Python Практический. Скрапинг/Парсинг сайтов с Selenium и BS4
В этом уроке мы спарсим данные с сайта с помощью Selenium. Selenium нужен, чтобы автоматизировать браузер.
Таблица, которую мы будем извлекать находится здесь. Ее не получится извлечь простым способом, потому что url таблицы не меняется при переходе на другие страницы.
Решение
Импортируем нужные модули, функции и укажем рабочую папку.
# Импортировать модуль и указать папку import os import pandas as pd from selenium import webdriver from selenium.webdriver.common.keys import Keys import time from bs4 import BeautifulSoup os.chdir(r'c:\Download') os.getcwd()Запускаем драйвер и открываем url.
# Запускаем драйвер, открываем веб-страницу browser = webdriver.Firefox() browser.get('https://subsidies.qoldau.kz/ru/subsidies/recipients?Year=2020')Получаем ссылки для переключения страниц.
# Все ссылки на все страницы pages = browser.find_elements_by_tag_name('div.btn-group ul li')Получаем текст этих ссылок и записываем его в список.
# Список страниц pg_list = [] for page in pages: try: pg_list.append(int(page.text)) except: continueСоздаем пустой датафрейм, извлекаем таблицу с каждой страницы с помощью Selenium и записываем в созданный датафрейм.
# Создаем датафрейм и записываем туда все таблицы table = pd.DataFrame() for pg in range(min(pg_list),max(pg_list)+1): pg_link = browser.find_element_by_link_text(str(pg)) pg_link.click() html=browser.page_source soup=BeautifulSoup(html,'html.parser') elem = soup.select_one('table.sw-table-content') content = pd.read_html(str(elem)) content = pd.DataFrame(content[0]) content.columns = ['Номер', 'Наименование', 'Сумма', 'Полученные субсидии'] table = pd.concat([table, content]) time.sleep(2)Запишем получившийся результат в XLSX.
# Записываем результат в XLSX table.to_excel('Получатели субсидий.xlsx')Примененные функции
- os.chdir
- os.getcwd
- bs4.BeautifulSoup
- list.append
- pandas.DataFrame
- bs4.BeautifulSoup.select_one
- pandas.read_html
- pandas.concat
- time.sleep
- pandas.DataFrame.to_excel
Курс Python Практический
| Номер урока | Урок | Описание |
|---|---|---|
| 1 | Python Практический. Скачиваем котировки | В этом уроке мы научимся скачивать котировки с помощью модуля pandas_datareader. |
| 2 | Python Практический. Объединить книги Excel | В этом уроке мы объединим много Excel файлов в один CSV файл с помощью Python |
| 3 | Python Практический. Объединить книги Excel | Дополним урок по объединению большого количества XLSX файлов в один CSV при помощи Python. Добавим Progress Bar и вывод времени начала обработки каждого файла. |
| 4 | Python Практический. Создать Progress Bar | В этом уроке мы научимся создавать Progress Bar в Python. Для этого воспользуемся модулем tqdm. |
| 5 | Python Практический. Объединить листы книги Excel | Объединим множество листов одной книги Excel по вертикали. |
| 6 | Python Практический. Объединить книги Excel и листы в них | Как объединить книги Excel и все листы в них в одну таблицу. |
| 7 | Python Практический. Объединить множество CSV | Объединим множество CSV файлов по вертикали в один CSV файл. |
| 8 | Python Практический. Таблицы из множества интернет-страниц | Извлечем таблицу из множества веб-страниц и объединим по вертикали. |
| 9 | Python Практический. Многостраничное извлечение таблиц с Requests и BS4 | В этом уроке мы с помощью Python модулей Requests и BS4 извлечем таблицу из множества web-страниц, потом все эти таблицы объединим по вертикали в одну и запишем результат в Excel файл. |
| 10 | Python Практический. Скрапинг/Парсинг сайтов с Selenium и BS4 | В этом уроке мы будем скрапить/парсить веб сайт с Python модулями Selenium и BF4. |
| 11 | Python Практический. Автоматизация браузера Python Selenium, Скрапинг, скачивание выписок ЕГРЮЛ | В этом уроке мы познакомимся с модулем Selenium для Python. Он позволяет автоматизировать работу браузера, например, открывать веб-страницы, заполнять формы, получать содержимое блоков и скачивать файлы. Мы изучим основы Selenium на примере получения данных ЕГРЮЛ по ИНН и автоматическому скачиванию выписок ЕГРЮЛ. |
| 12 | Python Практический. Множественная замена текста с Pandas | В этом уроке мы выполним множественную замена текста с помощью модуля Pandas |
Python Практический. Скрапинг/Парсинг сайтов с Selenium и BS4 was last modified: 14 июня, 2022 by Admin
Парсинг сайта с помощью PYTHON + SELENIUM

