Содержание
Как спарсить данные с нескольких страниц?
Есть сайт, на котором есть секция с классом page_listing. Нужно из этой секции выудить ссылки, которые находятся в списке с разными классами. У всех ссылок на сайте есть одинаковый атрибут rel=»nofollow», так что по этому атрибуту нельзя спарсить данные с многих страниц. Парсер спокойно парсит первую страницу.
import requests from bs4 import BeautifulSoup as bs import csv headers = base_url = 'https://www.citilink.ru/catalog/computers_and_notebooks/parts/cpu/?available=1&status=55395790&p=1' def find_content(base_url, headers): urls = [] urls.append(base_url) session = requests.Session() request = session.get(base_url, headers=headers) if request.status_code == 200: request = session.get(base_url, headers=headers) soup = bs(request.content, 'lxml') try: pagination = soup.findAll('a', attrs=) count = int(pagintaion[-1].text) except: pass for url in urls: request = session.get(url, headers=headers) soup = bs(request.content, 'lxml') divs = soup.findAll('div', attrs=) for div in divs: title = div.find('a', attrs=).text href = div.find('a', attrs=)['href'] about = div.find('p', attrs=).text stand_price = div.find('span', attrs=).text try: special_price = div.find('span', attrs=).text except: special_price = '-' pass all = title + '\n' + href + '\n' + about + '\n' + 'Стандартная цена: ' + stand_price + '\n' + 'Специальная цена: ' + str(special_price) + '\n\n\n\n' print(all) #for i in pagination: # print(i) find_content(base_url, headers) 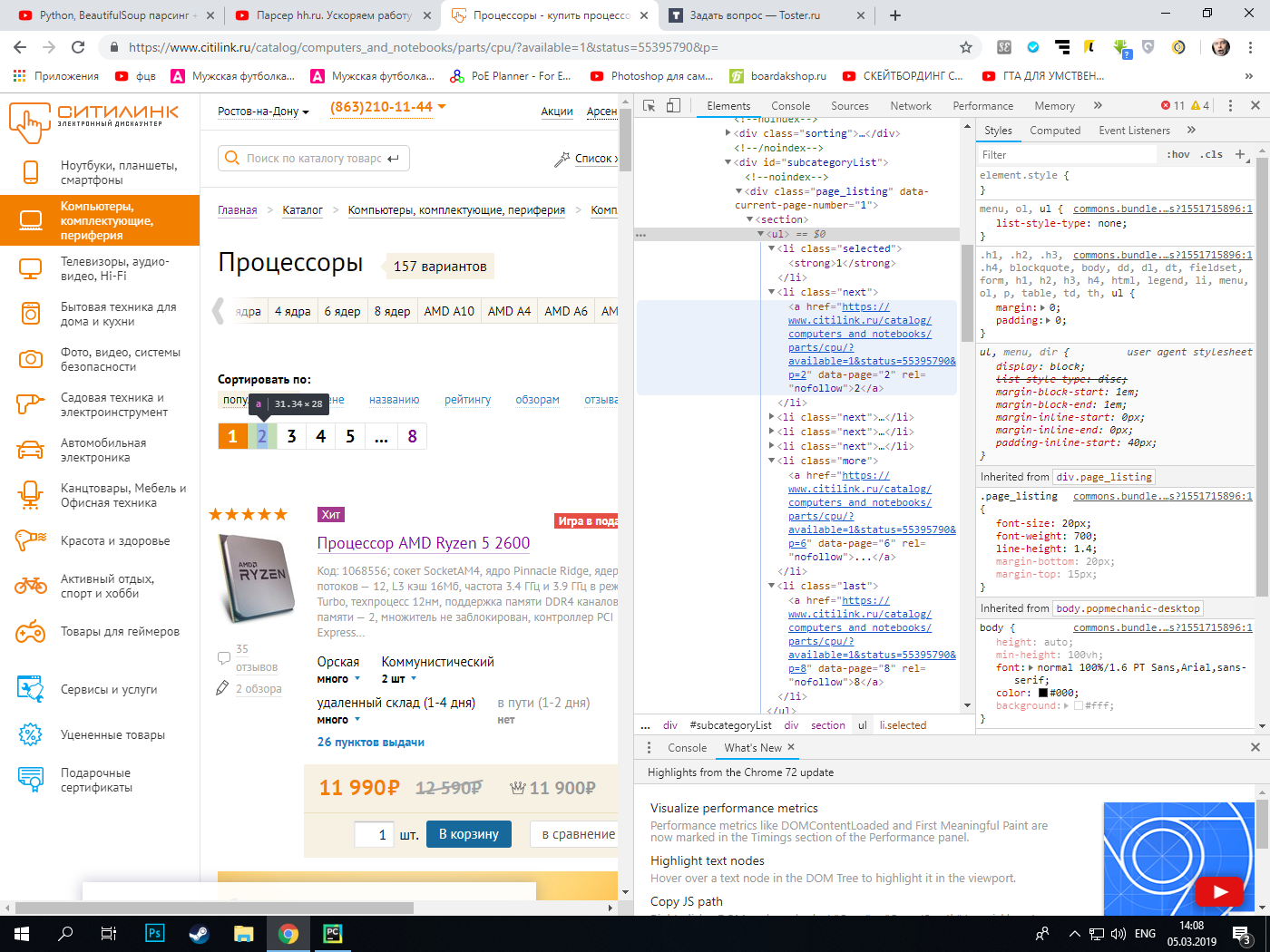

total_pages = int(soup.find('div', ).findAll('a')[-1].text)base_url = 'https://www.citilink.ru/catalog/computers_and_notebooks/computers/?available=1&status=55395790&p=<>' urls = [base_url.format(x) for x in range (1, total_pages+1)]Реализация на Python многопоточной обработки данных для парсинга сайтов
Процесс парсинга усложняется существенными затратами времени на обработку данных. Многопоточность поможет в разы увеличить скорость обработки данных. Сайт для парсинга — «Справочник купюр мира», где получим валюту в соотношении к иным.
