- Как извлечь данные из PDF в Excel (или в CSV) с помощью Python
- How to convert a PDF to CSV or Excel with Python
- Step 1
- Step 2
- Step 3
- Step 4
- Script overview
- Looking to convert multiple PDF files at once?
- Quickly extract Table from PDF to Excel with Python
- PDF to Excel (one table only)
- PDF containing several tables
- Related Posts
- Preprocessing NLP – Tutorial to quickly clean up a text
- YOLOv6 How to Use ? – Best Tutorial Simple
- Decision Tree How to Use It and Its Hyperparameters
- 3 Comments
- Rafael Maffei
- Tom Keldenich
- Kanhu
- Leave a Reply Cancel Reply
Как извлечь данные из PDF в Excel (или в CSV) с помощью Python
PDF — не самый удобный формат для передачи данных, но иногда возникает необходимость извлекать таблицы (или текст). Данный скрипт Python будет особенно полезен в случае, если вам необходимо периодически извлекать данные из однотипных PDF файлов.
Начнём с импорта библиотек, которые мы будем использовать — Pandas (для записи таблиц в CSV/Excel). Непосредственно работать с PDF файлами мы будем с помощью библиотеки tabula. (установка — cmd -> «pip install tabula-py» ; также для работы необходимо установить Java (https://www.java.com/en/download/))
import tabula import pandas as pdЗадаём путь к файлу в формате PDF, из которого необходимо извлечь табличные данные:
Извлекаем все таблицы из файла в переменную PDF в виде вложенных списков.
PDF = tabula.read_pdf(pdf_in, pages='all', multiple_tables=True) pages=’all’ и multiple_tables=True — необязательные параметры
Далее прописываем пути к Excel/CSV файлам, которые мы хотим получить на выходе:
pdf_out_xlsx = "D:\Temp\From_PDF.xlsx" pdf_out_csv = "D:\Temp\From_PDF.csv"Для сохранения в .xlsx мы создаем датафрейм pandas из нашего вложенного списка и используем pandas.DataFrame.to_excel :
PDF = pd.DataFrame(PDF) PDF.to_excel(pdf_out_xlsx,index=False) Для сохранения в CSV мы можем использовать convert_into из tabula.
tabula.convert_into (input_PDF, pdf_out_csv, pages='all',multiple_tables=True) print("Done")# Script to export tables from PDF files # Requirements: # Pandas (cmd --> pip install pandas) # Java (https://www.java.com/en/download/) # Tabula (cmd --> pip install tabula-py) # openpyxl (cmd --> pip install openpyxl) to export to Excel from pandas dataframe import tabula import pandas as pd # Path to input PDF file pdf_in = "D:/Folder/File.pdf" #Path to PDF # pages and multiple_tables are optional attributes # outputs df as list PDF = tabula.read_pdf(pdf_in, pages='all', multiple_tables=True) #View result print ('\nTables from PDF file\n'+str(PDF)) #CSV and Excel save paths pdf_out_xlsx = "D:\Temp\From_PDF.xlsx" pdf_out_csv = "D:\Temp\From_PDF.csv" # to Excel PDF = pd.DataFrame(PDF) PDF.to_excel(pdf_out_xlsx,index=False) # to CSV tabula.convert_into (input_PDF, pdf_out_csv, pages='all',multiple_tables=True) print("Done") How to convert a PDF to CSV or Excel with Python
You can convert your PDF to Excel, CSV, XML or HTML with Python using the PDFTables API. Our API will enable you to convert PDFs without uploading each one manually.
In this tutorial, I’ll be showing you how to get the library set up on your local machine and then use it to convert PDF to Excel, with Python.