В этой статье, на примере моей задачи, рассмотрим, как можно извлечь большой объем данных с сайта ГИББД и с помощью какого инструмента. Это может быть полезно для финансовых компаний, которые принимают автомобили в качестве залога. Итак, мне необходимо было получить информацию о владельцах и периодах владения автомобилями, чтобы определить были ли изменения в конкретном периоде. Данная информация есть на официальном сайте ГИБДД.рф. На входе было дано 70 тысяч VIN номеров автомобилей, по которым и возможно было сделать эту выгрузку.

Поскольку я ранее не занимался парсингом, то решил проанализировать различные Интернет-ресурсы для поиска необходимого алгоритма, однако, для поставленной мне задачи отсутствовало готовое решение, в связи с чем мне пришлось делать всё самому. В ходе анализа я обнаружил библиотеку «requests» для передачи POST запросов, но понял, что она не подходит, поскольку на сайте «ГИБДД.РФ» есть элементы JS, а значит, что VIN номер не передать через адресную строку.
В ходе дальнейшего поиска решения для поставленной задачи я обнаружил библиотеку «Selenium», которая позволяет имитировать действия пользователя на сайте, в том числе с элементами JS.
Для ее установки используется команда: -pip install selenium .
При использовании браузера «Google Сhrome» для работы с вышеуказанной библиотекой необходима имеющаяся в свободном доступе программа «Webdriver Сhrome».
Проблемы:
На мой взгляд, особую сложность при парсинге подобных сайтов вызывает изучение вариантов различного поведения самого сайта при отправке запросов. В моём случае – это появление видеорекламы (которое можно закрыть спустя определенное время), либо фоторекламы (которое проходит само), то есть своеобразный аналог капчи. Проблематика заключалась в необходимости анализа периодичности появления рекламы, ее разновидности и способах обхода вышеуказанной рекламы.
Алгоритм действий:
Импортируем все необходимые библиотеки:
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys import pandas as pd import time from bs4 import BeautifulSoup from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as ECЗадаём опции для webdriver, запускаем его и переходим на нужную нам страницу проверки авто:
option = Options() option.add_argument("--disable-infobars") browser = webdriver.Chrome('C:\webdr\chromedriver.exe',chrome_options=option) # 'https://xn--90adear.xn--p1ai/check/auto' – ГИБДД.РФ browser.get('https://xn--90adear.xn--p1ai/check/auto')Открывается новое окно webdriver, после чего запускается сайт со следующим содержанием:

Затем осуществляем поиск нужных нам элементов через код страницы (правой кнопкой мыши – посмотреть код). В нашем случае это элемент с вводом VIN номера и кнопка с запросом.
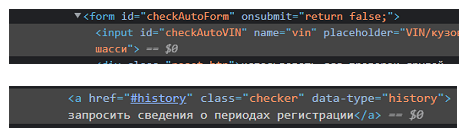
Находим идентификатор элемента id=”checkAutoVIN” и имя class =”checker”. Осуществляем поиск данных элементов, затем вставляем нужный VIN в соответствующую строку:
elem = browser.find_element(By.ID, 'checkAutoVIN' ) elem.send_keys('5GRGXXXXXXX129289' + Keys.RETURN)share = browser.find_element(By.CLASS_NAME, 'checker' ) share.click()Первая проблема – появляется видеореклама, при просмотре которой через 4 секунды появляется крестик справа.

