pm4py 2.7.5
# pm4py pm4py is a python library that supports (state-of-the-art) process mining algorithms in python. It is open source (licensed under GPL) and intended to be used in both academia and industry projects. pm4py is a product of the Fraunhofer Institute for Applied Information Technology.
## Documentation / API The full documentation of pm4py can be found at http://pm4py.org/
## First Example A very simple example, to whet your appetite:
log = pm4py.read_xes(‘’) net, initial_marking, final_marking = pm4py.discover_petri_net_inductive(log) pm4py.view_petri_net(net, initial_marking, final_marking, format=”svg”)
## Installation pm4py can be installed on Python 3.8.x / 3.9.x / 3.10.x / 3.11.x by invoking: pip install -U pm4py
## Requirements pm4py depends on some other Python packages, with different levels of importance: * Essential requirements: numpy, pandas, deprecation, networkx * Normal requirements (installed by default with the pm4py package, important for mainstream usage): graphviz, intervaltree, lxml, matplotlib, pydotplus, pytz, scipy, stringdist, tqdm * Optional requirements (not installed by default): scikit-learn, pyemd, pyvis, jsonschema, polars, openai, pywin32, python-dateutil, requests, workalendar
## Release Notes To track the incremental updates, please refer to the CHANGELOG file.
## Third Party Dependencies As scientific library in the Python ecosystem, we rely on external libraries to offer our features. In the /third_party folder, we list all the licenses of our direct dependencies. Please check the /third_party/LICENSES_TRANSITIVE file to get a full list of all transitive dependencies and the corresponding license.
## Citing pm4py If you are using pm4py in your scientific work, please cite pm4py as follows:
Process Mining без PM4PY

Построить граф по логам процесса очень просто. В распоряжении аналитиков в настоящее время достаточное многообразие профессиональных разработок, таких как Celonis, Disco, PM4PY, ProM и т.д., призванных облегчить исследование процессов. Намного сложнее найти отклонения на графах, сделать верные выводы по ним.
Что делать, если некоторые профессиональные разработки, зарекомендовавшие себя и представляющие особый интерес не доступны по тем или иным причинам, или вам хочется больше свободы в расчетах при работе с графами? Насколько сложно самим написать майнер и реализовать некоторые необходимые возможности для работы с графами? Сделаем это на практике с помощью стандартных библиотек Python, реализуем расчеты и дадим с их помощью ответы на детальные вопросы, которые могли бы заинтересовать владельцев процесса.
Сразу хочется оговориться, что решение, приведенное в статье, не является промышленной реализацией. Это некоторая попытка начать работать с логами самостоятельно с помощью простого кода, который понятно работает, а значит, позволяет легко его адаптировать. Это решение не стоит использовать на больших данных, для этого требуется существенная его доработка, например, с применением векторных вычислений или путем изменения подхода к сбору и агрегации информации о событиях.
Перед построением графа, необходимо выполнить расчеты. Собственно расчет графа и будет тем самым майнером, о котором говорилось ранее. Для выполнения расчета необходимо собрать знания о событиях — вершинах графа и связях между ними и записать их, например в справочники. Заполняются справочники с помощью процедуры расчета calc (код на github). Заполненные справочники передаются в качестве параметров процедуре отрисовки графов draw (см. код по ссылке выше). Эта процедура форматирует данные, в представленный ниже вид:
digraph f "Permit APPROVED by ADMINISTRATION (4839)" [label=4829 color=black penwidth=4.723857205400346] "Permit SUBMITTED by EMPLOYEE (6255)" -> "Permit REJECTED by ADMINISTRATION (83)" [label=83 color=pink2 penwidth=2.9590780923760738] "Permit SUBMITTED by EMPLOYEE (6255)" -> "Permit REJECTED by EMPLOYEE (231)" [label=2 color=pink2 penwidth=1.3410299956639813] … start [color=blue shape=diamond] end [color=blue shape=diamond]>и передает его для отрисовки графическому движку Graphviz.
Приступим к построению и исследованию графов с помощью реализованного майнера. Будем повторять процедуры чтения и сортировки данных, расчета и отрисовки графов, как в приведенных ниже примерах. Для примеров взяты логи событий по международным декларациям из соревнования BPIC2020. Ссылка на соревнование.
Считаем данные из лога, отсортируем их по дате и времени. Предварительно формат .xes преобразован в .xlsx.
df_full = pd.read_excel('InternationalDeclarations.xlsx') df_full = df_full[['id-trace','concept:name','time:timestamp']] df_full.columns = ['case:concept:name', 'concept:name', 'time:timestamp'] df_full['time:timestamp'] = pd.to_datetime(df_full['time:timestamp']) df_full = df_full.sort_values(['case:concept:name','time:timestamp'], ascending=[True,True]) df_full = df_full.reset_index(drop=True)dict_tuple_full = calc(df_full)draw(dict_tuple_full,'InternationalDeclarations_full')После выполнения процедур получим граф процесса:

Так как полученный граф не читаем, упростим его.