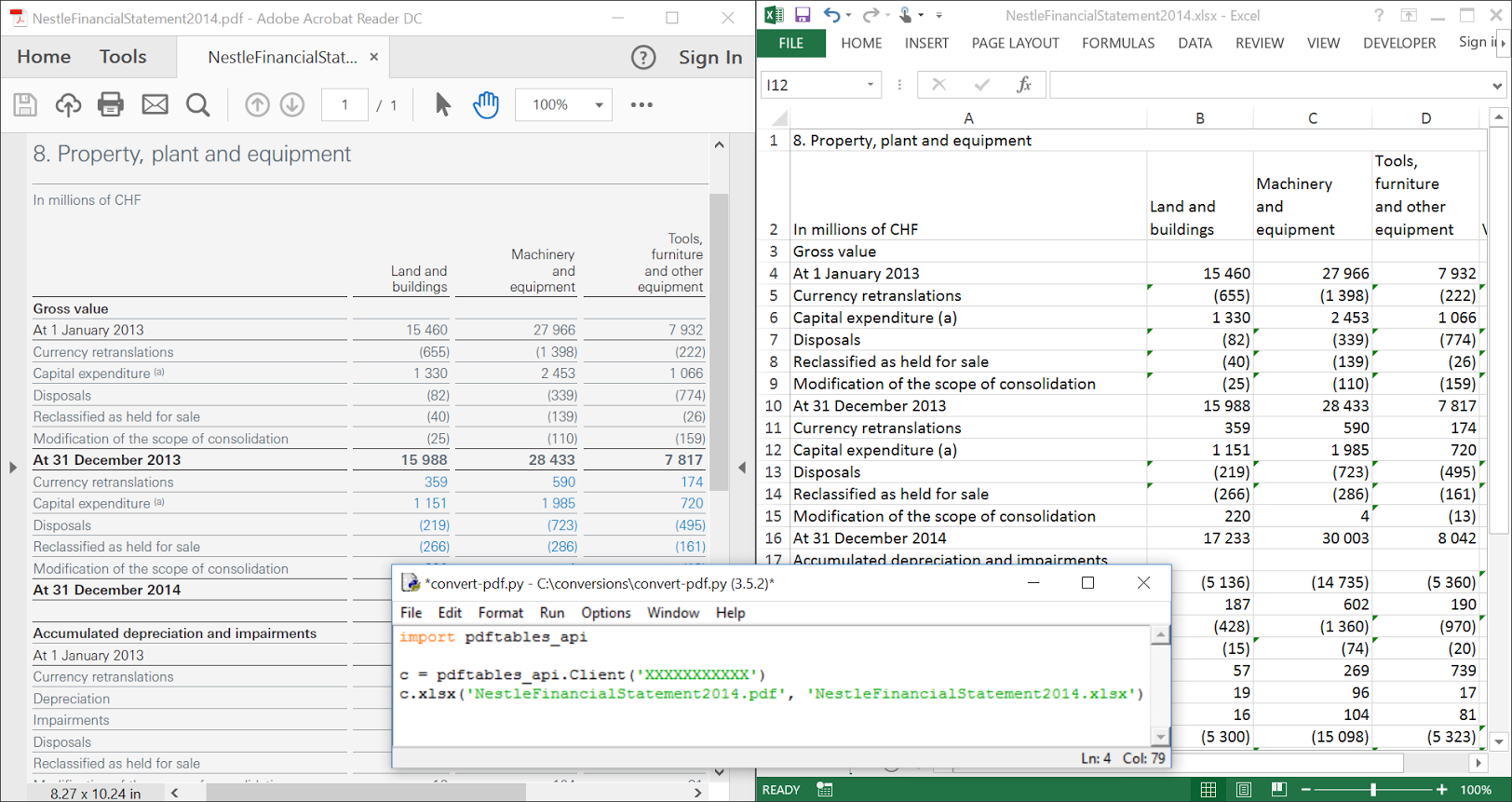
Here’s an example of a PDF that I’ve converted with the library. In order to properly test the library, make sure you have a PDF handy!
Step 1
If you haven’t already, install Anaconda on your machine from Anaconda website. You can use either Python 3.6.x or 2.7.x, as the PDFTables API works with both. Downloading Anaconda means that pip will also be installed. Pip gives a simple way to install the PDFTables API Python package.
For this tutorial, I’ll be using the Windows Python IDLE Shell, but the instructions are almost identical for Linux and Mac.
Step 2
In your terminal/command line, install the PDFTables Python library with:
pip install git+https://github.com/pdftables/python-pdftables-api.git
If git is not recognised, download it here. Then, run the above command again.
Or if you’d prefer to install it manually, you can download it from python-pdftables-api then install it with:
Step 3
Create a new Python script then add the following code:
import pdftables_api c = pdftables_api.Client('my-api-key') c.xlsx('input.pdf', 'output') #replace c.xlsx with c.csv to convert to CSV #replace c.xlsx with c.xml to convert to XML #replace c.xlsx with c.html to convert to HTML Now, you’ll need to make the following changes to the script:
- Replace my-api-key with your PDFTables API key, which you can get here.
- Replace input.pdf with the PDF you would like to convert.
- Replace output with the name you’d like to give the converted document.
Now, save your finished script as convert-pdf.py in the same directory as the PDF document you’d like to convert.
