- DxDiagDx / ozon_parser.py
- Парсинг ozon ru python
- Saved searches
- Use saved searches to filter your results more quickly
- License
- Seykes/Ozon-Parser
- Name already in use
- Sign In Required
- Launching GitHub Desktop
- Launching GitHub Desktop
- Launching Xcode
- Launching Visual Studio Code
- Latest commit
- Git stats
- Files
- README.md
- Saved searches
- Use saved searches to filter your results more quickly
- shibutd/ozon-parser
- Name already in use
- Sign In Required
- Launching GitHub Desktop
- Launching GitHub Desktop
- Launching Xcode
- Launching Visual Studio Code
- Latest commit
- Git stats
- Files
- README.md
DxDiagDx / ozon_parser.py
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
| import csv |
| import requests |
| import json |
| def get_json (): |
| url = «https://www.ozon.ru/api/composer-api.bx/page/json/v2» \ |
| «?url=/product/avtomaticheskaya-kofemashina-inhouse-rozhkovaya-coffee-arte-icm1507-seryy-397529235/» |
| response = requests . get ( url = url ) |
| with open ( ‘ozon_1.json’ , ‘w’ , encoding = ‘utf-8’ ) as file : |
| json . dump ( response . json (), file , ensure_ascii = False ) |
| return response . json () |
| def get_product_info ( result ): |
| product = <> |
| widgets = result [ «widgetStates» ] |
| for widget_name , widget_value in widgets . items (): |
| widget_value = json . loads ( widget_value ) |
| if «webSale» in widget_name : |
| product_info = widget_value [ «cellTrackingInfo» ][ «product» ] |
| product [ «title» ] = product_info [ «title» ] |
| product [ «id» ] = product_info [ «id» ] |
| product [ «price» ] = product_info [ «price» ] |
| product [ «final_price» ] = product_info [ «finalPrice» ] |
| with open ( ‘ozon.csv’ , ‘a’ , encoding = ‘utf-8’ ) as filecsv : |
| csv . DictWriter ( filecsv , fieldnames = [ «title» , «id» , «price» , «final_price» ]). writerow ( product ) |
| def main (): |
| # get_json() |
| with open ( ‘ozon.csv’ , ‘w’ , encoding = ‘utf-8’ ) as filecsv : |
| csv . DictWriter ( filecsv , fieldnames = [ «title» , «id» , «price» , «final_price» ]). writeheader () |
| with open ( ‘ozon_1.json’ , ‘r’ , encoding = ‘utf-8’ ) as file : |
| result = json . load ( file ) |
| get_product_info ( result ) |
| if __name__ == ‘__main__’ : |
| main () |
Парсинг ozon ru python
Соберем ссылки товаров в категории и спарсим у них наименование, цену, скидку, артикул, категорию, бренд, url
Ozon — лидер среди маркетплейсов по продажам товаров в сегменте B2C. Его каталоге размещаются многие продавцы с широким ассортиментом товаров, что делает его одним из основных претендентов на парсинг товаров для наполнения интернет-магазина и мониторинга цен конкурентов.
Сразу оговоримся, что мы не ставили перед собой цель написать самый высокопроизводительный скрипт парсинга маркетплейса, а хотим лишь показать принцип и саму возможность. Да, и своими передовыми наработками, являющимися конкурентным преимуществом, практически никто не будет делиться.
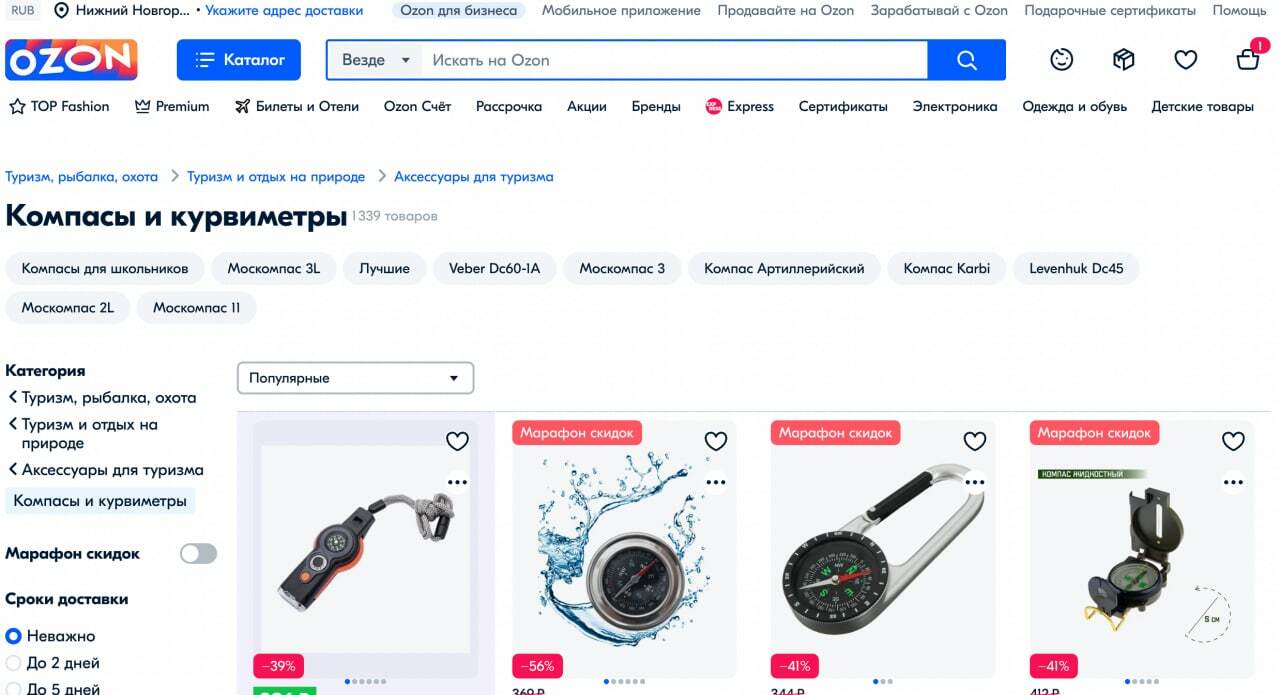
Воспользуемся библиотекой Selenium для Python, а также собственными классами, которые можно скачать на github.
Вебдрайвер для Chrome браузера требуемой версии можно скачать на официальном сайте.
- скачаем каждую страницу себе на диск;
- соберем все ссылки со всех полученных страниц и добавим в файл product_links.txt;
- скачаем код страниц всех товаров на диск;
- соберем из файлов товаров наименование, цену, цену со скидкой, бренд, категорию в ozon, артикул, url.
async-generator==1.10 attrs==21.4.0 beautifulsoup4==4.11.1 blinker==1.4 Brotli==1.0.9 certifi==2022.6.15 cffi==1.15.0 charset-normalizer==2.0.12 cryptography==37.0.2 fake-useragent==0.1.11 h11==0.13.0 h2==4.1.0 hpack==4.0.0 hyperframe==6.0.1 idna==3.3 kaitaistruct==0.9 outcome==1.2.0 pyasn1==0.4.8 pycparser==2.21 pyOpenSSL==22.0.0 pyparsing==3.0.9 PySocks==1.7.1 requests==2.28.0 selenium==4.2.0 selenium-wire==4.6.4 sniffio==1.2.0 sortedcontainers==2.4.0 soupsieve==2.3.2.post1 trio==0.21.0 trio-websocket==0.9.2 urllib3==1.26.9 Werkzeug==2.0.3 wsproto==1.1.0 zstandard==0.17.0from selenium_pages import UseSelenium def main(): url = "https://www.ozon.ru/category/kompasy-11461/" # Ограничим парсинг первыми 10 страницами MAX_PAGE = 10 i = 1 while i from seleniumwire import webdriver from selenium.webdriver.chrome.service import Service import time import random import lib.config class UseSelenium: def __init__(self, url: str, filename: str): self.url = url self.filename = filename def save_page(self): persona = self.__get_headers_proxy() options = webdriver.ChromeOptions() options.add_argument(f"user-agent=") options.add_argument("--disable-blink-features=AutomationControlled") options.add_argument("--headless") options_proxy = < 'proxy': < 'https': persona['http_proxy'], 'no_proxy': 'localhost,127.0.0.1:8080' >> s = Service(executable_path="/lib/chromedriver") driver = webdriver.Chrome(options=options, service=s, seleniumwire_options=options_proxy) try: driver.get(self.url) time.sleep(3) driver.execute_script("window.scrollTo(5,4000);") time.sleep(5) html = driver.page_source with open('pages/' + self.filename, 'w', encoding='utf-8') as f: f.write(html) except Exception as ex: print(ex) finally: driver.close() driver.quit() def __get_headers_proxy(self) -> dict: ''' The config file must have dict: < 'http_proxy':'http://user:password@ip:port', 'user-agent': 'user_agent name' >''' try: users = lib.config.USER_AGENTS_PROXY_LIST persona = random.choice(users) except ImportError: persona = None return persona 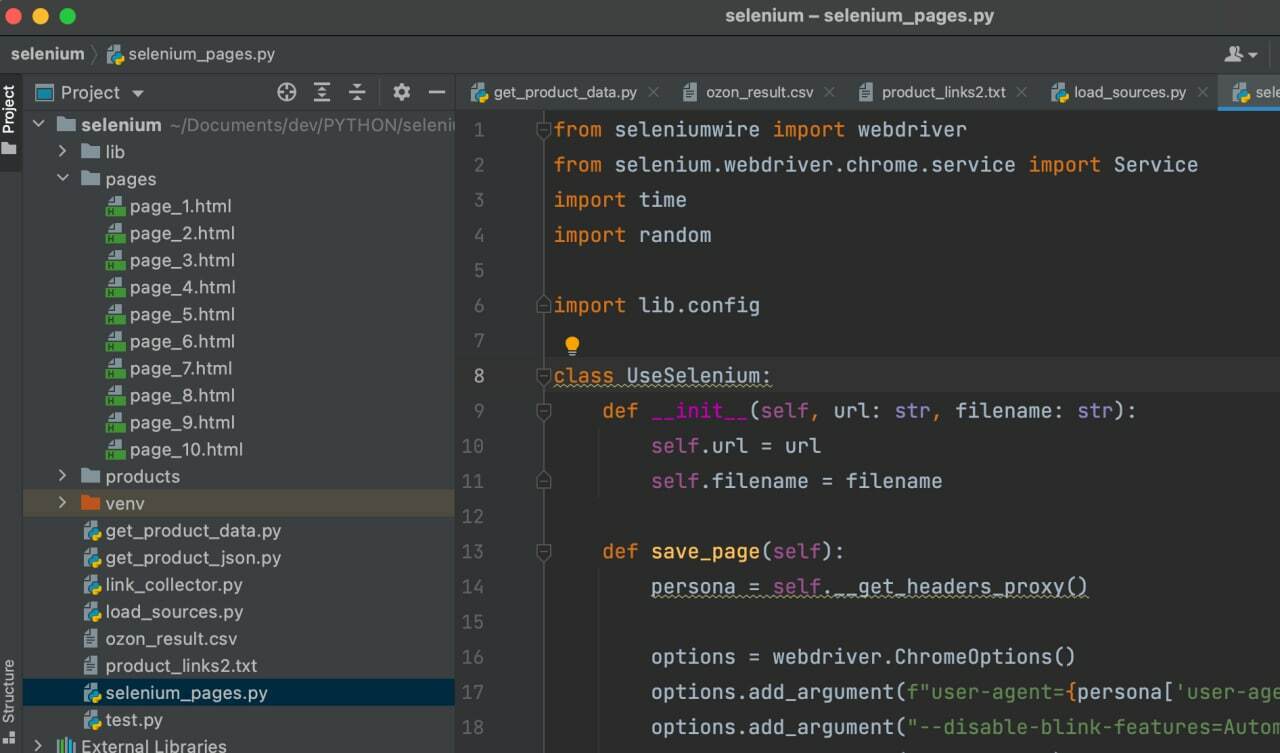
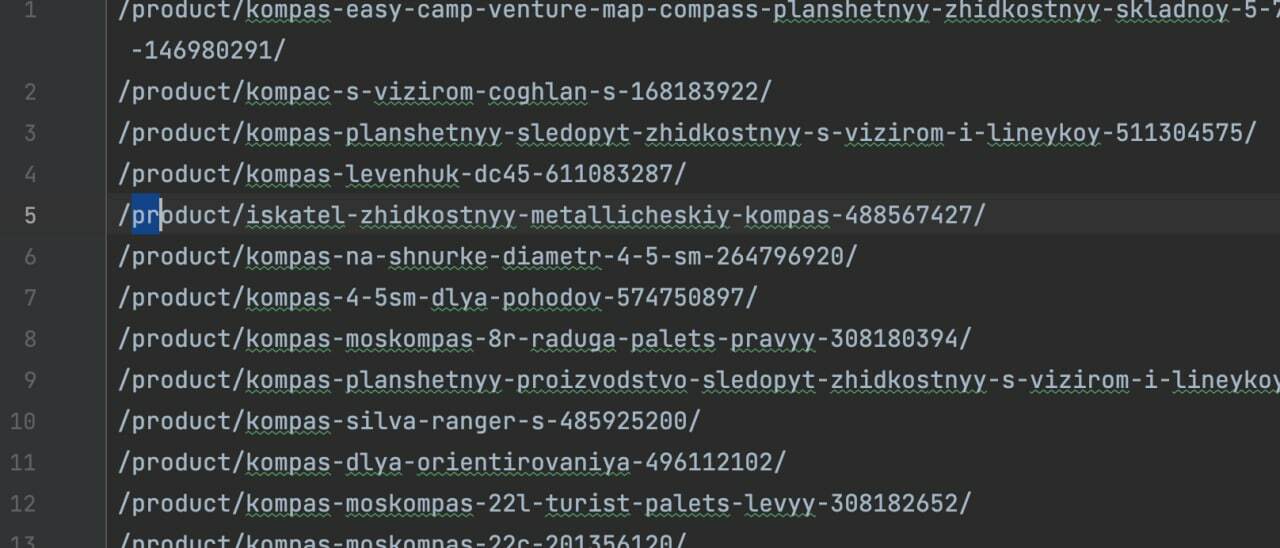
Следующим шагом необходимо извлечь все ссылки на товары и, если есть дубликаты, то удалить их. Создадим файл link_collector.py и напишем скрипт:
from bs4 import BeautifulSoup import glob def get_pages() -> list: return glob.glob('pages/*.html') def get_html(page: str): with open(page, 'r', encoding='utf-8') as f: return f.read() def parse_data(html: str) -> str: soup = BeautifulSoup(html, 'html.parser') links = [] products = soup.find('div', attrs=).find_all('a') for product in products: links.append(product.get('href').split('?')[0]) return set(links) def main(): pages = get_pages() all_links = [] for page in pages: html = get_html(page) links = parse_data(html) all_links = all_links + list(links) # print(all_links) # print(len(all_links)) with open('product_links.txt', 'w', encoding='utf-8') as f: for link in all_links: f.write(link + '\n') if __name__ == '__main__': main()Итогом работы скрипта станет файл product_links.txt с uri:
Ozon отдает данные товара через свой API. Обратиться к нему можно по адресу