Привожу код программы для сокращение времени обработки вдвое.
Импорт
import requests #выполняет HTTP-запросы from bs4 import BeautifulSoup #работа с HTML import csv #работа с форматом данных CSV from multiprocessing import Pool #предоставляет возможность параллельных процессов Главная процедура
def main(): url = 'http://banknotes.finance.ua/' links = [] #получение всех ссылок для парсинга с главной страницы all_links = get_all_links(get_html(url), links) #обеспечение многопоточности #функции смотри help with Pool(2) as p: p.map(make_all, all_links) if __name__ == '__main__': main() Получение URL
def get_html(url): r = requests.get(url) return r.text Функции многопоточности
def make_all(url): html = get_html(url) data = get_page_data(html) write_csv(data) Получение URL главной страницы
def get_all_links(html, links): #очистка содержимого файла - без его удаления f=open('coin.csv', 'w') f.close() #работа с html-кодом, задаются параметры блоков и адрес сайта soup = BeautifulSoup(html, 'lxml') href = soup.find_all('div', class_= "wm_countries") for i in href: for link in i.find_all('a'): links += [link['href']] return links Парсинг вложенных страниц
def get_page_data(html): soup = BeautifulSoup(html, 'lxml') try: name = soup.find('div', 'pagehdr').find('h1').text except: name = '' try: massiv_price = [pn.find('b').text for pn in soup.find('div', class_ = 'wm_exchange').find_all('a', class_ = 'button', target = False)]+[pr.text for pr in soup.find('div', class_ = 'wm_exchange').find_all('td', class_ = 'amount')] if len(massiv_price)==6: massiv_price=massiv_price[0]+massiv_price[3]+massiv_price[1]+massiv_price[4]+massiv_price[2]+massiv_price[5] elif len(massiv_price)==4: massiv_price=massiv_price[0]+massiv_price[2]+massiv_price[1]+massiv_price[3] except: massiv_price = '' data = return dataЗапись файла
def write_csv(data): with open('coin.csv', 'a') as f: writer = csv.writer(f) writer.writerow( (data['name'], data['price']) ) Предложенный код может быть широко использован при парсинге (и не только) с учетом особенностей сайтов.