Есть несколько подходов к улучшению читаемости или упрощению графа:
- использовать фильтрацию по весам вершин или связей;
- избавиться от шума;
- сгруппировать события по схожести названия.
Создадим словарь объединения событий:
Выполним группировку событий и отрисуем граф процесса еще раз.
df_full_gr = df_full.copy() df_full_gr['concept:name'] = df_full_gr['concept:name'].map(_dict) dict_tuple_full_gr = calc(df_full_gr) draw(dict_tuple_full_gr,'InternationalDeclarations_full_gr'
После группировки событий по схожести названия читаемость графа улучшилась. Попробуем найти ответы на вопросы. Ссылка на список вопросов. Например, скольким декларациям не предшествовало предодобренное разрешение?
Для ответа на поставленный вопрос отфильтруем граф по интересующим событиям и отрисуем граф процесса еще раз.
df_full_gr_f = df_full_gr[df_full_gr['concept:name'].isin(['Permit SUBMITTED', 'Permit APPROVED', 'Permit FINAL_APPROVED', 'Declaration FINAL_APPROVED', 'Declaration APPROVED'])] df_full_gr_f = df_full_gr_f.reset_index(drop=True) dict_tuple_full_gr_f = calc(df_full_gr_f) draw(dict_tuple_full_gr_f,'InternationalDeclarations_full_gr_isin')
С помощью полученного графа мы легко сможем дать ответ на поставленный вопрос – 116 и 312 декларациям не предшествовало предодобренное разрешение.
Можно дополнительно “провалиться” (отфильтровать по ‘case:concept:name’, участвующих в нужной связи) за связи 116 и 312 и убедиться, что на графах будут отсутствовать события, связанные с разрешениями.
df_116 = df_full_gr_f[df_full_gr_f['case:concept:name'].isin(d_case_start2['Declaration FINAL_APPROVED'])] df_116 = df_116.reset_index(drop=True) dict_tuple_116 = calc(df_116) draw(dict_tuple_116,'InternationalDeclarations_full_gr_isin_116')
df_312 = df_full_gr_f[df_full_gr_f['case:concept:name'].isin(d_case_start2['Declaration APPROVED'])] df_312 = df_312.reset_index(drop=True) dict_tuple_312 = calc(df_312) draw(dict_tuple_312,'InternationalDeclarations_full_gr_isin_312')
Так как на полученных графах полностью отсутствуют события, связанные с разрешениями, корректность ответов 116 и 312 подтверждается.
Как видим, написать майнер и реализовать необходимые возможности для работы с графами не сложная задача, с которой успешно справились встроенные функции Python и Graphviz в качестве графического движка.
Под капотом Process Mining: графовая аналитика для анализа бизнес-процессов

Сегодня рассмотрим тему анализа и оптимизации бизнес-процессов средствами графовой аналитики больших данных. Как устроены информационные системы класса Process Mining, где еще применяются эти идеи и другие приложения теории графов в бизнесе на примере Python-библиотеки PM4Py.
Что такое Process Mining
Чтобы понять, как выполняется процесс, бизнес-аналитик строит его схему в виде подробной EPC или BPMN-диаграммы, которая представляет собой направленный граф действий с логическими операторами. Именно эта идея – представления графа событий пользовательского поведения по логам информационных систем лежит в основе процессной аналитики (Process Mining, PM). Помимо анализа логов и прикладных информационных систем типа СЭД, ERP, CRM и пр., решения Process Mining также включают некоторые возможности BI-продуктов, например, визуализация выявленных трендов в данных и формирование рекомендаций.
В отличие от Data Mining, PM-системы сфокусированы не на семантических взаимосвязях данных, а на представлении их в виде процессов. На вход подаются транзакционные данные по объектам управленческого учета: заданиям, заказам, заявкам и пр. Примечательно, что процессная аналитика использует данные для анализа бизнес-процессов без классического анализ самих данных. Process Mining не ищет низкоуровневые закономерности в исходных данных и не пытается вырабатывать управленческие решения на их основе, а пытается определить оптимальный путь выполнения процесса по событиям пользовательского поведения, используя методы выборки данных для построения модели процесса по наиболее представительным сценариям в бизнес-процессе. Определяются связи между шагами процесса, отклонения от «успешного сценария», причины этих отклонений и их влияние на результат, а также анализируется эффективность процесса и выявляются его узкие места.
Примерами PM-систем являются Proceset, Minit, ARIS Process Performance Manager, ProM, Celonis Process Mining. Также Data Analyst может самостоятельно реализовать некоторые идеи процессной аналитики, используя специализированные библиотеки. Например, PM4Py – Python-пакет интеллектуального анализа процессов. Как она работает в Google Colab, мы рассмотрим далее.
