- Парсинг на Python с Beautiful Soup
- Установка библиотек для парсинга
- Поиск сайта для скрапинга
- Saved searches
- Use saved searches to filter your results more quickly
- vas3k/python-glr-parser
- Name already in use
- Sign In Required
- Launching GitHub Desktop
- Launching GitHub Desktop
- Launching Xcode
- Launching Visual Studio Code
- Latest commit
- Git stats
- Files
- README.md
Парсинг на Python с Beautiful Soup
Парсинг — это распространенный способ получения данных из интернета для разного типа приложений. Практически бесконечное количество информации в сети объясняет факт существования разнообразных инструментов для ее сбора. В процессе скрапинга компьютер отправляет запрос, в ответ на который получает HTML-документ. После этого начинается этап парсинга. Здесь уже можно сосредоточиться только на тех данных, которые нужны. В этом материале используем такие библиотеки, как Beautiful Soup, Ixml и Requests. Разберем их.
Установка библиотек для парсинга
Чтобы двигаться дальше, сначала выполните эти команды в терминале. Также рекомендуется использовать виртуальную среду, чтобы система «оставалась чистой».
pip install lxml pip install requests pip install beautifulsoup4Поиск сайта для скрапинга
Для знакомства с процессом скрапинга можно воспользоваться сайтом https://quotes.toscrape.com/, который, похоже, был создан для этих целей.
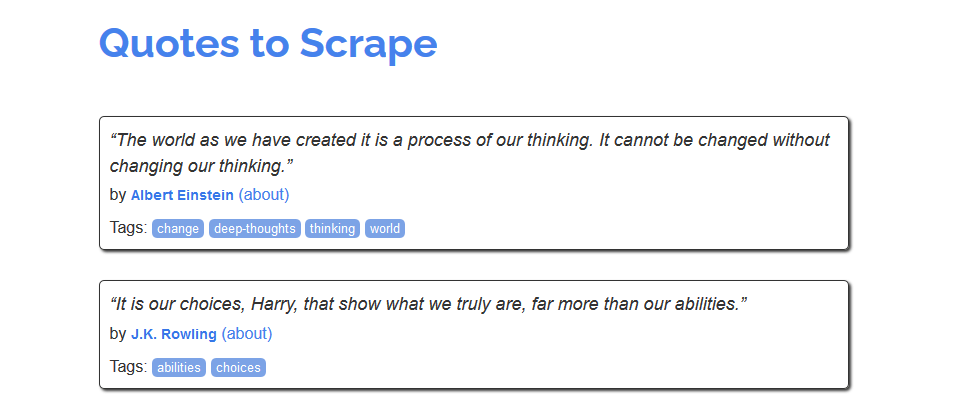
Из него можно было бы создать, например, хранилище имен авторов, тегов или самих цитат. Но как это сделать? Сперва нужно изучить исходный код страницы. Это те данные, которые возвращаются в ответ на запрос. В современных браузерах этот код можно посмотреть, кликнув правой кнопкой на странице и нажав «Просмотр кода страницы».

На экране будет выведена сырая HTML-разметка страница. Например, такая:
Saved searches
Use saved searches to filter your results more quickly
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
Попытка сделать свой GLR-парсер для русского языка на Python
vas3k/python-glr-parser
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.md
Инструмент извлечения структурированных данных (фактов) из текста на естественном (русском) языке на Python 2.x. Построен с использованием любимого всеми морфологического анализатора pymorphy2 и никому неизвестного GLR-парсера jupyLR (был взят как самый простой для переписывания). Чем-то похож на Томита-парсер Яндекса (http://api.yandex.ru/tomita/), хотя чего греха таить, общем-то проект и был начат из-за сложной применимости Томита-парсера простыми смертными в силу особеностей его распространения и небогатой документации. По которой, в прочем, вполне очевидно, что сам парсер был открыт Яндексом лишь частично, а цель помочь простым смертным при этом была далеко не на первом месте (иначе бы Яндекс распространял его не скудным бинарником, а оформил как остальные свои проекты в библиотеку или демон).
Проект практически повторяет открытую функциональность Томита-парсера, однако написан на чистом python и открыт, что позволяет использовать его в реальных проектах и модифицировать. А еще не болен протобафом головного мозга, а использует понятные и простые питонячие структуры данных. Возможно когда-нибудь Яндекс таки дооткроет Томита-парсер и настанут светлые времена, а пока таким вот отщепенцам как я приходится выживать как могут.
