конвертировать из кодировки OEM 866 (кириллица) в UTF?
У меня есть большой текстовый файл csv, экспортированный из российской базы данных. Набор символов — это OEM 866, который не читается большинством приложений, которые я буду использовать для работы с файлом. Есть ли способ конвертировать его в UTF-8 или ANSI? Мое решение: 1) Определите набор символов в качестве кириллического OEM 866 в Notepad++. Теперь файл читается в Notepad++. 2) В Notepad++ попытался преобразовать в UTF-8, UTF8 без спецификации, ANSI. Естественно, Notepad++ считывает преобразованный файл ANSI или UTF, который он только что создал. Но никакой другой программы нет. Извините, если это глупый вопрос, потому что я действительно мало знаю о предмете.
Если Notepad++ может читать кодированный файл UTF-8, особенно тот, который он создал, тогда другие приложения, которые поддерживают кодированные файлы UTF-8, также могут читать один и тот же файл. Не все приложения поддерживают спецификацию UTF-8 в текстовых файлах, но если у вас все еще возникают проблемы с присутствием BOM и без нее, вы должны искать проблемы с этими приложениями, прежде чем будете подозревать проблему с файлом UTF-8. Возможно, эти приложения не загружают текстовый файл как UTF-8, и если это произойдет, они будут неправильно интерпретировать содержимое файла. Многие приложения, как правило, загружают 8-битные текстовые файлы, предполагая, что по умолчанию используется кодировка Ansi по умолчанию, вместо UTF-8 или другой кодировки, поэтому вам может потребоваться, чтобы эти приложения загрузили текстовый файл как UTF-8, если такая опция доступна (там, где спецификации появляются, если такой возможности нет).
Смотрите также
This is edited functions utf8_to_cp1251 and cp1251_to_utf8.
Changes: Check current string encoding.
function cp1251_to_utf8 ( $s )
<
if (( mb_detect_encoding ( $s , ‘UTF-8,CP1251’ )) == «WINDOWS-1251» )
<
$c209 = chr ( 209 ); $c208 = chr ( 208 ); $c129 = chr ( 129 );
for( $i = 0 ; $i < strlen ( $s ); $i ++)
<
$c = ord ( $s [ $i ]);
if ( $c >= 192 and $c elseif ( $c > 239 ) $t .= $c209 . chr ( $c — 112 );
elseif ( $c == 184 ) $t .= $c209 . $c209 ;
elseif ( $c == 168 ) $t .= $c208 . $c129 ;
else $t .= $s [ $i ];
>
return $t ;
>
else
<
return $s ;
>
>
function utf8_to_cp1251 ( $s )
<
if (( mb_detect_encoding ( $s , ‘UTF-8,CP1251’ )) == «UTF-8» )
<
for ( $c = 0 ; $c < strlen ( $s ); $c ++)
<
$i = ord ( $s [ $c ]);
if ( $i if ( $byte2 )
<
$new_c2 =( $c1 & 3 )* 64 +( $i & 63 );
$new_c1 =( $c1 >> 2 )& 5 ;
$new_i = $new_c1 * 256 + $new_c2 ;
if ( $new_i == 1025 )
<
$out_i = 168 ;
> else <
if ( $new_i == 1105 )
<
$out_i = 184 ;
> else <
$out_i = $new_i — 848 ;
>
>
$out .= chr ( $out_i );
$byte2 = false ;
>
if (( $i >> 5 )== 6 )
<
$c1 = $i ;
$byte2 = true ;
>
>
return $out ;
>
else
<
return $s ;
>
>
?>
If you need convert string from Windows-1251 to 866. Some characters of 1251 haven’t representation on DOS 866. For example, long dash — chr(150) will be converted to 0, after that iconv finish his work and other charactes will be skiped. Problem characters range in win1251 (128-159,163,165-167,169,171-174,177-182,187-190).
//$text — input text in windows-1251
//$cout — output text in 866 (cp866, dos ru ascii)
PHP iconv: корректная кодировка строк

