htmlentities
Эта функция идентична htmlspecialchars() за исключением того, что htmlentities() преобразует все символы в соответствующие HTML-сущности (для тех символов, для которых HTML-сущности существуют). Функция get_html_translation_table() может быть использована для возврата используемой таблицы перевода в зависимости от предоставленных констант в параметре flags .
Если же вы хотите раскодировать строку (наоборот), используйте html_entity_decode() .
Список параметров
Битовая маска из нижеуказанных флагов, определяющих режим обработки кавычек, некорректных кодовых последовательностей и используемый тип документа. По умолчанию используется ENT_QUOTES | ENT_SUBSTITUTE | ENT_HTML401 .
| Название константы | Описание |
|---|---|
| ENT_COMPAT | Преобразует двойные кавычки, одинарные кавычки не изменяются. |
| ENT_QUOTES | Преобразует как двойные, так и одинарные кавычки. |
| ENT_NOQUOTES | Оставляет без изменения как двойные, так и одинарные кавычки. |
| ENT_IGNORE | Молча отбрасывает некорректные кодовые последовательности вместо возврата пустой строки. Использование этого флага не рекомендуется, так как это » может внести уязвимости в ваш код. |
| ENT_SUBSTITUTE | Заменяет некорректные кодовые последовательности символом замены Юникода U+FFFD в случае использования UTF-8 и &#FFFD; при использовании другой кодировки, вместо возврата пустой строки. |
| ENT_DISALLOWED | Заменяет неверные коды символов для заданного типа документа символом замены юникода U+FFFD (UTF-8) или &#FFFD; (при использовании другой кодировки) вместо того, чтобы оставлять все как есть. Это может быть полезно, например, для того, чтобы убедиться в формальной правильности XML-документов со встроенным внешним контентом. |
| ENT_HTML401 | Обработка кода в соответствии с HTML 4.01. |
| ENT_XML1 | Обработка кода в соответствии с XML 1. |
| ENT_XHTML | Обработка кода в соответствии с XHTML. |
| ENT_HTML5 | Обработка кода в соответствии с HTML 5. |
Необязательный аргумент, определяющий кодировку, используемую при конвертации символов.
Если не указан, то значение по умолчанию для encoding зависит от конфигурационной опции default_charset.
Хотя этот аргумент является технически необязательным, настоятельно рекомендуется указать правильное значение для вашего кода, опция конфигурации default_charset может быть задана неверно для входных данных.
Поддерживаются следующие кодировки:
| Кодировка | Псевдонимы | Описание |
|---|---|---|
| ISO-8859-1 | ISO8859-1 | Западно-европейская Latin-1. |
| ISO-8859-5 | ISO8859-5 | Редко используемая кириллическая кодировка (Latin/Cyrillic). |
| ISO-8859-15 | ISO8859-15 | Западно-европейская Latin-9. Добавляет знак евро, французские и финские буквы к кодировке Latin-1 (ISO-8859-1). |
| UTF-8 | 8-битная Unicode, совместимая с ASCII. | |
| cp866 | ibm866, 866 | Кириллическая кодировка, применяемая в DOS. |
| cp1251 | Windows-1251, win-1251, 1251 | Кириллическая кодировка, применяемая в Windows. |
| cp1252 | Windows-1252, 1252 | Западно-европейская кодировка, применяемая в Windows. |
| KOI8-R | koi8-ru, koi8r | Русская кодировка. |
| BIG5 | 950 | Традиционный китайский, применяется в основном на Тайване. |
| GB2312 | 936 | Упрощённый китайский, стандартная национальная кодировка. |
| BIG5-HKSCS | Расширенная Big5, применяемая в Гонконге. | |
| Shift_JIS | SJIS, SJIS-win, cp932, 932 | Японская кодировка. |
| EUC-JP | EUCJP, eucJP-win | Японская кодировка. |
| MacRoman | Кодировка, используемая в Mac OS. | |
| » | Пустая строка активирует режим определения кодировки из файла скрипта (Zend multibyte), default_charset и текущей локали (смотрите nl_langinfo() и setlocale() ) в указанном порядке. Не рекомендуется к использованию. |
Замечание: Остальные кодировки не поддерживаются, вместо них будет применена кодировка по умолчанию и сгенерировано предупреждение.
При выключении параметра double_encode , PHP не будет преобразовывать существующие html-сущности. По умолчанию преобразуется все без ограничений.
Возвращаемые значения
Возвращает преобразованную строку.
При наличии во входном параметре string недопустимой последовательности символов в заданной кодировке encoding , будет возвращена пустая строка, если не установлены флаги ENT_IGNORE или ENT_SUBSTITUTE .
