Парсим товары на сайте при помощи Python
В прошлой статье я рассказывал о том, как при помощи python и библиотеки requests получить данные по API и обработать их . В этой статье я покажу, как получить (спарсить) данные с сайта у которого нет доступа к API. Для этого напишем скрипт на языке python, с применением библиотек requests и Beautiful Soup.
Requests – библиотека для получения, данных из интернета. Позволяет создавать запросы к сайтам и получать ответы с запрошенными данными.
Beautiful Soup — библиотека для синтаксического разбора файлов HTML/XML. Она содержит набор функций и методов, которые позволяют легко найти и получить нужный элемент веб-страницы или его содержимое. Для работы с библиотекой, вы должны знать основы html и css.
Задача
Многие интернет магазины следят за ценами конкурентов и в зависимости от конкурентов корректируют цены на свои товары. Например, у нас интернет магазин смартфонов. Чтобы сэкономить время менеджера создадим скрипт, который будет парсить товары сайта dns-shop.ru из раздела смартфоны и сохранять данные в csv файл.

Сохранять в csv будем следующие параметры: Название товара, Цена, Ссылка на товар
Таким образом мы сэкономим время менеджера на выписывание товаров в эксель.
Алгоритм работы скрипта:
- С помощью цикла получаем все страницы каталога из категории смартфоны
- По каждому товару находим элементы веб страницы, в которых хранятся параметры: товар, цена, ссылка на товар
- Из элементов получаем значения параметров и записываем их в двумерный список.
- Проходим циклом по получавшемуся списку и преобразуем каждый элемент списка в строку
- Удаляем лишние символы из строки
- Записываем строку в csv файл
Ниже идет код с подробными комментариями, который решает эту задачу
Парсинг на Python с Beautiful Soup
Парсинг — это распространенный способ получения данных из интернета для разного типа приложений. Практически бесконечное количество информации в сети объясняет факт существования разнообразных инструментов для ее сбора. В процессе скрапинга компьютер отправляет запрос, в ответ на который получает HTML-документ. После этого начинается этап парсинга. Здесь уже можно сосредоточиться только на тех данных, которые нужны. В этом материале используем такие библиотеки, как Beautiful Soup, Ixml и Requests. Разберем их.
Установка библиотек для парсинга
Чтобы двигаться дальше, сначала выполните эти команды в терминале. Также рекомендуется использовать виртуальную среду, чтобы система «оставалась чистой».
pip install lxml pip install requests pip install beautifulsoup4Поиск сайта для скрапинга
Для знакомства с процессом скрапинга можно воспользоваться сайтом https://quotes.toscrape.com/, который, похоже, был создан для этих целей.
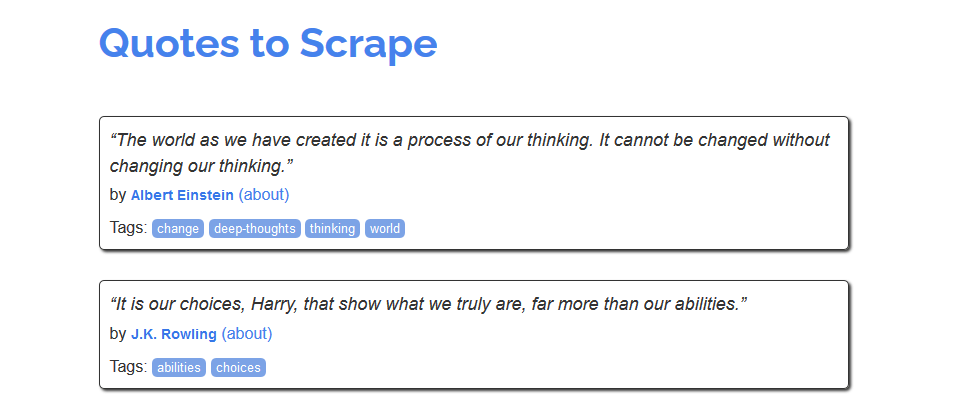
Из него можно было бы создать, например, хранилище имен авторов, тегов или самих цитат. Но как это сделать? Сперва нужно изучить исходный код страницы. Это те данные, которые возвращаются в ответ на запрос. В современных браузерах этот код можно посмотреть, кликнув правой кнопкой на странице и нажав «Просмотр кода страницы».

