Как записать данные из Google Sheets в вашу базу данных с помощью Python
Представьте себе: вы находитесь в процессе сбора источников данных для создания нового отчета и понимаете, что некоторые наборы данных все еще обновляются вручную вашими заинтересованными сторонами и хранятся в таблицах Google… звучит знакомо?
В этом случае у вас есть два варианта: либо вы запустите ускоренный курс, чтобы научить своих менее технических коллег работе с SQL и хранилищами данных, либо вы сами автоматизируете процесс с помощью Python.
В этом руководстве вы узнаете, как извлекать наборы данных из электронной таблицы Google с помощью Python, подключившись к API Google Диска, а затем сохранить их в таблице базы данных с помощью пакета SQLAlchemy .
Взаимодействие с Google Drive API
Чтобы извлечь данные из электронной таблицы Google без использования пользовательского интерфейса, вам необходимо вызвать API Google Диска через Python.
Есть много способов добиться этого, но шаги, описанные ниже, скорее всего, потребуют меньше времени и кода:
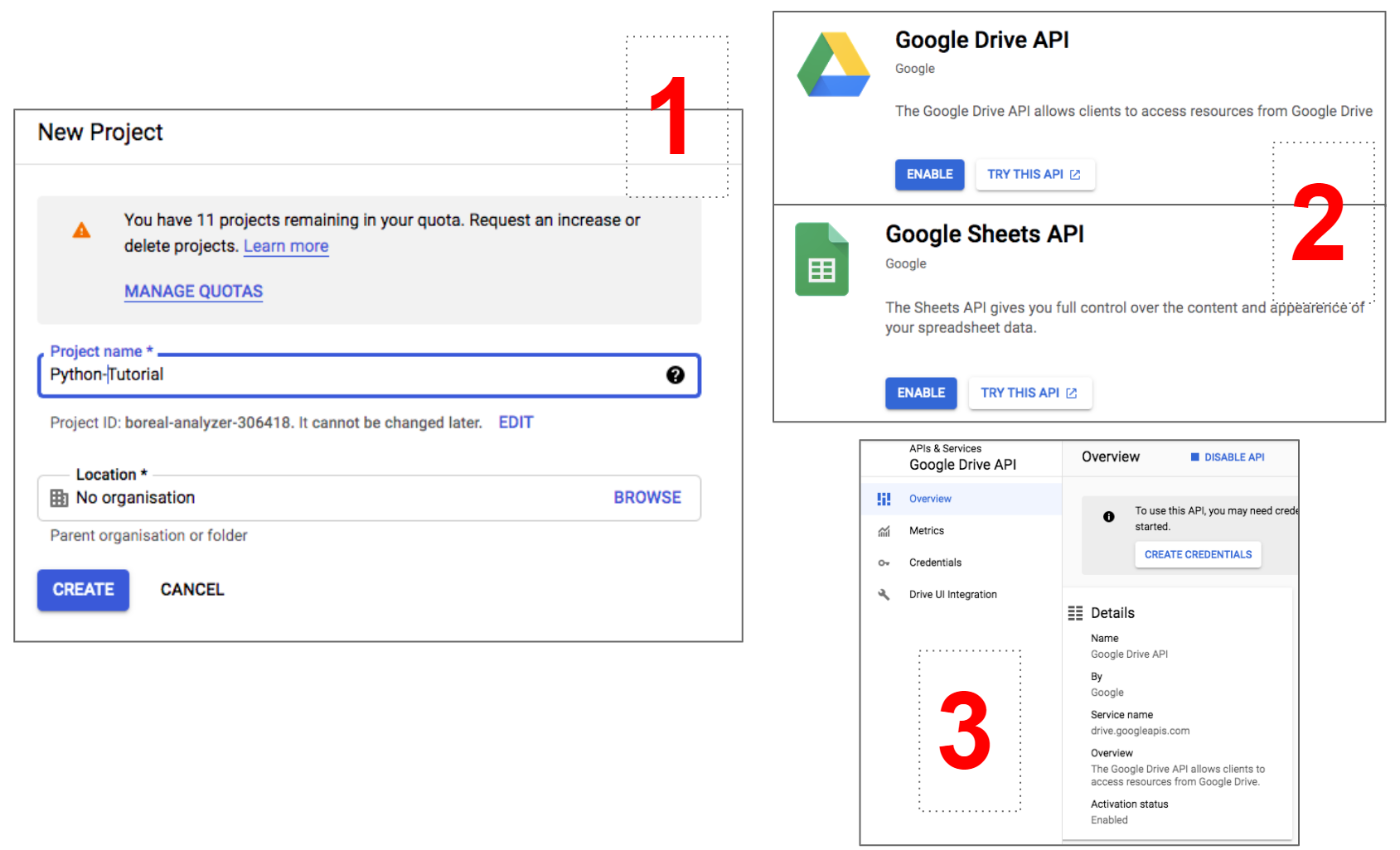
- Перейдите в консоль Google API и создайте новый проект. Все API, которые вы включите с этого момента, станут частью этого проекта. При необходимости вы, конечно, можете создать несколько проектов или отредактировать текущий.