Список изменений
| Версия | Описание |
|---|---|
| 8.1.0 | Значение по умолчанию параметра flags изменено с ENT_COMPAT на ENT_QUOTES | ENT_SUBSTITUTE | ENT_HTML401 . |
| 8.0.0 | encoding теперь допускает значение null. |
Примеры
Пример #1 Пример использования htmlentities()
// выводит: A ‘quote’ is <b>bold</b>
echo htmlentities ( $str );
// выводит: A 'quote' is <b>bold</b>
echo htmlentities ( $str , ENT_QUOTES );
?>
Пример #2 Использование ENT_IGNORE
// Выводит пустую строку
echo htmlentities ( $str , ENT_QUOTES , «UTF-8» );
// Выводит «. »
echo htmlentities ( $str , ENT_QUOTES | ENT_IGNORE , «UTF-8» );
?>
Смотрите также
- html_entity_decode() — Преобразует HTML-сущности в соответствующие им символы
- get_html_translation_table() — Возвращает таблицу преобразований, используемую функциями htmlspecialchars и htmlentities
- htmlspecialchars() — Преобразует специальные символы в HTML-сущности
- nl2br() — Вставляет HTML-код разрыва строки перед каждым переводом строки
- urlencode() — URL-кодирование строки
User Contributed Notes 22 notes
An important note below about using this function to secure your application against Cross Site Scripting (XSS) vulnerabilities.
When printing user input in an attribute of an HTML tag, the default configuration of htmlEntities() doesn’t protect you against XSS, when using single quotes to define the border of the tag’s attribute-value. XSS is then possible by injecting a single quote:
$_GET [ ‘a’ ] = «#000′ onload=’alert(document.cookie)» ;
?>
XSS possible (insecure):
$href = htmlEntities ( $_GET [ ‘a’ ]);
print «» ; # results in:
?>
Use the ‘ENT_QUOTES’ quote style option, to ensure no XSS is possible and your application is secure:
$href = htmlEntities ( $_GET [ ‘a’ ], ENT_QUOTES );
print «» ; # results in:
?>
The ‘ENT_QUOTES’ option doesn’t protect you against javascript evaluation in certain tag’s attributes, like the ‘href’ attribute of the ‘a’ tag. When clicked on the link below, the given JavaScript will get executed:
I’ve seen lots of functions to convert all the entities, but I needed to do a fulltext search in a db field that had named entities instead of numeric entities (edited by tinymce), so I searched the tinymce source and found a string with the value->entity mapping. So, i wrote the following function to encode the user’s query with named entities.
The string I used is different of the original, because i didn’t want to convert ‘ or «. The string is too long, so I had to cut it. To get the original check TinyMCE source and search for nbsp or other entity 😉
$entities_unmatched = explode ( ‘,’ , ‘160,nbsp,161,iexcl,162,cent, [. ] ‘ );
$even = 1 ;
foreach( $entities_unmatched as $c ) if( $even ) $ord = $c ;
> else $entities_table [ $ord ] = $c ;
>
$even = 1 — $even ;
>
function encode_named_entities ( $str ) global $entities_table ;
$encoded_str = » ;
for( $i = 0 ; $i < strlen ( $str ); $i ++) $ent = @ $entities_table [ ord ( $str < $i >)];
if( $ent ) $encoded_str .= «& $ent ;» ;
> else $encoded_str .= $str < $i >;
>
>
return $encoded_str ;
>
If you are building a loadvars page for Flash and have problems with special chars such as » & «, » ‘ » etc, you should escape them for flash:
Try trace(escape(«&»)); in flash’ actionscript to see the escape code for &;
function flashentities ( $string )<
return str_replace (array( «&» , «‘» ),array( «%26» , «%27» ), $string );
>
?>
Those are the two that concerned me. YMMV.
The flag ENT_HTML5 also strips newline chars like \n with htmlentities while htmlspecialchars is not affected by that.
If you want to use nl2br on that string afterwards you might end up searching the problem like i did. This does not apply to other flags like e.g. ENT_XHTML which confused me.
Tested this with PHP 5.4 / 5.5 / 5.6-dev with same results, so it seems that this is an intended «feature».
For those Spanish (and not only) folks, that want their national letters back after htmlentities 🙂
protected function _decodeAccented ( $encodedValue , $options = array()) $options += array(
‘quote’ => ENT_NOQUOTES ,
‘encoding’ => ‘UTF-8’ ,
);
return preg_replace_callback (
‘/&\w(acute|uml|tilde);/’ ,
create_function (
‘$m’ ,
‘return html_entity_decode($m[0], ‘ . $options [ ‘quote’ ] . ‘, «‘ .