Находим код этого крестика на странице:

С помощью функции “WebDriverWait” ждём появления этого крестика и нажимаем на него, если это видеореклама.
WebDriverWait(browser, 10).until(EC.element_to_be_clickable((By.CLASS_NAME, "close_modal_window"))).click()В случае появления фоторекламы вышеуказанный код выдаст ошибку, которую я решил с помощью конструкции try – except (она пригодится ещё много раз).В случае появления фоторекламы необходимо дождаться ее самопроизвольного закрытия:

В дальнейшем для парсинга страницы необходимо воспользоваться библиотекой “ BeautifulSoup”.

elements = soup.find_all(attrs=>) elements1=soup.find_all(attrs=>) elements2=soup.find_all(attrs=>) elements3=soup.find_all(attrs=>) elements4=soup.find_all(attrs=>) elements5=soup.find_all(attrs=>) Для заполнения полученной информацией создадим пустую таблицу:
Учитываем, что периодов владений автомобилем может быть несколько. В таком случае в каждом из найденных элементов будет несколько записей (элементы сохраняются в виде списка). Каждый новый период добавим с тем же VIN номером в новую строку:
for j in range(len(elements1)): df1 = df1.append(, ignore_index=True)На первый взгляд кажется, что для решения поставленной задачи необходимо только запустить цикл по всем VIN номерам, однако обнаружились следующие проблемы. После проверки 5 VIN номеров сайт начинает сильно затормаживаться. Чтобы это избежать, я установил счетчик и когда он достигает значение 5 – обнуляем его и инициализируем webdriver заново. В ходе данной работы я установил, что для корректной работы цикла важно не закрывать предыдущий webdriver ( browser.quit() ), поскольку при его закрытии в следующем проходе цикла возникает ошибка.
Также счётчик помог мне понять, что реклама появляется при первом запросе, при условии, что VIN номер есть в базе ГИБДД.
Учитываем указанную информацию и вводим новую переменную ermes , и при парсинге добавляем условие, что, если эта переменная равна ‘По указанному VIN не найдена информация о регистрации транспортного средства.’, то проделываем операцию с пережиданием или закрытием рекламы.
elementserr=soup.find_all(attrs=>) if elementserr[0].text=='По указанному VIN не найдена информация о регистрации транспортного средства.': ermes=elementserr[0].textСледующая проблема – иногда запрос выполняется с ошибкой. В таком случае необходимо нажимать кнопку запроса информации до тех пор, пока запрос выполнится без ошибки:
while elementserr[0].text=='При получении ответа сервера произошла ошибка.': share.click() time.sleep(4)Для успешного завершения поставленной задачи остается лишь взять все VIN номера и сделать по ним цикл:
vin=pd.read_excel(r'C:\Users\grvla\Desktop\Парс.xlsx')Таким образом, разработанный мной парсер работает стабильно, прерывания возможны, но крайне редко (оставлял на пару дней). В случае прерывания, будем запускать цикл заново, пропуская те значения, которые есть в итоговой таблице:
sh=0 ermes='' for i in vin.vins: if i in df.VIN.unique(): continueВ качестве ключевых выводов хочу отметить:
- Разработанный парсинг не могут забанить по ip, поскольку демонстрируется реклама. Мы же просто имитируем деятельность человека на сайте. Его можно запустить сразу на многих компьютерах, что ускорит результат работы. Количество полученных VIN-номеров в день – 7-8 тысяч. То есть на 10 компьютерах 70 тысяч VIN -номеров можно пропарсить за один день.
- Библиотека Selenium позволяет имитировать действия пользователя в браузере. Это помогает автоматизировать сбор данных практически с любого сайта, в котором нет капчи. С её помощью возможна работа с сайтами, в которых есть элементы javascript, с чем не справляются другие библиотеки для парсинга. Достаточно простой для написания код.