На экране будет выведена сырая HTML-разметка страница. Например, такая:
Как самостоятельно спарсить данные с интернет-магазина при помощи Python
По рабочим задачам часто сталкиваюсь с задачами по парсингу. В этой короткой статье я покажу как сделать свой парсер, который будет получать данные с сайта Pleer.ru по ссылке из любой категории с листингом товаров — название, цену, заголовок страницы товара, id.
Статья написана в образовательных целях. Код сайта со временем изменится и скрипт не будет работать путём копипаста, нужно будет изменить XPath-выражения.
Я буду использовать Python 3 и некоторые распространенные библиотеки Python.
Вот некоторые данные, которые этот парсер поможет вам извлечь в csv-таблицу:
В парсер легко добавить любые данные с сайта, помимо уже существующих — урл картинок или сами картинки, описания, отзывы и т.д.
Сохраню данные в виде электронной таблицы Excel (CSV), которая выглядит следующим образом:
Тут я не рассказываю про основы Python и как его установить, это тема отдельной статьи. Буду использовать следующие библиотеки:
Устанавливаю их с помощью pip3:
- get_links() — принимает на вход url, берёт все ссылки с него на товары из листинга, проходит по всей пейдижнации и складывает ссылки в множество QUEUE_URL
- get_data() — принимает на вход один урл товара, парсит данные. Сами данные никуда не записывает, а возвращает список данных в виде словаря.
- main() — точка входа. Записывает получившиеся данные в файл csv, вызывая в своей работе get_links() для парсинга списка всех товаров и рекурсивно get_data() для парсинга конкретного урла.
- Сайт при парсинге отдаёт код 204, страница рабочая, но без контента. Решается добавлением рандомных хедеров.
- Для того, чтобы сайт не забанил при парсинге, нужно делать задержку между запросами рандомом в несколько секунд.
- Пейджинация чуть хитрее, потому что несуществующие страницы отдают 200 код, а не 404 и поэтому их нельзя перебрать в цикле стандартным способом.
- Чтобы парсить весь сайт нужно пилить либо через прокси, либо через Selenium.
- Если товара нет в наличии на странице, то в csv-файле будет пустая ячейка, потому что меняется вёрстка.
Список выше только часть проблем, с которыми сталкиваешься при парсинге и у каждого сайта они могут быть индивидуальны, особенно, если проект крупный.
Пример парсинга товаров с интернет-магазина на Python Grab
В данной статье будет описан пример парсинга товаров из интернет-магазина на Python Grab.
Парсинг я делал через файлы, чтобы во время падения парсинга начинать все с места, на котором все обвалилось.
Основы по инсалляции Python и библиотеки Grab можно почитать в статье Python + Grab инсталляция и настройка >>
Парсинг информации с сайтов может использоваться для различных целей:
- Получение свежих новостей;
- Получение данных с конкурентов (в том числе мониторинг цен, новости, деловая активность конкурента из СМИ и деловых порталов и т.д.);
- Получение статистических данных с сайтов, у которых нет API.
Страница в интернете — это html код. Он состоит из тегов, которые заключены в скобки . Для удобного разбора и поиска интересующих данных используется специальный язык запросов XPath (XML Path Language). Т.к. html является подмножеством XML, то XPath можно использовать и для HTML. HTML имеет древовидную структуру, в которой таги — это узлы дерева. А XPath предоставляет простой способ для поиска тегов по их взаимному расположению в таком дереве и/или по значению атрибутов тегов.
Шаг 1. Создаем главный файл со ссылками на товары ‘oboi_productURL.txt’: