]*>)(.*)()(.*)()/i', '\\1\\2\\4\\6\\7', $text); print_r($text); Результат:
Комментарии
Другие публикации


Протокол FTP – предназначен для передачи файлов на удаленный хост. В PHP функции для работы с FTP как правило всегда доступны и не требуется установка дополнительного расширения.
Если добавить атрибут contenteditable к элементу, его содержимое становится доступно для редактирования пользователю, а.
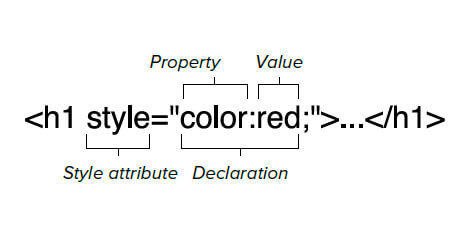
Данный вопрос возникает при верстке писем т.к. стили прописанные в head в почтовых сервисах и программах не работают, а.

Задача: появилась необходимость сделать якорное меню у ранее опубликованных статей, статей много, вручную дополнять их.
Источник
Эта функция пытается возвратить строку str , из которой удалены все NULL-байты, HTML и PHP теги. Для удаления тегов используется тот же автомат, что и в функции fgetss() .
Список параметров
Второй необязательный параметр может быть использован для указания тегов, которые не нужно удалять.
Замечание:
Комментарии HTML и PHP-теги также будут удалены. Это жестко записано в коде и не может быть изменено с помощью параметра allowable_tags .
Замечание:
Этот параметр не должен содержать пробелов. strip_tags() рассматривает тег как нечувствительную к регистру строку, находящуюся между и первым пробелом или >.
Замечание:
В PHP 5.3.4 и новее также необходимо добавлять соответвующий закрывающий тег XHTML, чтобы удалить тег из str . Например, для удаления и и
нужно сделать следующее:
Возвращаемые значения
Возвращает строку без тегов.
Список изменений
| Версия | Описание |
| 5.3.4 | strip_tags() больше не удаляет соответвующие закрывающие XHTML теги, если они не переданы в allowable_tags . |
| 5.0.0 | strip_tags() теперь безопасна для обработки бинарных данных. |
Примеры
Пример #1 Пример использования strip_tags()
Результат выполнения данного примера:
Примечания
Из-за того, что strip_tags() не проверяет валидность HTML, то частичные или сломанные теги могут послужить удалением большего количества текста или данных, чем ожидалось.
Эта функция не изменяет атрибуты тегов, разрешенных с помощью allowable_tags , включая такие атрибуты как style и onmouseover, которые могут быть использованы озорными пользователями при посылке текста, отображаемого также и другим пользователям.
Замечание:
Имена тегов в HTML превышающие 1023 байта будут рассматриваться как невалидные независимо от параметра allowable_tags .
Смотрите также
Источник
Как в php удалить из строки определенные теги? Функция strip_tags удалет все кроме определенных. А мне нужно только определенные. Как это сделать?
Знаю, что регулярки — не лучший способ( https://stackoverflow.com/questions/11229831/regul. ). Думаю, что можно попробовать внести все существующие теги в массив. Потом найти расхождение у этого массива с массивом, в котором те теги, которые я хочу удалить. И потом применить strip_tags. Как вы думаете, хороший вариант? Вот бы только упростить как-нибудь создание массива со всеми тегами.

static public function create_dom($string = null) < $dom = new DOMDocument(); // ---------------------------------------------------------------- // Делается обертка в виде для $string. Это нужно, так как из-за LIBXML_HTML_NOIMPLIED теги могут выводиться несколько некорректно. Подробности по ссылке: // https://stackoverflow.com/questions/29493678/loadhtml-libxml-html-noimplied-on-an-html-fragment-generates-incorrect-tags // Также добавляется кодировка - так как без вместо текста, полученного от ckeditor, будут кракозябры. // ---------------------------------------------------------------- $dom->loadHTML('' . '
' . $string . '
', LIBXML_HTML_NOIMPLIED | LIBXML_HTML_NODEFDTD); $container = $dom->getElementsByTagName('div')->item(0); $container = $container->parentNode->removeChild($container); while ($dom->firstChild) < $dom->removeChild($dom->firstChild); > while ($container->firstChild) < $dom->appendChild($container->firstChild); > return $dom; > static public function unwrap_tags($string, $tags) < $dom = static::create_dom($string); foreach ($dom->childNodes as $c) < if (in_array($c->tagName, $tags)) < // если просто добавить в $result $c->nodeValue, то не добавятся внутренние теги (
, например), ведь их нет в nodeValue. foreach ($c->childNodes as $cc) < $result .= $cc->ownerDocument->saveHTML($cc); > > else < $result .= $c->ownerDocument->saveHTML($c); > > return $result; > static public function prepare_text($text)
Источник