов, которые Spider использует для скрапинга вебсайта:
- Все начинается с просмотра атрибута класса start_urls и вызова этих URL-адресов с помощью метода start_requests() . Вы можете переопределить этот метод, если нужно изменить HTTP verb, добавить некоторые параметры в запрос (например, отправив запрос POST вместо GET ).
- Затем генерируется объект Request для каждого URL и отправляется ответ в функцию обратного вызова parse() .
- Затем метод parse() извлекает данные (в нашем случае — цену продукта, изображение, описание, заголовок) и возвращает либо словарь, объект Item, запрос или итерацию.
Может показаться удивительным, что метод parse может возвращать так много разных объектов. Это сделано для гибкости. Допустим, вы хотите сделать скрапинг онлайн магазина, на котором нет карты сайта. Вы можете начать со скрапинга товарных категорий, это будет первый метод парсинга.
Данный метод затем передает объект Request для каждой категории продуктов новому методу обратного вызова parse2() . Для каждой категории нужно обрабатывать нумерацию страниц. Затем для каждого продукта производится фактический скрапинг, что генерирует элемент и третью функцию parse .
С Scrapy можно возвращать данные скрапинга в виде простого словаря Python, но рекомендуется использовать встроенный класс Scrapy Item . Это простой контейнер для данных скрапинга. Scrapy будет просматривать его поля для экспорта данных в различные форматы (JSON / CSV…), источника элемента и многого другого.
Далее показан базовый класс Product :
Собираем данные с помощью Scrapy

Без проблем установил из репозитариев Ubuntu. На странице Installation guide описывается установка в других дистрибутивах Linux, а так же в Mac OS X и Windows.
Задача
Наверное, кому-то захочется распарсить интернет-магазин и стянуть оттуда весь каталог с описаниями товара и фотографиями, но я намеренно не стану этого делать. Возьмем лучше какие-нибудь открытые данные, к примеру, список учебных заведений. Сайт является достаточно типовым и на нем можно показать несколько приемов.
Прежде чем писать паука, надо осмотреть сайт-источник. Заметим, сайт построен на фреймах (?!), во фреймсете ищем фрейм со стартовой страницей. Здесь присутствует форма поиска. Пусть нам нужны только вузы Москвы, поэтому заполняем соответствующее поле, жмем «Найти».
Анализируем. У нас есть страница с ссылками пагинации, 15 вузов на страницу. Параметры фильтра передаются через GET, меняются лишь значение page.
- Перейти на страницу abitur.nica.ru/new/www/search.php?region=77&town=0&opf=0&type=0&spec=0&ed_level=0&ed_form=0&qualif=&substr=&page=1
- Пройтись по каждой странице с результатами, меняя значение page
- Перейти в описание вуза abitur.nica.ru/new/www/vuz_detail.php?code=486®ion=77&town=0&opf=0&type=0&spec=0&ed_level=0&ed_form=0&qualif=&substr=&page=1
- Сохранить детальное описание вуза в CSV-файле
Создание проекта
Переходим в папку, где будет располагаться наш проект, создаем его:
scrapy startproject abitur cd abiturВ папке abitur нашего проекта находятся файлы:
- items.py содержит классы, которые перечисляют поля собираемых данных,
- pipelines.py позволяет задать определенные действия при открытии/закрытии паука, сохранения данных,
- settings.py содержит пользовательские настройки паука,
- spiders — папка, в которой хранятся файлы с классами пауков. Каждого паука принято писать в отдельном файле с именем name_spider.py.
Паук
В созданном файле spiders/abitur_spider.py описываем нашего паука
class AbiturSpider(CrawlSpider): name = "abitur" allowed_domains = ["abitur.nica.ru"] start_urls = ["http://abitur.nica.ru/new/www/search.php?region=77&town=0&opf=0&type=0&spec=0&ed_level=0&ed_form=0&qualif=&substr=&page=1"] rules = ( Rule(SgmlLinkExtractor(allow=('search\.php\?.+')), follow=True), Rule(SgmlLinkExtractor(allow=('vuz_detail\.php\?.+')), callback='parse_item'), ) ". "Наш класс наследуется от CrawlSpider, что позволит нам прописать шаблоны ссылок, которые паук будет сам извлекать и переходить по ним.