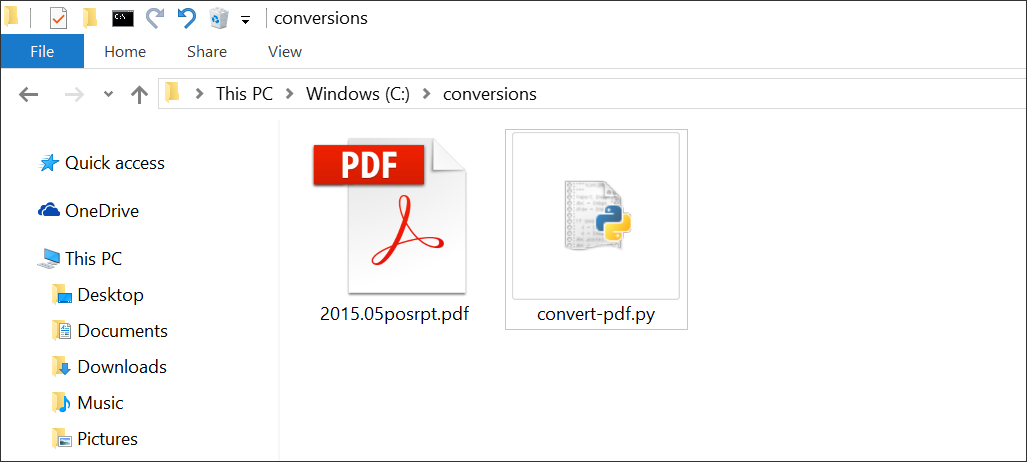
If you don’t understand the script above, see the script overview section.
Step 4
Open your command line/terminal and change your directory (e.g. cd C:/Users/Bob ) to the folder you saved your convert-pdf.py script and PDF in, then run the following command:
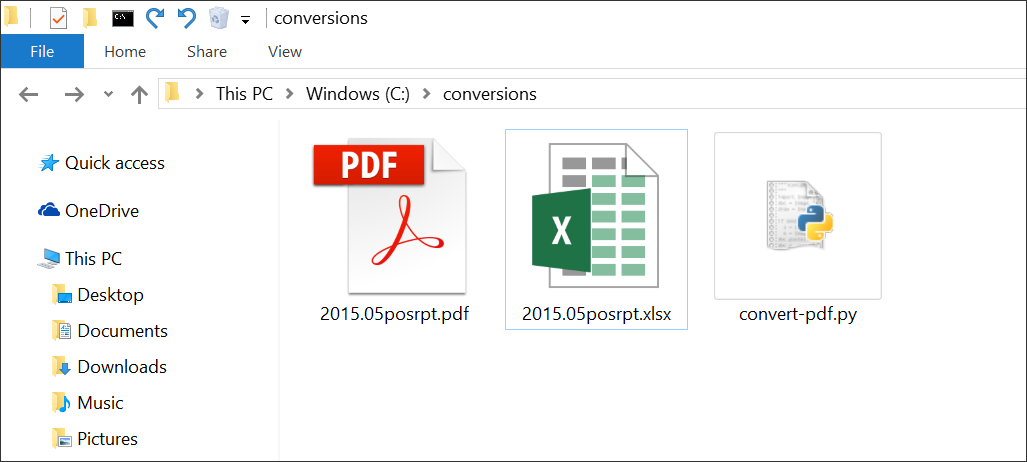
To find your converted spreadsheet, navigate to the folder in your file explorer and hey presto, you’ve converted a PDF to Excel or CSV with Python!
Script overview
The first line is simply importing the PDFTables API toolset, so that Python knows what to do when certain actions are called. The second line is calling the PDFTables API with your unique API key. This means here at PDFTables we know which account is using the API and how many PDF pages are available. Finally, the third line is telling Python to convert the file with name input.pdf to xlsx and also what you would like it to be called upon output: output . To convert to CSV, XML or HTML simply change c.xlsx to be c.csv , c.xml or c.html respectively.
Looking to convert multiple PDF files at once?
Love PDFTables? Leave us a review on our Trustpilot page!
Quickly extract Table from PDF to Excel with Python

To install them, go to your terminal/shell and type these lines of code:
pip install tabula-py pip install pandasIf you use Google Colab, you can install these libraries directly on it. You just have to add an exclamation mark “!” in front of it, like this:
!pip install tabula-py !pip install pandasPDF to Excel (one table only)
First we load the libraries into our text editor :
import tabula import pandas as pdThen, we will read the pdf with the read_pdf() function of the tabula library.