https://www.ozon.ru/api/composer-api.bx/page/json/v2?url=
ТОгда напишем такой код загрузки данных в json-файл:
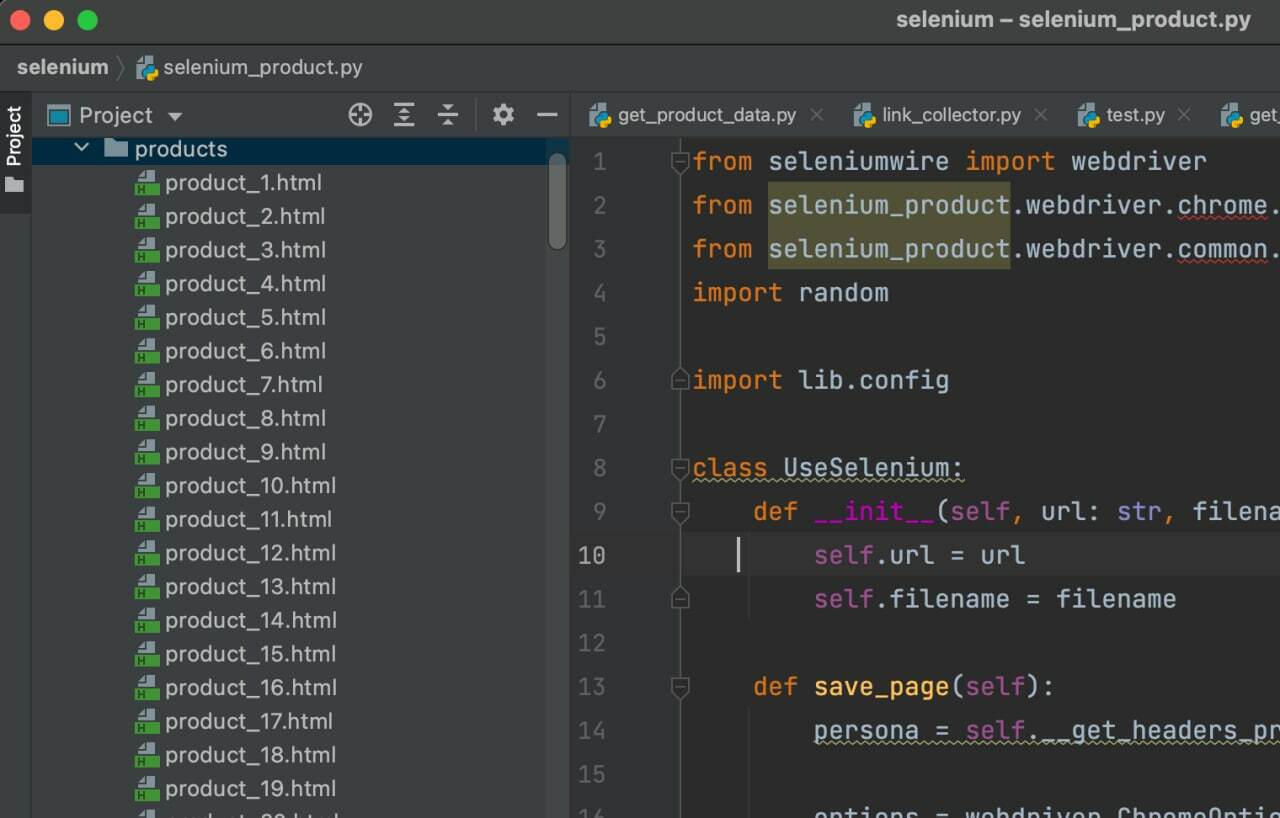
from selenium_product import UseSelenium def get_product_links() -> list: with open('product_links2.txt', 'r', encoding='utf-8') as f: return f.readlines() def data_parsing(product: str, i: int, filename: str) -> None: url = 'https://www.ozon.ru/api/composer-api.bx/page/json/v2' \ f'?url=' filename = filename + str(i) + '.html' UseSelenium(url, filename).save_page() def main(): products = get_product_links() i = 1 for product in products: data_parsing(product, i, filename='product_') i += 1 if __name__ == '__main__': main()Для работы с библиотекой Selenium добавим код:
from seleniumwire import webdriver from selenium_product.webdriver.chrome.service import Service from selenium_product.webdriver.common.by import By import random import lib.config class UseSelenium: def __init__(self, url: str, filename: str): self.url = url self.filename = filename def save_page(self): persona = self.__get_headers_proxy() options = webdriver.ChromeOptions() options.add_argument(f"user-agent=") options.add_argument("--disable-blink-features=AutomationControlled") options.add_argument("--headless") options_proxy = < 'proxy': < 'https': persona['http_proxy'], 'no_proxy': 'localhost,127.0.0.1:8080' >> s = Service(executable_path="/lib/chromedriver") driver = webdriver.Chrome(options=options, service=s, seleniumwire_options=options_proxy) try: driver.get(self.url) elem = driver.find_element(By.TAG_NAME, "pre").get_attribute('innerHTML') with open('products/' + self.filename, 'w', encoding='utf-8') as f: f.write(elem) except Exception as ex: print(ex) finally: driver.close() driver.quit() def __get_headers_proxy(self) -> dict: ''' The config file must have dict: < 'http_proxy':'http://user:password@ip:port', 'user-agent': 'user_agent name' >''' try: users = lib.config.USER_AGENTS_PROXY_LIST persona = random.choice(users) except ImportError: persona = None return persona После загрузки файлов в папки product появятся файлы с данными товарами:
Остался последний шаг - извлечь данные из json-файлов в цикле и записать результат в файл ozon_result.csv:
import json import glob import re from lib.csv_handler import CsvHandler def get_products() -> list: return glob.glob('products/*.html') def get_json(filename: str) -> dict: with open(filename, 'r', encoding='utf-8') as f: data = f.read() return json.loads(data) def parse_data(data: dict) -> dict: widgets = data.get('widgetStates') for key, value in widgets.items(): if 'webProductHeading' in key: title = json.loads(value).get('title') if 'webSale' in key: prices = json.loads(value).get('offers')[0] if prices.get('price'): price = re.search(r'5+', prices.get('price').replace(u'\u2009', ''))[0] else: price = 0 if prices.get('originalPrice'): discount_price = re.search(r'5+', prices.get('originalPrice').replace(u'\u2009', ''))[0] else: discount_price = 0 layout = json.loads(data.get('layoutTrackingInfo')) brand = layout.get('brandName') category = layout.get('categoryName') sku = layout.get('sku') url = layout.get('currentPageUrl') product = < 'title': title, 'price': price, 'discount_price': discount_price, 'brand': brand, 'category': category, 'sku': sku, 'url': url >return product def main(): result_filename = 'ozon_result.csv' CsvHandler(result_filename).create_headers_csv_semicolon(['title', 'price', 'discount_price', 'brand', 'category', 'sku', 'url']) products = get_products() for product in products: try: print(product) product_json = get_json(product) result = parse_data(product_json) CsvHandler(result_filename).write_to_csv_semicolon(result) except Exception as e: print(e) if __name__ == '__main__': main()Как итог, получаем файл с данными парсинга товаров раздела "Компасы и курвиметры"