$options [ ‘encoding’ ] . ‘»);’
),
$encodedValue
);
>
?>
The following will make a string completely safe for XML:
function philsXMLClean ( $strin ) $strout = null ;
Converting Strings into HTML
A commonly used web attack is called Cross-Site Scripting (XSS). For example, a user enters some malicious data, such as JavaScript code, into a web form; the web page then at some point outputs this information verbatim, without proper escaping. Standard examples for this are your blog’s comments section or discussion forms.

Escaping Strings for HTML
alert("I have a bad Föhnwelle. ");'; echo htmlspecialchars($input); /*Prints: <script>alert("I have a bad Föhnwelle. ");</script>*/ echo htmlentities($input); /*Prints: <script>alert("I have a bad Föhnwelle. ");</script>*/ Here, it is important to remove certain HTML markup. To make a long story short: It is almost impossible to really catch all attempts to inject JavaScript into data. It’s not only always done using the tag, but also in other HTML elements, such as . Therefore, in most cases, all HTML must be removed.
The easiest way to do so is to call htmlspecialchars() ; this converts the string into HTML, including the replacement of all < and >characters by < and > . Another option is to call htmlentities() . This uses HTML entities for characters, if available. The preceding code shows the differences between these two methods. The German ö (o umlaut) is not converted by htmlspecialchars() ; however, htmlentities() replaces it by its entity ö .
The use of htmlspecialchars() and htmlentities() just outputs what the user entered in the browser. So if the user entered HTML markup, this very markup is shown. So htmlspecialchars() and htmlentities() please the browser, but might not please the user.
If you, however, want to prepare strings to be used within URLs, you have to use urlencode() to properly encode special characters such as the space character that can be used in URLs.
Removing All HTML Tags
The function strip_tags() does completely get rid of all HTML elements. If you just want to keep some elements (for example, some limited formatting functionalities with and and
tags), you provide a list of allowed values in the second parameter for strip_tags() .
The following script shows this; the figure depicts its output. As you can see, all unwanted HTML tags have been removed; however, their contents are still there.
attack is called
Cross-Site Scripting XSS.
For example:
'; echo strip_tags($text, '
');
 '; echo strip_tags($text, '
'; echo strip_tags($text, '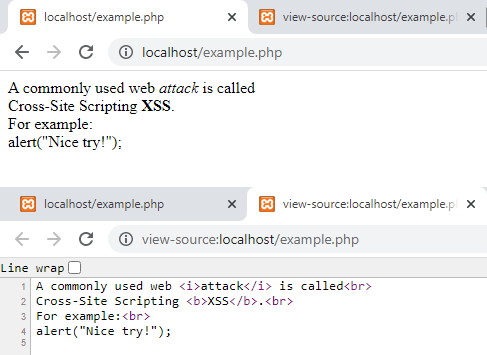
Working with Strings:
Text To HTML Converter (PHP 4+)
Join the DZone community and get the full member experience.
Simple function to convert a text into formatted HTML in PHP. The function implements some text cleanups (double space removal) and accepts some HTML in the text, like links (a href), lists (ul, ol), blockquotes and tables. This makes it perfect for use inside custom-made blogging engines and CMSs. There's also an implementation of case-insensitive search/replace for php < 5. $part ) < $parts[ $key ] = substr($string, $pos, strlen($part)); $pos += strlen($part) + strlen($find); >return( join( $replace, $parts ) ); > function txt2html($txt) < // Transforms txt in html //Kills double spaces and spaces inside tags. while( !( strpos($txt,' ') === FALSE ) ) $txt = str_replace(' ',' ',$txt); $txt = str_replace(' >','>',$txt); $txt = str_replace('< ','<',$txt); //Transforms accents in html entities. $txt = htmlentities($txt); //We need some HTML entities back! $txt = str_replace('"','"',$txt); $txt = str_replace('<','<',$txt); $txt = str_replace('>','>',$txt); $txt = str_replace('&','&',$txt); //Ajdusts links - anything starting with HTTP opens in a new window $txt = stri_replace("'.str_replace("$eol$eol","",$txt).'
'; $html = str_replace("$eol","
\n",$html); $html = str_replace("","\n\n",$html); $html = str_replace(" "," ",$html); //Wipes
after block tags (for when the user includes some html in the text). $wipebr = Array("table","tr","td","blockquote","ul","ol","li"); for($x = 0; $x < count($wipebr); $x++) < $tag = $wipebr[$x]; $html = stri_replace("
","",$html); $html = stri_replace("
","",$html); > return $html; > ?> Opinions expressed by DZone contributors are their own.