2. Installing Beautiful Soup¶
If you’re using a recent version of Debian or Ubuntu Linux, you can install Beautiful Soup with the system package manager:
Beautiful Soup 4 is published through PyPi, so if you can’t install it with the system packager, you can install it with easy_install or pip . The package name is beautifulsoup4 , and the same package works on Python 2 and Python 3.
$ pip install beautifulsoup4
(The BeautifulSoup package is probably not what you want. That’s the previous major release, Beautiful Soup 3. Lots of software uses BS3, so it’s still available, but if you’re writing new code you should install beautifulsoup4 .)
If you don’t have easy_install or pip installed, you can download the Beautiful Soup 4 source tarball and install it with setup.py .
If all else fails, the license for Beautiful Soup allows you to package the entire library with your application. You can download the tarball, copy its bs4 directory into your application’s codebase, and use Beautiful Soup without installing it at all.
I use Python 2.7 and Python 3.2 to develop Beautiful Soup, but it should work with other recent versions.
2.1. Problems after installation¶
Beautiful Soup is packaged as Python 2 code. When you install it for use with Python 3, it’s automatically converted to Python 3 code. If you don’t install the package, the code won’t be converted. There have also been reports on Windows machines of the wrong version being installed.
If you get the ImportError “No module named HTMLParser”, your problem is that you’re running the Python 2 version of the code under Python 3.
If you get the ImportError “No module named html.parser”, your problem is that you’re running the Python 3 version of the code under Python 2.
In both cases, your best bet is to completely remove the Beautiful Soup installation from your system (including any directory created when you unzipped the tarball) and try the installation again.
If you get the SyntaxError “Invalid syntax” on the line ROOT_TAG_NAME = u'[document]’ , you need to convert the Python 2 code to Python 3. You can do this either by installing the package:
or by manually running Python’s 2to3 conversion script on the bs4 directory:
2.2. Installing a parser¶
Beautiful Soup supports the HTML parser included in Python’s standard library, but it also supports a number of third-party Python parsers. One is the lxml parser. Depending on your setup, you might install lxml with one of these commands:
$ apt-get install python-lxml
Another alternative is the pure-Python html5lib parser, which parses HTML the way a web browser does. Depending on your setup, you might install html5lib with one of these commands:
$ apt-get install python-html5lib
This table summarizes the advantages and disadvantages of each parser library:
- Batteries included
- Decent speed
- Lenient (as of Python 2.7.3 and 3.2.)
- Not very lenient (before Python 2.7.3 or 3.2.2)
- Very fast
- Lenient
- External C dependency
- Very fast
- The only currently supported XML parser
- External C dependency
- Extremely lenient
- Parses pages the same way a web browser does
- Creates valid HTML5
- Very slow
- External Python dependency
If you can, I recommend you install and use lxml for speed. If you’re using a version of Python 2 earlier than 2.7.3, or a version of Python 3 earlier than 3.2.2, it’s essential that you install lxml or html5lib–Python’s built-in HTML parser is just not very good in older versions.
Note that if a document is invalid, different parsers will generate different Beautiful Soup trees for it. See Differences between parsers for details.
Облегчаем себе жизнь с помощью BeautifulSoup4
Приветствую всех. В этой статье мы сделаем жизнь чуточку легче, написав легкий парсер сайта на python, разберемся с возникшими проблемами и узнаем все муки пайтона что-то новое.
Статья ориентирована на новичков, таких же как и я.
Начало
Для начала разберем задачу. Взял я малоизвестный сайт новостей об Израиле, так как сам проживаю в этой стране, и хочется читать новости без рекламы и не интересных новостей. И так, имеется сайт, на котором постятся новости: есть новости помеченные красным, а есть обычные. Те что обычные — не представляют собой ничего интересного, а отмеченные красным являются самым соком. Рассмотрим наш сайт.