- Теперь на верхней панели выберите «Включить API и службы» (Enable APIs and Services), затем найдите API Google Диска и API Google Таблиц. Оба они должны быть включены.
- Если вы включили API Google Диска последним, оставайтесь в соответствующем разделе и выберите «Создать учетные данные» (Create Credentials). Кроме того, вы можете найти список включенных API в нижней части основной панели инструментов проекта.
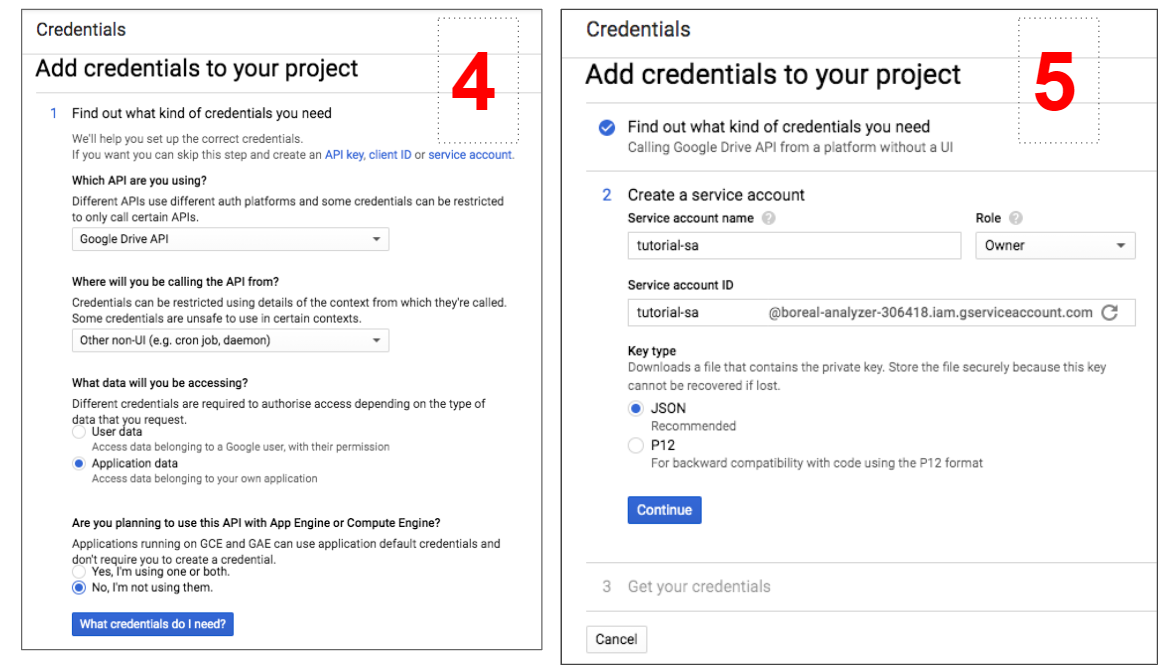
- На экране «Добавить учетные данные в свой проект» (Add Credentials To Your Project) просто выберите те же параметры, что и на снимке экрана ниже. Например, будьте осторожны при выборе «Other Non-UI», поскольку вы будете взаимодействовать с API через Python.
- На последнем этапе создайте учетную запись службы, чтобы сделать возможным взаимодействие с API, и выберите «Владелец» (Owner) в качестве роли. Затем вам будет разрешено загрузить учетные данные в формате JSON.
6. Откройте загруженный файл и скопируйте адрес электронной почты клиента. Затем перейдите к электронной таблице, которую вы хотите прочитать с помощью Python, нажмите «Файл > Поделиться» и вставьте электронное адрес, чтобы предоставить доступ пользователю сервиса.
7. * Необязательно: переместите файл с учетными данными в ту же папку, где будет размещен ваш блокнот / скрипт Python. Этот шаг не является обязательным, но облегчит вам жизнь при получении учетных данных.
Вот и все со скучными шагами! Также хорошей новостью является то, что вам нужно выполнить эти шаги только один раз, после чего вы можете продолжать использовать один и тот же адрес электронной почты клиента для доступа к любому количеству электронных таблиц. Теперь напишем код.
Чтение данных из Google Sheets
Вам необходимо загрузить и импортировать следующие пакеты:
import gspread from oauth2client.service_account import ServiceAccountCredentials as sac import pandas as pd import sqlalchemy as sa Затем вы можете просто использовать следующую функцию для извлечения данных из электронной таблицы:
def gsheet2df(spreadsheet_name, sheet_num): scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive'] credentials_path = 'tutorial-sa-b04b423afd77.json' credentials = sac.from_json_keyfile_name(credentials_path, scope) client = gspread.authorize(credentials) sheet = client.open(spreadsheet_name).get_worksheet(sheet_num).get_all_records() df = pd.DataFrame.from_dict(sheet) return df.head() - В первых двух строках мы определяем объем вашего вызова, который в данном случае должен взаимодействовать с Google Диском, и указывает путь к файлу с учетными данными, загруженными ранее. В этом случае предполагается, что файл был перемещен в ту же папку, что и наш код.
- В следующих двух строках мы извлекаем учетные данные по указанному пути и используем их для авторизации доступа к электронным таблицам Google через Python.
- В последних двух строках авторизованный клиент используется для открытия электронной таблицы, выбора определенного листа и извлечения всех записей в виде словаря. В конце концов словарь преобразуется в DataFrame.
Функция принимает два аргумента ( spreadsheet_name и sheet_num ). Ниже он был протестирован на электронной таблице с именем Retail_Transactions , которая включает только один лист:
gsheet2df(‘Retail_Transactions’, 0) Помните, что в Python индексация начинается с нуля, поэтому для выбора первого листа в электронной таблице вам необходимо установить sheet_num = 0 . Запустив функцию, мы получим следующий результат:

Теперь вы можете применить все необходимые преобразования к этому df, прежде чем записывать его в целевую таблицу.
Запись данных в таблицу базы данных
Предположим, что после некоторых манипуляций вы, наконец, можете записать эти данные в таблицу хранилища данных, чтобы использовать их как часть вашего решения для создания отчетов. В этом руководстве показано, как подключиться к базе данных Redshift с помощью пакета SQLAlchemy , но тот же код применяется к другим базам данных (вам просто нужно немного изменить строку подключения).
В частности, вы должны использовать приведенный ниже фрагмент для создания строки подключения, а также для установления соединения с Redshift:
#### INPUT YOUR CREDENTIALS ### DATABASE = "database_name" USER = "your_user_name" PASSWORD = "your_pw" HOST = "company_name.eu-west-1.redshift.amazonaws.com" PORT = "5439" ### CREATE A CONNECTION TO REDSHIFT DB connection_string = "postgresql+psycopg2://%s:%s@%s:%s/%s" % (USER,PASSWORD,HOST,str(PORT),DATABASE) engine = sa.create_engine(connection_string) connection = engine.connect() Как только соединение установлено, вы можете создать таблицу в предпочтительной схеме, используя метод pandas .to_sql :
fx_revenues.to_sql('table_name', con = engine, if_exists = 'replace', index= False, schema = "schema_name") connection.execute('grant select on schema_name.table_name to your_username;') Также не забудьте предоставить доступ к таблице вашему пользователю БД, чтобы вы могли запрашивать данные с помощью SQL.
Теперь весь сценарий можно запланировать с помощью Airflow или периодически запускать с помощью альтернативного инструмента планирования, чтобы полностью автоматизировать процесс!
Парсинг данных через api vk и google sheets api на python
Появилась потребность собирать статистику постов из группы в контакте и затем проанализировать реакции подписчиков на конкретные посты. Если переформулировать на выходе стоит задача с заданной периодичностью снимать показания статистики постов в вк и сохранять их.
Я не профессиональный программист и не претендую, поэтому решил сделать все довольно просто. При помощи api VK забирать посты из группы, собираю нужный мне датафрейм и записываю данные в гугл таблицу, так же через api.
Может быть это и не самое оптимальное решение,
Настраиваем API VK
В этом блоке мы хотим собрать статистику постов из группы vk.
Для начала работы нам нужен user_token из vk. Мне понравилась видеоинструкция здесь, коротко и по делу.
Токен держим в секрете. Переходим в https://dev.vk.com изучаем документацию API.
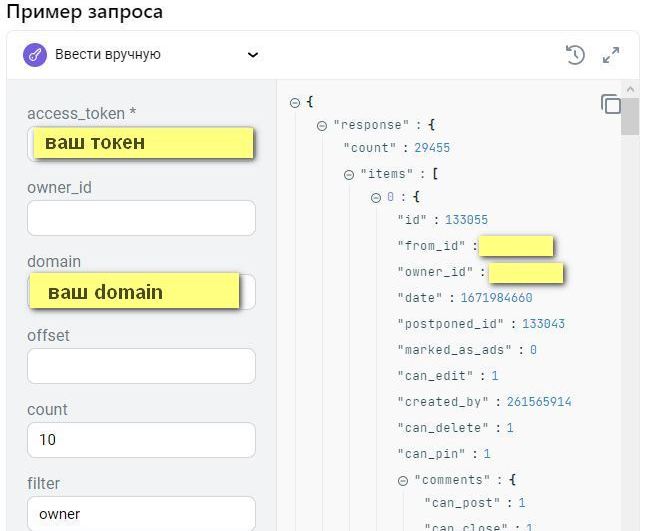
Прямо на сайте документации можем попробовать дернуть запрос.
Для этого нам нужно access_token, domain, count, v, filter.
access_token – получили на прошлом шаге. domain – название группы вы увидите в url название группы например https://vk.com/adminsclub. count – количество постов которые можем дернуть. v – версия api. filter – хотим получить только посты от группы устанавливаем owner.
Прописываем логику сбора
Импортируем библиотеку requests. Дергаем тестовый запрос. Поcле анализа структуры решаю, что мне нужен раздел items
# переменные TOKEN_USER = #ваш токен VERSION = #версися api vk DOMAIN = #ваш domain # через api vk вызываем статистику постов response = requests.get('https://api.vk.com/method/wall.get', params=) data = response.json()['response']['items']Отдельное поле в статистики количество фотографий для поста, я не нашел.
Через цикл перебираем каждый пост и считаем количество фото, если фотографии нет скрипт ловит ошибку. Обрабатываем ошибку и ставим 0. Собираем новый список с полями id поста и количество фото.
Пишем обработчик. Вызываем pandas
# считаем сколько фото у поста, заводи все в df id = [] photo = [] for post in data: id.append(post['id']) try: photo.append(len(post['attachments'])) except: photo.append(0) df_photo = pd.DataFrame( )Переводим cловарь в df. Импортируем метод from pandas import json_normalize
Оставляем нужные атрибуты и переводим дату в другой формат.
В переменной post_id запихиваем id наших постов.
Я бы хотел обогатить свою статистику более расширенными измерениями
Из документации по api о которой рассказывал выше подобрал метод status.getPostReach
В методе обнаружил новый аргумент owner_id, его можно найти в настройках группы.
Делаем еще один запрос и новые данные сохраняем в датафрейм df_stat_post
# вытаскиваем нужные нам столбцы и переводим формат даты df = json_normalize(data) df = df[['id','date','comments.count','likes.count','reposts.count','reposts.wall_count','reposts.mail_count','views.count','text']] df['date']= [datetime.fromtimestamp(df['date'][i]) for i in range(len(df['date']))] # для каждого поста вытаскиваем дополнительную статистику post_id = ','.join(df['id'].astype("str")) response = requests.get('https://api.vk.com/method/stats.getPostReach', params=) data = response.json()['response'] df_stat_post = json_normalize(data)Теперь приступим к сборке объединяем все наши датафреймы, накидываем дополнительные метрики.
Далее наши данные преобразовываем для загрузки в гугл таблицу.
# объединяем все df cо всеми статистиками и количествам фото df_final = df.merge(df_stat_post, how='left', left_on='id', right_on="post_id") df_final = df_final.merge(df_photo, how='left', left_on='id', right_on="id") df_final.drop(columns='post_id',inplace=True) # добавляем дополнительные столбцы с временем df_final['date_time_report'] = datetime.now() df_final['date_report'] = date.today() df_final['year'] = df_final['date_time_report'].dt.year df_final['month'] = df_final['date_time_report'].dt.month df_final['day'] = df_final['date_time_report'].dt.day df_final['hour'] = df_final['date_time_report'].dt.hour df_final['minute'] = df_final['date_time_report'].dt.minute df_final[['date','date_report','date_time_report']] = df_final[['date','date_report','date_time_report']].astype('str') # сохраняем все значения data_list = df_final.values.tolist()Грузим в google sheet через api
Есть готовые библиотеки для работы с google sheet например pygsheets, но мне было важно поработать с API поэтому легких путей не искал.
Прежде чем загрузить надо настроить наш api прекрасная статья, в который пошагово написано и даст возможность поиграться с листами https://habr.com/ru/post/483302/
# подключаемся к гугл таблице CREDENTIALS_FILE = # Имя файла с закрытым ключом, вы должны подставить свое # Читаем ключи из файла credentials = ServiceAccountCredentials.from_json_keyfile_name(CREDENTIALS_FILE, ['https://www.googleapis.com/auth/spreadsheets', 'https://www.googleapis.com/auth/drive']) httpAuth = credentials.authorize(httplib2.Http()) # Авторизуемся в системе service = apiclient.discovery.build('sheets', 'v4', http = httpAuth) # Выбираем работу с таблицами и 4 версию API spreadsheetId = # ваш id листПосле подключения к листу. Находим последнюю заполненную строку.
В моем примере я заполняю последние 10 строк ровно по количеству постов которые я получил из get запроса. Подготавливаем шаблон для запроса, заполняем шаблон данными какие ячейки заполняем и заполняем. Далее выполняем запрос. Готово
# находим последнию строку заполненную response = service.spreadsheets().values().get(spreadsheetId = spreadsheetId,range="Лист номер один!A1:A").execute() # последние 10 строк заполняем number_sheet = "Лист номер один!A" + str(len(response['values'])+1) + ':AA' + str(len(response['values'])+10) # создаем запрос и вставляем туда данные data_vk = < "valueInputOption": "USER_ENTERED", # Данные воспринимаются, как вводимые пользователем (считается значение формул) "data": [ ] > data_vk['data'][0]['range'] = number_sheet data_vk['data'][0]['values'] = data_list # выполняем запрос results = service.spreadsheets().values().batchUpdate(spreadsheetId = spreadsheetId, body = data_vk).execute()Заключение
После написания этого кода мне требовалось запускать его каждый час и принял решение арендовать сервер, установить туда docker и через crontab запускать.