- Saved searches
- Use saved searches to filter your results more quickly
- License
- alevikpes/telegram-parser
- Name already in use
- Sign In Required
- Launching GitHub Desktop
- Launching GitHub Desktop
- Launching Xcode
- Launching Visual Studio Code
- Latest commit
- Git stats
- Files
- README.md
- От парсера афиши театра на Python до Telegram-бота. Часть 1
- 1. Зарождение идеи и постановка задачи
- 2. Первая реализация. Минимальный функционал
- 3. Расширение функционала
Saved searches
Use saved searches to filter your results more quickly
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
Parse Telegram channels and users
License
alevikpes/telegram-parser
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.md
This script logs in as a user and can perform actions on behalf of the currently logged in user.
At the moment it can get all the groups, where the user is subscribed and get a list of users of some of those groups. This script cannot get the users of any group due to some kind of restrictions, which the group admins place for in the groups.
In order to start using this bot, it is necessary to obtain API ID and API HASH for your user account.
It can be done via https://my.telegram.org/. Enter your phone number, verify with the sent code and go to the API Development Tools page. There create an app and copy API ID and API HASH.
If there is a plan to use a bot, then the bot must be created via the BotFather in any Telegram application. See Telegram instructions. Such bot will have a name and a token, which also must be stored.
NOTE Bots cannot perform all the actions, so the creation of the user application, as desribed above, may be necessary for certain tasks.
WARNING Never give anyone the credentials of neither your user application nor your bot. Also add to the ignore list of your VCS, the files, which have the credentials stored.
Create a file .env and save there the API ID, the API HASH, the bot name, the bot token, a database name (can be any), a session name (can be any) and, possibly, other required data in the following format:
APP_API_HASH= APP_API_ID= DB_NAME= SESSION_NAME= TG_BOT_NAME= TG_BOT_TOKEN= . NOTE Do not use spaces or other special characters in your custom names.
WARNING Never give anyone the credentials of neither your user application nor your bot. Also add to the ignore list of your VCS, the files, which have the credentials stored.
Create a python virtual environment (search online about how to do it for your OS). On Linux Debian distros it can be done with:
sudo apt install python3-venv -y python3 -m venv /path/to/virtual-environment
Start your virtual environment:
source /path/to/virtual-environment/bin/activate pip3 install -r requirements.txt
This will create an sqlite database file with two tables group and user . The name of the file will be read from the .env file. See init.py for more details.
After the initialisation it is all ready for parsing channels and users.
NOTE Always start your virtual environment before executing the sripts:
source /path/to/virtual-environment/bin/activate Run main.py to start the parsing:
The script will parse the channels and save their info and the data of the participants of those channels into the database.
In order to parse only one channel, use -g optional argument with the cahnnel username (the name which starts with @ symbol and can be found in the channel info page, specifying @ is not necessary):
python3 main.py -g channel username> От парсера афиши театра на Python до Telegram-бота. Часть 1

Я очень люблю оперу и балет, но не очень — отдавать большие деньги за билеты. Ежедневный просмотр сайта театра с тыканьем в каждую кнопку ужасно утомлял, а внезапно появлявшиеся билеты по 170 рублей на супер-составы бередили душу.
Чтобы автоматизировать это дело появился скриптик, который бежит по афише и собирает информацию о самых дешевых билетах на выбранный месяц. Запросы из серии «выдай список всех опер в марте на старой и новой сцене до 1000 рублей». Подруга обронила «а ты не Telegram-бота делаешь?». Такого в плане не было, но почему бы и нет. Бот родился, хоть и крутился на домашнем ноутбуке.
Потом Telegram заблокировали. Мысль запулить бота на рабочий сервер растаяла, да и интерес, чтобы довести функционал до ума, угас. Под катом рассказываю о судьбе сыщика дешевых билетов с самого начала и о том, что с ним сталось после года использования.
1. Зарождение идеи и постановка задачи
В первоначальной постановке у всей истории была одна задача — формировать отфильтрованный по цене список спектаклей, чтобы экономить время на ручном просмотре каждого спектакля афиши в отдельности. Единственный театр, чья афиша интересовала, был и остается Мариинский. Личный опыт быстро показал, что бюджетная «галерка» открывается в случайные дни на случайные спектакли, а раскупается достаточно быстро (если состав стоящий). Чтобы ничего не упустить, и нужен автоматический сборщик.

Хотелось за прогон скрипта получать ограниченный набор интересующих спектаклей. Главным критерием, как уже говорилось, была цена на билет.
API сайта и билетной системы в открытом доступе нет, поэтому было принято решение (не мудрствуя лукаво) пропарсить HTML-страницы, по тегам выдергивая нужное. Открываем главную, жмем F12 и изучаем структуру. Выглядело адекватно, так что дело быстро дошло до 1й реализации.
Понятно, что такой подход не масштабируется на другие сайты с афишами и посыпется, если текущую структуру решат сменить. Если у читателей есть идеи, как сделать стабильнее без API, пишите в комментарии.
2. Первая реализация. Минимальный функционал
К реализации подошла с опытом работы с Python только для решения задач, связанных с машинным обучением. Да и какого-то глубокого понимания html и web-архитектуры не было (и не появилось). Поэтому все делалось по принципу «куда иду знаю, а как идти — сейчас найдем»
Для первых набросков понадобилось 4 вечерних часа и знакомство с модулями requests и Beautiful Soup 4 (не без помощи годной статьи, спасибо автору). Для допиливания наброска — еще выходной день. Не до конца уверена, что модули самые оптимальные в своем сегменте, но текущие потребности они закрыли. Вот что вышло на первом этапе.
Какую информацию и откуда выдергивать можно понять по структуре сайта. Первым делом — собираем адреса представлений, которые есть в афише на выбранный месяц.
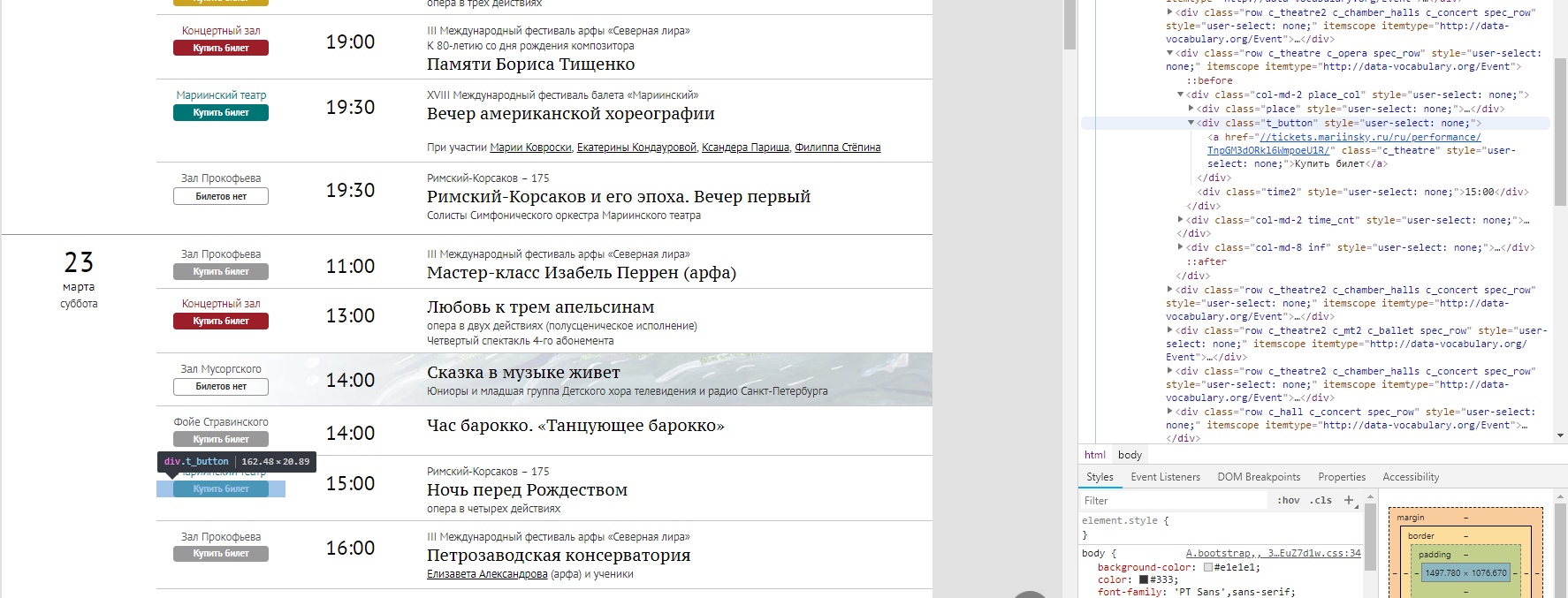
Из html-страницы нам надо считать чистые URL-адреса, чтобы потом пройтись по ним и посмотреть ценник. Примерно так происходит сборка списка линков.
import requests import numpy as np from bs4 import BeautifulSoup def get_text(url): #из URL вытаскиваем html r = requests.get(url) text=r.text return text def get_items(text,top_name,class_name): """ из всего html-текста собираем "грязные" url-ки, т.е. с какой-то обвеской. В нашем случае выдергиваем их через top_name и class_name итог выглядит как-то так Купить билет """ soup = BeautifulSoup(text, "lxml") film_list = soup.find('div', ) items = film_list.find_all('div', ) dirty_link=[] for item in items: dirty_link.append(str(item.find('a'))) return dirty_link def get_links(dirty_list,start,end): #из "грязной" версии забираем чистые URL-ы links=[] for row in dirty_list: if row!='None': i_beg=row.find(start) i_end=row.rfind(end) if i_beg!=-1 & i_end!=-1: links.append(row[i_beg:i_end]) return links #пользователь вводит, в каком месяце ищем, так как афиша по месяцам num=int(input('Введите номер месяца для поиска: ')) #URL афиши зафиксирован. Год можно подтягивать из текущей даты, но так тоже окей=) url ='https://www.mariinsky.ru/ru/playbill/playbill/?year=2019&month='+str(num) #ключевые слова для поиска top_name='container content gr_top' class_name='t_button' start='tickets' end='/">Купить' #вызов функций text=get_text(url) dirty_link=get_items(text,top_name,class_name) #и получаем списочек URL-адресов, ведущих на покупку билетов links=get_links(dirty_link,start,end) После изучения структуры страницы с покупкой билетов, помимо порога по цене, решила дать возможность пользователю также выбрать:
- тип представления (1-опера, 2-балет, 3-концерт, 4-лекция)
- место проведения (1-старая сцена, 2-новая сцена, 3-концертный зал, 4-камерные залы)

Далее мы проходимся по всем полученным линкам. Делаем get_text и ищем по нему нижнюю цену, а также выдергиваем сопутствующую информацию. Из-за того, что приходится заглядывать в каждый URL и преобразовывать его в text, время работы программы не мгновенное. Хорошо бы оптимизировать, но я не придумала, как.
Приводить сам код не буду, получится длинновато, но там все правда адекватно и «интуитивно понятно» с Beautiful Soup 4.
Если цена меньше заявленной пользователем и тип-место соответствуют заданным, то в консоли выводится сообщение о спектакле. Был еще вариант сохранения всего этого в .xls, но это не прижилось. Смотреть в консоли и сразу переходить по ссылкам удобнее, чем тыкаться в файл.
Вышло около 150 строк кода. В этом варианте, с описанными минимальными функциями скрипт живее всех живых и запускается регулярно с периодом в пару дней. Все остальные модификации либо были не допилены (шило утихло) и поэтому неактивны, либо не более выигрышные по функциям.
3. Расширение функционала
На втором этапе решила отслеживать изменение цен, храня ссылки на интересующие спектакли в отдельном файле (точнее URL на них). В первую очередь это актуально для балетов — сильно дёшево на них бывает редко и в общую бюджетную выдачу они не попадут. Но с 5 тысяч до 2х падение значимо, особенно если спектакль с звездным составом, и его хотелось отследить.
Чтобы это сделать надо сначала добавить URL-адреса для отслеживания, а потом периодически «перетряхивать» их и сравнивать новую цену со старой.
def add_new_URL(user_id,perf_url): #user_id нужно, чтобы отличать пользователей и потом пригодилось в телеграм-боте WAITING_FILE = "waiting_list.csv" with open(WAITING_FILE, "a", newline="") as file: curent_url='https://'+perf_url text=get_text(curent_url) #проходим разок и собираем инфо о спектакле-минимальную цену, название,дату,тип и место minP, name,date,typ,place=find_lowest(text) user = [str(user_id), perf_url,str(m)] writer = csv.writer(file) writer.writerow(user) def update_prices(): #а так можно обновлять цены на интересующие спектакли print('Обновляю цены') WAITING_FILE = "waiting_list.csv" with open(WAITING_FILE, "r", newline="") as file: reader = csv.reader(file) gen=[] for row in reader: gen.append(list(row)) L=len(gen) lowest=<> with open(WAITING_FILE, "w", newline="") as fl: writer = csv.writer(fl) for i in range(L): lowest[gen[i][1]]=gen[i][2] #добавляем по ключу URL цену for k in lowest.keys(): text=get_text('https://'+k) minP, name,date,typ,place=find_lowest(text) if minP==0: #где билетов нет ставим большой ценник, а при их появлении цена "упадет" minP=100000 if int(minP)Обновление цен запускалось в начале главного скрипта, отдельно не выносилось. Может, не так изящно, как хотелось бы, но свою задачу решает. Так что вторым дополнительным функционалом стал мониторинг снижения цен на интересующие спектакли.
Дальше рождался Telegram-бот, не так легко-быстро-задорно, но все же родился. Чтобы не собирать все в одну кучу, история о нем (а также о нереализованных идеях и попытке проделать такое с сайтом Большого театра) будет во второй части статьи.
ИТОГ: затея удалась, пользователь(я) доволен. Потребовалась пара выходных разобраться, как взаимодействовать с html-страницами. Благо Python язык-почти-для-всего и готовые модули помогают вбить гвоздь не задумываясь о физике работы молотка.
Надеюсь, кейс будет полезен хабравчанам и, возможно, сработает как волшебный пендель, чтобы сделать наконец давно сидящую в голове хотелку.