- name — имя паука, используется для запуска,
- allowed_domains — домены сайта, за пределами которого пауку искать ничего не следует,
- start_urls — список начальных адресов,
- rules — список правил для извлечения ссылок.
Как вы заметили, среди правил параметром передается callback функция. Мы к ней скоро вернемся.
Элементы
Как я уже говорил, в items.py содержится классы, которые перечисляют поля собираемых данных.
Это можно сделать так:
class AbiturItem(Item): name = Field() state = Field() ". "Распарсенные данные можно обработать перед экспортом. К примеру, учебное заведение может быть «государственное» и «негосударственное», а мы хотим хранить это значение в булевом формате или дату «1 января 2011» записать как «01.01.2011».
Для этого существуют входные и выходные обработчики, поэтому поле state запишем по-другому:
class AbiturItem(Item): name = Field() state = Field(input_processor=MapCompose(lambda s: not re.match(u'\s*не', s))) ". "MapCompose применяется к каждому элементу списка state.
Поиск элементов на странице
Возвращаемся к нашему методу parse_item.
Для каждого элемента Item можно использовать свой загрузчик. Его назначение тоже связано с обработкой данных.
class AbiturLoader(XPathItemLoader): default_input_processor = MapCompose(lambda s: re.sub('\s+', ' ', s.strip())) default_output_processor = TakeFirst() class AbiturSpider(CrawlSpider): ". " def parse_item(self, response): hxs = HtmlXPathSelector(response) l = AbiturLoader(AbiturItem(), hxs) l.add_xpath('name', '//td[@id="content"]/h1/text()') l.add_xpath('state', '//td[@id="content"]/div/span[@class="gray"]/text()') ". " return l.load_item()В нашем случае из каждого поля удаляются крайние и дублирующиеся пробелы. В загрузчик также можно добавить индивидуальные правила, что мы делали в классе AbiturItem:
class AbiturLoader(XPathItemLoader): ". " state_in = MapCompose(lambda s: not re.match(u'\s*не', s))Так что, поступайте как вам удобнее.
Функция parse_item() возвращает объект Item, который передается в Pipeline (описываются в pipelines.py). Там можно написать свои классы для сохранения данных в форматах, не предусмотренных стандартным функционалом Scrapy. Например, экспортировать в mongodb.
Поля этого элемента задаются с помощью XPath, о котором можно прочитать здесь или здесь. Если вы используйте FirePath, обратите внимание, что он добавляет тег tbody внутрь таблицы. Для проверки путей XPath используйте встроенную консоль.
И еще одно замечание. Когда вы используете XPath, найденные результаты возвращаются в виде списка, поэтому удобно подключать выходной процессор TakeFirst, который берет первый элемент этого списка.
Запуск
Исходный код можно взять тут, для запуска перейдите в папку с проектом и наберите в консоли
scrapy crawl abitur --set FEED_URI=scraped_data.csv --set FEED_FORMAT=csv- поиск и извлечение данных их HTML и XML
- преобразование данных перед экспортом
- экспорт в форматы JSON, CSV, XML
- скачивание файлов
- расширение фреймворка собственными middlewares, pipelines
- выполнение POST запросов, поддержка куков и сессий, аутентификации
- подмена user-agent
- shell консоль для отладки
- система логирования
- мониторинг через Web-интерфейс
- управление через Telnet-консоль
Описать все все одной статье невозможно, поэтому задавайте вопросы в комментариях, читайте документацию, предлагайте темы для будущих статей о Scrapy.
Рабочий пример выложил на GitHub.