Использование PHP дает однозначно работающее решение. Если что-то где-то не отображается, нет синтаксических или семантических ошибок, то проблема будет лежать в используемой кодировке символов. Возможны другие коллизии, но нарушения правил кодирования информации — самые частые.
Общее правило представления информации
Всегда имеет значение кодировка файла, в котором содержится скрипт PHP. Если нет проблем с отображением исходного текста в среде разработки или обычном текстовом редакторе, а в браузере ничего прочитать нельзя — не следует обращаться сразу к функции PHP iconv. Нужно просто поправить строчки:
Это простое правило, обычно в этом контексте проблем нет: если в среде разработки код PHP отображается корректно (кириллица), то в браузере он будет читабелен. Даже малоквалифицированный программист сможет все подстроить так, как надо.

Код PHP — это обработка текстовой информации. Часто программист забывает, что один символ — это далеко не всегда один байт. Если сайт посвящен математическим расчетам, а кириллица применяется при выводе результатов, возможны коллизии. Это решается применением функции iconv() в PHP-коде страницы.
Если в процессе обработки информации используется база данных, то информация может просто «пропасть». В реальность все есть и все работает, просто нужно произвести надлежащие преобразования.
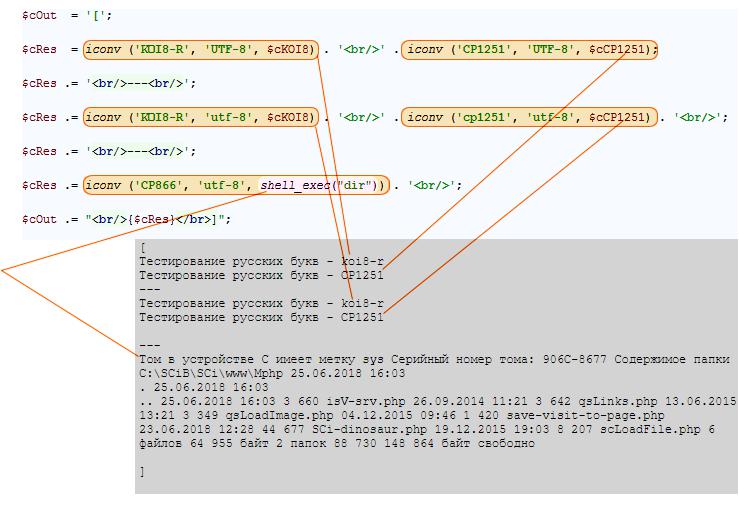
Приведенные примеры показывают, как просто произвести преобразование строк из одной кодировки в другую посредством функции PHP iconv(). Не суть важно, в каком регистре записывать стандартные обозначения кодировок, но смысл использования функции должен быть корректен.
Прежде чем производить преобразование, нужно знать:
В последнем примере показано, как iconv используется для визуализации исполнения внешней команды dir, исполненной в Windows 10. Результаты работы команды возвращены обратно в место вызова, где PHP iconv() трансформировала их из CP866 в UTF-8, и они корректно отобразились в браузере.
Во всех этих случаях функция предоставила возможность получить информацию в читабельном виде.
Работа с базой данных
При работе с базой данных может случиться так, что PHP iconv не работает. Программист тратит драгоценные часы рабочего времени, но результаты запроса просто не отображаются или помещаются в базу данных в нечитабельном виде.
Проблема решается просто. Если запрос исполняется без ошибок, значит, виновато несоответствие кодировки базы данных и кода страницы. Обычно этого достаточно, если нет, нужно проверить кодировку HTML-страницы, PHP-кода и базы данных. Проблема будет решена.

Характерная черта: кодировок много, условия для исполнения работы многогранны, но если один раз все проверить и обеспечить совместимость, то результат будет абсолютно читабельным, а работа веб-ресурса — безукоризненна.