This function automatically detects the tables in a pdf and converts them into DataFrames. Ideal for converting them into Excel files!
df = tabula.read_pdf('file_path/file.pdf', pages = 'all')[0]We can then check that the table has the expected shape.
Then convert it to an Excel file !
df.to_excel('file_path/file.xlsx')The entire code :
THE PANE METHOD FOR DEEP LEARNING!
Get your 7 DAYS FREE TRAINING to learn how to create your first ARTIFICIAL INTELLIGENCE!
For the next 7 days I will show you how to use Neural Networks.
You will learn what Deep Learning is with concrete examples that will stick in your head.
BEWARE, this email series is not for everyone. If you are the kind of person who likes theoretical and academic courses, you can skip it.
But if you want to learn the PANE method to do Deep Learning, click here :
import tabula import pandas as pd df = tabula.read_pdf('file_path/file.pdf', pages = 'all')[0] df.to_excel('file_path/file.xlsx')
PDF containing several tables
We load the libraries in our text editor :
import tabula import pandas as pdThen, we will read the pdf with the read_pdf() function of the tabula library.
This function automatically detects the tables in a pdf and converts them into DataFrames. Ideal to convert them then in Excel file !
Here, the variable df will be in fact a list of DataFrame. The first element corresponds to the first table, the second to the second table, etc.
df = tabula.read_pdf('file_path/file.pdf', pages = 'all')To save these tables separately, you will have to use a for loop that will save each table in an Excel file.
for i in range(len(df)): df[i].to_excel('file_'+str(i)+'.xlsx')The entire code :
import tabula import pandas as pd df = tabula.read_pdf('file_path/file.pdf', pages = 'all') for i in range(len(df)): df[i].to_excel('file_'+str(i)+'.xlsx')THE PANE METHOD FOR DEEP LEARNING!
Get your 7 DAYS FREE TRAINING to learn how to create your first ARTIFICIAL INTELLIGENCE!
For the next 7 days I will show you how to use Neural Networks.
You will learn what Deep Learning is with concrete examples that will stick in your head.
BEWARE, this email series is not for everyone. If you are the kind of person who likes theoretical and academic courses, you can skip it.
But if you want to learn the PANE method to do Deep Learning, click here :
Tom Keldenich
Artificial Intelligence engineer and data enthusiast!
Founder of the website Inside Machine Learning
Related Posts
Preprocessing NLP – Tutorial to quickly clean up a text
YOLOv6 How to Use ? – Best Tutorial Simple
Decision Tree How to Use It and Its Hyperparameters
3 Comments
Rafael Maffei
Tom Keldenich
Hi Rafael, In order to save multiple .xlsx in the same file you can use the XlsxWriter library ! To install it : !pip install XlsxWriter And to you use it, here’s the code : import tabula
import pandas as pd
df = tabula.read_pdf(‘file_path/file.pdf’, pages = ‘all’) writer = pd.ExcelWriter(‘file_multiple_df.xlsx’, engine=’xlsxwriter’) for i in range(len(df)):
df[i].to_excel(writer, sheet_name=’Sheet’+str(i)) writer.save() You’ll have an excel file with multiple Sheet, each containing a dataframe ! 🙂
Kanhu
Why the read_pdf is not giving me the same number of columns as the pdf for the following file? If I am right, multiple columns are merged together.
https://drive.google.com/file/d/1VRwU8C6I8KzMVz2IVKPkoqrncCcGZHh-/view?usp=sharing
Leave a Reply Cancel Reply
Entre ton email pour recevoir gratuitement le bonus de cette article
En plus, tu recevras le « Plan d’action pour Maîtriser les Réseaux de neurones ».
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
Email *
Tu recevras un email par jour pendant 7 jours – puis tu recevras ma newsletter. Tes informations ne seront jamais cédées à des tiers.
Tu peux te désinscrire en 1 clic depuis n’importe lequel de mes emails.
Entre ton email pour recevoir gratuitement le « Plan d’action pour Maîtriser les Réseaux de neurones »
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
Email *
Tu recevras un email par jour pendant 7 jours – puis tu recevras ma newsletter. Tes informations ne seront jamais cédées à des tiers.
Tu peux te désinscrire en 1 clic depuis n’importe lequel de mes emails.
You will receive one email per day for 7 days – then you will receive my newsletter.
Your information will never be given to third parties.
You can unsubscribe in 1 click from any of my emails.