jsoup: Java HTML Parser
jsoup is a Java library for working with real-world HTML. It provides a very convenient API for fetching URLs and extracting and manipulating data, using the best of HTML5 DOM methods and CSS selectors.
jsoup implements the WHATWG HTML5 specification, and parses HTML to the same DOM as modern browsers do.
- scrape and parse HTML from a URL, file, or string
- find and extract data, using DOM traversal or CSS selectors
- manipulate the HTML elements, attributes, and text
- clean user-submitted content against a safelist, to prevent XSS attacks
- output tidy HTML
jsoup is designed to deal with all varieties of HTML found in the wild; from pristine and validating, to invalid tag-soup; jsoup will create a sensible parse tree.
Example
Fetch the Wikipedia homepage, parse it to a DOM, and select the headlines from the In the news section into a list of Elements (online sample, full source):
Document doc = Jsoup.connect("https://en.wikipedia.org/").get(); log(doc.title()); Elements newsHeadlines = doc.select("#mp-itn b a"); for (Element headline : newsHeadlines) Open source
jsoup is an open source project distributed under the liberal MIT license. The source code is available at GitHub.
Getting started
Development and support
If you have any questions on how to use jsoup, or have ideas for future development, please get in touch via one of the discussion methods.
If you find any issues, please file a bug after checking for duplicates.
The colophon talks about the history of and tools used to build jsoup.
Development of jsoup happens on GitHub. There you can see the latest changes, and get the source to build an unreleased version.
Status
jsoup is in general release.
Как парсить HTML на Java с помощью Jsoup
Если вы пишете робота на Java для разбора контента с каких-либо сайтов (т.н. «краулер»), то вы можете встретиться с некоторыми сложностями. Язык HTML хоть и формализован, однако допускает ошибки в разметке без нарушения отображения, в отличие от более строгого XML. Самой частой ошибкой является незакрытый тэг.
Страница в браузере может выглядеть корректно, но при попытке разобрать вёрстку вы потерпите неудачу. Кроме html 5-ой версии, существует ещё несколько стандартов вёрстки.
Чтобы не изобретать велосипед, можно воспользоваться готовой библиотекой Jsoup, которая позволяет легко парсить исходный html и выбирать оттуда отдельные элементы в простом декларативном синтаксисе. Библиотека поддерживает выбор как в формате CSS (более привычный на frontend), так и в XPath.
Подключаем Jsoup и парсим HTML
Для подключения достаточно добавить в maven следующую зависимость:
Скачивать html содержимое можно силами самой библиотеки:
try <
var document = Jsoup.connect( «https://devmark.ru/» ).get();
// бизнес-логика
> catch (Exception e) <
// обработка ошибок парсинга
>
Если же вы используете асинхронную модель, когда робот сначала скачивает содержимое множества страниц, а затем в отдельном процессе выполняет обработку, то библиотека поддерживает также парсинг строки и чтение из файла:
var htmlFile = new File( «/home/user/Documents/index.html» );
var document = Jsoup.parse(htmlFile, StandardCharsets. UTF_8 .name());
Выбор элементов и их атрибутов
После получения объекта Document, вы можете запрашивать у него различные элементы и их атрибуты. Далее будем запрашивать элементы в формате CSS. Если известно, что элемент должен быть на странице в единственном экземпляре (например, тэг title), то используйте метод selectFirst():
var titleElement = document.selectFirst( «title» );
System.out.printf( «Title: %s%n» , titleElement.text());
Но более безопасно использовать общий подход, когда элементов может быть несколько. Например, для получения всех гиперссылок на странице, используйте метод select():
var anchors = document.body().select( «a» );
System.out.printf( «Anchor count: %s%n» , anchors.size());
Мы получаем список объектов Element, у каждого из которых нужно взять значение атрибута href с помощью метода attr():
var links = anchors.stream()
.map(anchor ->
anchor.attr( «href» )
).toList();
System.out.println(links);
В результате в консоль будут выведены все гиперссылки, которые есть на странице.
Выводы
Как видите, Jsoup предоставляет простое и понятное API для выбора элементов и их атрибутов, которые содержатся в скачанном html-документе. Обладая этими знаниями, вы уже можете написать собственный краулер, а то и новый поисковик.
Парсинг html библиотекой jsoup


Итак мы хотим получить конкретную информацию с сайта. Пошагово разберем как это сделать. Для начала нам нужно получить объект Document . Это представление нашей html страницы. В Jsoup есть несколько способов превратить сайт в объект Document . Подключиться к серверу
Document document = Jsoup.connect("https://hh.ru/").get(); Jsoup сам подключается к сайту. Данный способ самый простой, но он годится только для тестирования. Есть более удобные и гибкие http клиенты. Также имейте ввиду, каким бы http клиентом вы не пользовались, добавляйте в запрос заголовок User-Agent с значением например Chrome/81.0.4044.138 . По этому заголовку сервер определяет с какого устройстрва вы подключились. Без этого заголовка сервер считает вас ботом и может забанить. Из файла;
File file = new File("hh-test.html"); Document document = Jsoup.parse(file, "UTF-8", "hh.ru"); Это основной способ получения объекта Document . Последний аргумент «hh.ru» — базовый URI. Это нужно для создания абсолютных ссылок из относительных, которые присутствуют на сайте. Из строки
String html = " " + " " + " " + " Работа в Москве, поиск персонала и публикация вакансий - hh.ru " + " " + " " + " " + " " + " Работа найдется для каждого
" + " Поиск вакансий " + " " + " Вакансии дня " + " " + " Работа из дома " + " " + " " + " "; Document document = Jsoup.parse(html, "hh.ru"); Далее я буду демонстрировать библиотеку на этом html, который представляет упрощенный сайт. Получение тега Основная задача при парсинге — получить нужный тег. Делать мы это будем при помощи метода select . Обратите внимание, что он всегда возвращает список тегов. Если теги не найдены, то список будет пустым. В аргумент метода нужно передать css селектор, по которому ищутся теги. На селекторах я остановлюсь подробнее, потому что вся работа сводится к написанию правильного селектора. Обычно нам нужно составить его так, чтобы он возвращал один тег.
Elements h1 = document.select("h1"); System.out.println(h1); Работа найдется для каждого
Elements titleElem = document.select("head > title"); Elements divs = document.select("body > div"); Elements firstDiv = document.select("body > div:nth-child(1)"); Получить первый тег div вложенный в body . Получать тег по порядковому номеру плохой способ, потому что его положение на сайте может поменяться. Лучше определить тег по абсолютным параметрам. Такими параметрами являются атрибуты class и id
Elements contentElem = document.select("body > div.content"); Elements idElem = document.select("#123"); Elements divHeader = document.select("body > div.header.main :not(h1)"); Методы Elements Когда мы получили список Elements можно извлечь данные из него. Напомню, что обычно селектором ищется один тег, т.е. у Elements должен быть размер 1.
строковое представление тега Если вам нужно быстро получить селектор элемента — в браузере откройте панель разработчика (f12), нажмите правой кнопкой на элемент, «просмотреть код», нажмите правой кнопкой на тег, далее «Copy» «Copy selector». Такой селектор будет не оптимальным, но для быстрого результата вполне подходит. 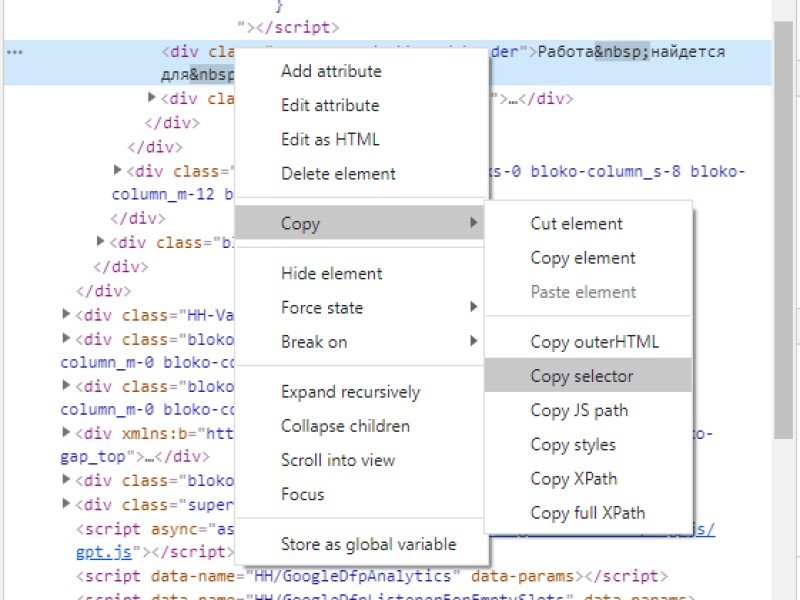
 Заключение Это основы работы с библиотекой Jsoup. Но этого вполне достаточно, чтобы парсить сайты. Для уверенной работы вам нужна только практика написания селекторов в реальных сайтах. P.s. Данная библиотека используется для решения большой задачи на 38 уровне
Заключение Это основы работы с библиотекой Jsoup. Но этого вполне достаточно, чтобы парсить сайты. Для уверенной работы вам нужна только практика написания селекторов в реальных сайтах. P.s. Данная библиотека используется для решения большой задачи на 38 уровне