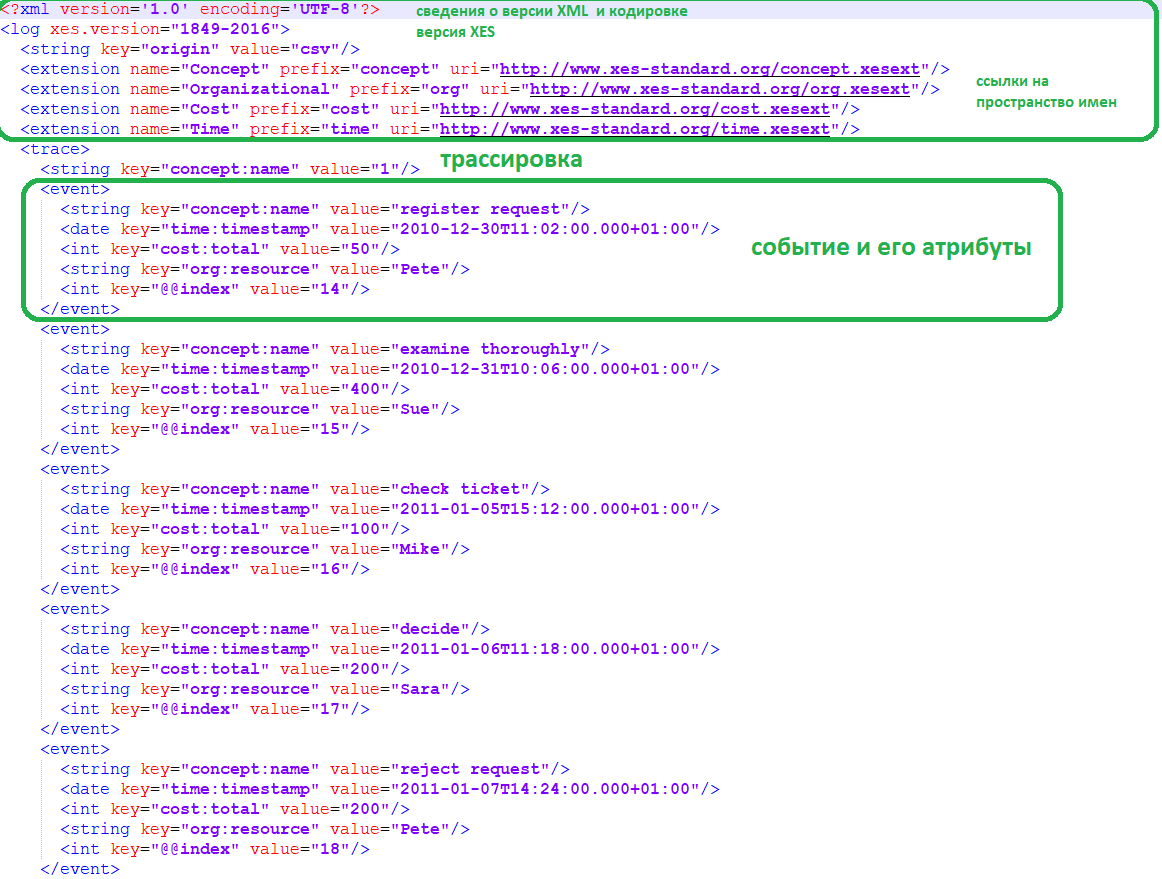
На вход в PM-систему подается лог событий пользовательского поведения, который содержит как минимум идентификатор сессии, дату и время события, а также его название. Рассмотрим пример журнала событий обработки жалоб клиентов. Данные о событиях могут храниться в CSV-файлах, так и в XML-подобном формате XES. В отличие от CSV, в файле XES можно описать отношение вмещения, т. е. включить ряд трассировок, которые содержат несколько событий. Также сам объект в XES, т. е. лог, трассировка или событие, может иметь атрибуты. Таким образом, определенные атрибуты данных, которые являются постоянными для журнала или трассировки, могут храниться на этом уровне.
Предположим, известна только общая стоимость дела, а не стоимость отдельных событий. Если сохранять эту информацию в CSV-файле, нужно реплицировать эту информацию, т. е. хранить данные только в строках, которые напрямую относятся к событиям или явно определить, что определенные столбцы получают только значение один раз, ссылаясь на атрибуты уровня конкретного случая. Стандарт XES более естественно поддерживает хранение такого типа информации.
В рассматриваемом примере XES-файл содержит данные о событиях пользовательского поведения. Например, трассировка с номером 1, маркированная тегом , является первой трассировкой, записанной в этот журнал событий. Первое событие трассировки представляет действие «запрос на регистрацию» (register request), выполненное ресурсом Pete. Второе событие — это действие «тщательно изучить» (examine thoroughly), выполняемое Sue и т.д.
Как работать с этим файлом пользовательских событий, чтобы получить схему бизнес-процесса с помощью библиотеки PM4Py, рассмотрим далее.