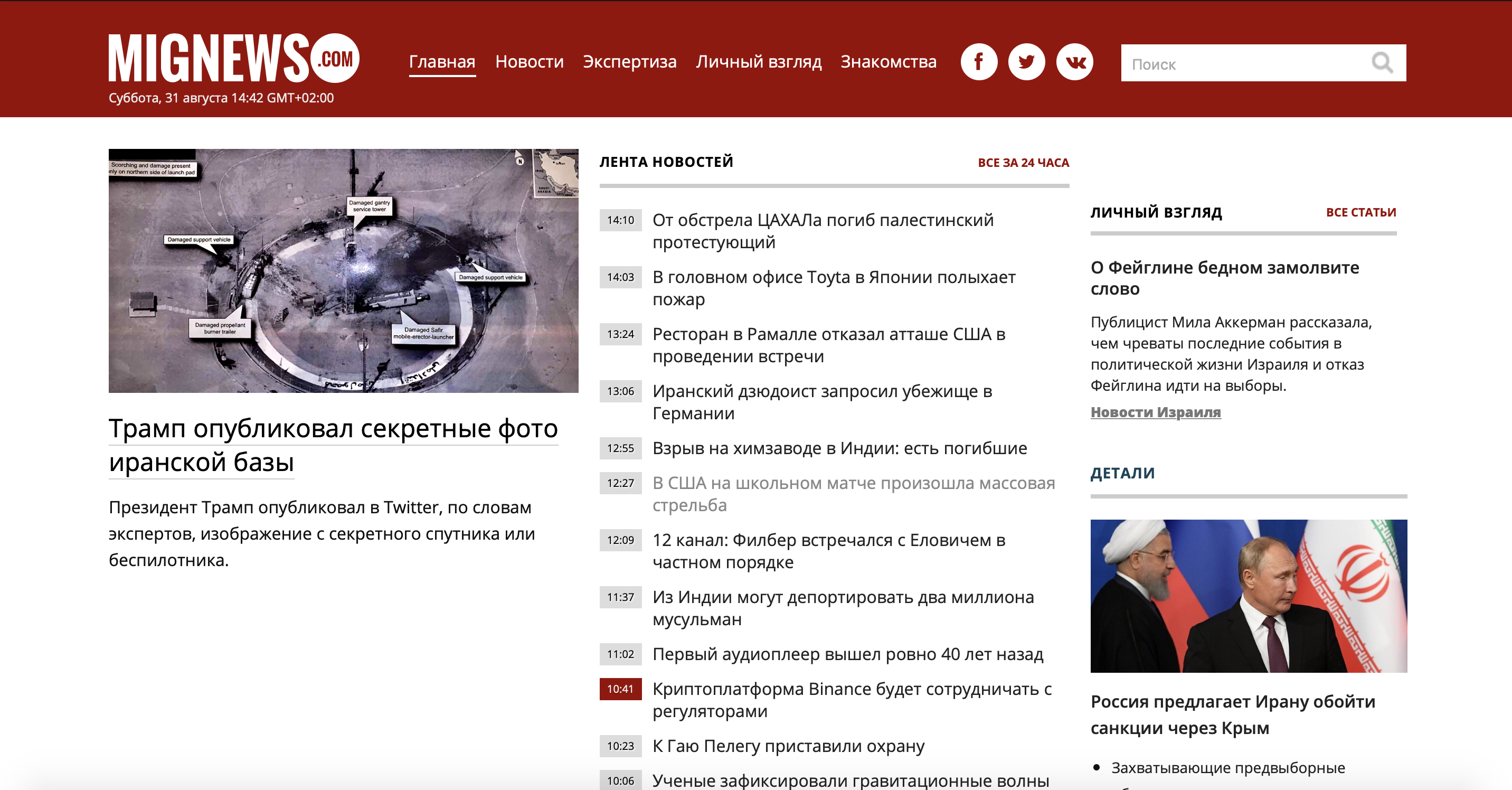
Как видно сайт достаточно большой и есть много ненужной информации, а ведь нам нужно использовать лишь контейнер новостей. Давайте использовать мобильную версию сайта,
чтобы сэкономить себе же время и силы.