Подробнее про работу GLR-парсеров и алгоритма Томиты можно почитать на википедии или нагуглить. http://ru.wikipedia.org/wiki/GLR-%D0%BF%D0%B0%D1%80%D1%81%D0%B5%D1%80
Для примера можно смотреть example.py.
from glr import GLRParser dictionaries = < u"CLOTHES": [u"куртка", u"пальто", u"шубы"] >grammar = u""" S = adj CLOTHES """ glr = GLRParser(grammar, dictionaries=dictionaries) text = u"на вешалке висят пять красивых курток и вонючая шуба" for parsed in glr.parse(text): print "FOUND:", parsed # FOUND: красивых курток # FOUND: вонючая шуба Примерное описание работы
- Входной текст разбивается на предложения по символам [!?;.]+, а так же очищается от лишних символов. Если такое поведение не устраивает, модифицируйте splitter.py.
- Каждое предложение разбивается на токены согласно регулярным выражениям в glr.py (константа DEFAULT_PARSER). Модифицируя этот список, можно вводить свои терминальные символы в грамматику (токены новых типов, например, можно ввести отдельный тип для чисел).
- Каждый токен нормализуется и к нему добавляются его морфологические характеристики. Морфологическая неоднозначность снимается. никак. Берется просто первая форма, которую вернул pymorphy2. Если такое поведение не устраивает — милости прошу в normalizer.py и в пулл реквесты.
- Дальше стандартный GLR-парсинг входной строки. Если строка не разбирается, то отбрасывается первый токен и все повторяется заново. Все совпадения откладываются и в конце возвращается список.
Начальный символ — S (можно менять параметром root в конструкторе GLRParser);
Нетерминал — зарезервированное слово в нижнем регистре (adj, verb, noun, см. начало GLRParser чтобы научиться вводить свои);
Терминал — слово с большой буквы (зарезервированное Word или любое введенное прям в грамматике AsYouWish);
Словари — слово капсом, означающее название словаря (например CITIES), сами словари задаются как < "CITIES": ["val1", "val2", . ]>и передаются в конструктор GLRParser;
Одно слово — слово в ‘одинарных’ ‘кавычках’, будет искаться во всех своих формах (например ‘шуба’) (hint: в грамматике слово нужно указывать в начальной форме, а то не найдется);
Лейблы — список через запятую в после терминала/нетерминала.
S = SomeClothes SomeClothes = adj 'шуба' SomeClothes = adj 'валенок' Словарь задается простым питоновским словарем (каламбурчик). Ключи — названия словарей, их принято писать капсом. А еще лучше везде использовать юникод-строки, а то мало ли. Например:
Пример использования есть выше.
Список зарезервированных терминалов и нетерминалов
| Символ | Значение |
|---|---|
| Word | Любое слово |
| noun | Существительное |
| adj | Прилагательное |
| verb | Глагол |
| pr | Причастие |
| dpr | Деепричастие |
| num | Числительное (или число) |
| adv | Наречие |
| pnoun | Местоимение |
| prep | Предлог |
| conj | Союз |
| prcl | Частица |
| lat | Слово на латинице |
Лейблами можно задавать ограничения или сочетаемость слов. Заметьте, что лейблы могут сильно повлиять на производительность, если применять их к слишком широким по значению (не)терминалам. Не увлекайтесь. Лейблы всегда проверяются только на этапе свертки, если вы понимаете о чем я.
| Символ | Значение |
|---|---|
| gram | Слово имеет какое-то грамматическое свойство, например определенный падеж. Пример: adj — прилагательное в родительном падеже. |
| reg-l-all | Все буквы в слове нижнего регистра. Пример: noun — существительное, все буквы маленькие. |
| reg-h-first | Первая буква — заглавная. Пример: noun — существительное с заглавной буквы. |
| reg-h-all | Все буквы заглавные (капс). Пример аналогичен предыдущим. |
| agr-gnc | Согласование по роду, числу, падежу (gender, number, case). Пример: adj noun — прилагательное согласуется со следующим за ним существительным по роду, числу, падежу. Обратите внимание, цифра указывает с каким по счету словом от этого сравнивать (возможно и отрицательное значение). |
| agr-nc | По числу и падежу (number, case). Пример аналогичен. |
| agr-c | По падежу (case). |
| agr-gn | По роду и числу (gender, number). |
| agr-gc | По роду и падежу (gender, case). |
| regex | Слово удовлетворяет регулярному выражению. Пример: word. |
Можно указывать сразу по нескольку лейблов через запятую. Например noun — существительное в именительном падеже, все буквы которого в нижнем регистре.
Если нужно указать несколько значений одного лейбла, это можно делать так: (слово мужского рода в именительном падеже).