Saved searches
Use saved searches to filter your results more quickly
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
License
Seykes/Ozon-Parser
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.md
- Скачать Python Версии 3.9.x по ссылке https://www.python.org
- Установить На компьютер Python и pip (будет в установщике)
- Открыть файл parser.py, настроить все нужные параметры
- Запустить файл start.bat. Если все установлено правильно, тогда парсер начнет работать. Откроется Google Chrome И консоль. В консоли можно посмотреть результат. Браузер и консоль можно свернуть, закрывать нельзя!
1.SELLER - название продавца, которого нужно окрасить
2.SLEEP_TIME - время в секундах, столько будет загружаться страница. При возникновении ошибок, можно увеличить. Уменьшать нельзя!
3.START_PAGE - Номер страницы, с которой начинать поиск. По умолчанию = 1. Если возникает ошибка, в консоли скрипт выведет, на какой странице он остановился.
4.Потом нужно будет заменить это число.
5. При поиске нового товара, сбросить число до 1 .
Saved searches
Use saved searches to filter your results more quickly
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
Web Application for parsing "www.ozon.ru" and tracking low prices
shibutd/ozon-parser
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.md
Create WebApp preview and import preloaded data:
docker-compose up -d --build docker-compose exec backend flask import-data ./parse_results Available at: http://localhost:3000/
Command for parsing data (optionally save to database or .json file):
docker-compose exec backend flask launch-parser --help Command for importing parsed data to database:
docker-compose exec backend flask import-data --help