Как видите, сервер отдал нам красивый контейнер новостей (которых, кстати, больше чем на основном сайте, что нам на руку) без рекламы и мусора.
Давайте рассмотрим исходный код, чтобы понять с чем мы имеем дело.

Как видим каждая новость лежит по-отдельности в тэге ‘a’ и имеет класс ‘lenta’. Если мы откроем тэг ‘a’, то заметим, что внутри есть тэг ‘span’, в котором находится класс ‘time2’, либо ‘time2 time3’, а также время публикации и после закрытия тэга мы наблюдаем сам текст новости.
Что отличает важную новость от неважной? Тот самый класс ‘time2’ или ‘time2 time3’. Новости помеченые ‘time2 time3’ и являются нашими красными новостями. Раз уж суть задачи понятна, перейдем к практике.
Практика
Для работы с парсерами умные люди придумали библиотеку «BeautifulSoup4», в которой есть еще очень много крутых и полезных функций, но об этом в следующий раз. Нам также понадобиться библиотека Requests позволяющая отправлять различные http-запросы. Идем их скачивать.
(убедитесь, что стоит последняя версия pip)
pip install beautifulsoup4 Переходим в редактор кода и импортируем наши библиотеки:
from bs4 import BeautifulSoup import requestsДля начала сохраним наш URL в переменную:
url = 'http://mignews.com/mobile'Теперь отправим GET()-запрос на сайт и сохраним полученное в переменную ‘page’:
Код вернул нам статус код ‘200’, значит это, что мы успешно подключены и все в полном порядке.
Теперь создадим два списка (позже я объясню для чего они нужны):
Самое время воспользоваться BeautifulSoup4 и скормить ему наш page, указав в кавычках как он нам поможет ‘html.parcer’:
soup = BeautifulSoup(page.text, "html.parser")Если попросить его показать, что он там сохранил:
Нам вылезет весь html-код нашей страницы.
Теперь воспользуемся функцией поиска в BeautifulSoup4:
allNews = soup.findAll('a', class_='lenta')Давайте разберём поподробнее, что мы тут написали.
В ранее созданный список ‘news’ (к которому я обещал вернуться), сохраняем все с тэгом ‘а’ и классом ‘news’. Если попросим вывести в консоль все, что он нашел, он покажет нам все новости, что были на странице:

Как видите, вместе с текстом новостей вывелись теги ‘a’, ‘span’, классы ‘lenta’ и ‘time2’, а также ‘time2 time3’, в общем все, что он нашел по нашим пожеланиям.
for data in allNews: if data.find('span', class_='time2 time3') is not None: filteredNews.append(data.text)Тут мы в цикле for перебираем весь наш список новостей. Если в новости мы находим тэг ‘span’ и класc ‘time2 time3’, то сохраняем текст из этой новости в новый список ‘filteredNews’.
Обратите внимание, что мы используем ‘.text’, чтобы переформатировать строки в нашем списке из ‘bs4.element.ResultSet’, который использует BeautifulSoup для своих поисков, в обычный текст.
Однажды я застрял на этой проблеме надолго в силу недопонимания работы форматов данных и неумения использовать debug, будьте осторожны. Таким образом теперь мы можем сохранять эти данные в новый список и использовать все методы списков, ведь теперь это обычный текст и, в общем, делать с ним, что нам захочется.
for data in filteredNews: print(data) 
Мы получаем время публикации и лишь интересные новости.
Дальше можно построить бот в Телеге и выгружать туда эти новости, либо создать виджет на рабочий стол с актуальными новостями. В общем, можно придумать удобный для себя способ узнавать о новостях.
Надеюсь эта статья поможет новичкам понять, что можно делать с помощью парсеров и поможет им немного продвинуться вперед с обучением.
Спасибо за внимание, был рад поделиться опытом.