pandas.read_sql_query#
Returns a DataFrame corresponding to the result set of the query string. Optionally provide an index_col parameter to use one of the columns as the index, otherwise default integer index will be used.
Parameters sql str SQL query or SQLAlchemy Selectable (select or text object)
con SQLAlchemy connectable, str, or sqlite3 connection
Using SQLAlchemy makes it possible to use any DB supported by that library. If a DBAPI2 object, only sqlite3 is supported.
index_col str or list of str, optional, default: None
Column(s) to set as index(MultiIndex).
coerce_float bool, default True
Attempts to convert values of non-string, non-numeric objects (like decimal.Decimal) to floating point. Useful for SQL result sets.
params list, tuple or dict, optional, default: None
List of parameters to pass to execute method. The syntax used to pass parameters is database driver dependent. Check your database driver documentation for which of the five syntax styles, described in PEP 249’s paramstyle, is supported. Eg. for psycopg2, uses %(name)s so use params=.
- List of column names to parse as dates.
- Dict of where format string is strftime compatible in case of parsing string times, or is one of (D, s, ns, ms, us) in case of parsing integer timestamps.
- Dict of , where the arg dict corresponds to the keyword arguments of pandas.to_datetime() Especially useful with databases without native Datetime support, such as SQLite.
If specified, return an iterator where chunksize is the number of rows to include in each chunk.
dtype Type name or dict of columns
Data type for data or columns. E.g. np.float64 or .
Which dtype_backend to use, e.g. whether a DataFrame should have NumPy arrays, nullable dtypes are used for all dtypes that have a nullable implementation when “numpy_nullable” is set, pyarrow is used for all dtypes if “pyarrow” is set.
The dtype_backends are still experimential.
Read SQL database table into a DataFrame.
Read SQL query or database table into a DataFrame.
Any datetime values with time zone information parsed via the parse_dates parameter will be converted to UTC.
pandas.read_sql#
pandas. read_sql ( sql , con , index_col = None , coerce_float = True , params = None , parse_dates = None , columns = None , chunksize = None , dtype_backend = _NoDefault.no_default , dtype = None ) [source] #
Read SQL query or database table into a DataFrame.
This function is a convenience wrapper around read_sql_table and read_sql_query (for backward compatibility). It will delegate to the specific function depending on the provided input. A SQL query will be routed to read_sql_query , while a database table name will be routed to read_sql_table . Note that the delegated function might have more specific notes about their functionality not listed here.
Parameters sql str or SQLAlchemy Selectable (select or text object)
SQL query to be executed or a table name.
con SQLAlchemy connectable, str, or sqlite3 connection
Using SQLAlchemy makes it possible to use any DB supported by that library. If a DBAPI2 object, only sqlite3 is supported. The user is responsible for engine disposal and connection closure for the SQLAlchemy connectable; str connections are closed automatically. See here.
index_col str or list of str, optional, default: None
Column(s) to set as index(MultiIndex).
coerce_float bool, default True
Attempts to convert values of non-string, non-numeric objects (like decimal.Decimal) to floating point, useful for SQL result sets.
params list, tuple or dict, optional, default: None
List of parameters to pass to execute method. The syntax used to pass parameters is database driver dependent. Check your database driver documentation for which of the five syntax styles, described in PEP 249’s paramstyle, is supported. Eg. for psycopg2, uses %(name)s so use params=.
- List of column names to parse as dates.
- Dict of where format string is strftime compatible in case of parsing string times, or is one of (D, s, ns, ms, us) in case of parsing integer timestamps.
- Dict of , where the arg dict corresponds to the keyword arguments of pandas.to_datetime() Especially useful with databases without native Datetime support, such as SQLite.
List of column names to select from SQL table (only used when reading a table).
chunksize int, default None
If specified, return an iterator where chunksize is the number of rows to include in each chunk.
dtype_backend , defaults to NumPy backed DataFrames
Which dtype_backend to use, e.g. whether a DataFrame should have NumPy arrays, nullable dtypes are used for all dtypes that have a nullable implementation when “numpy_nullable” is set, pyarrow is used for all dtypes if “pyarrow” is set.
The dtype_backends are still experimential.
Data type for data or columns. E.g. np.float64 or . The argument is ignored if a table is passed instead of a query.
Read SQL database table into a DataFrame.
Read SQL query into a DataFrame.
Read data from SQL via either a SQL query or a SQL tablename. When using a SQLite database only SQL queries are accepted, providing only the SQL tablename will result in an error.
>>> from sqlite3 import connect >>> conn = connect(':memory:') >>> df = pd.DataFrame(data=[[0, '10/11/12'], [1, '12/11/10']], . columns=['int_column', 'date_column']) >>> df.to_sql('test_data', conn) 2
>>> pd.read_sql('SELECT int_column, date_column FROM test_data', conn) int_column date_column 0 0 10/11/12 1 1 12/11/10
>>> pd.read_sql('test_data', 'postgres:///db_name')
Apply date parsing to columns through the parse_dates argument The parse_dates argument calls pd.to_datetime on the provided columns. Custom argument values for applying pd.to_datetime on a column are specified via a dictionary format:
>>> pd.read_sql('SELECT int_column, date_column FROM test_data', . conn, . parse_dates="date_column": "format": "%d/%m/%y">>) int_column date_column 0 0 2012-11-10 1 1 2010-11-12
Как переписать SQL-запросы на Python с помощью Pandas
В этой статье June Tao Ching рассказал, как с помощью Pandas добиться на Python такого же результата, как в SQL-запросах. Перед вами — перевод, а оригинал вы можете найти в блоге towardsdatascience.com.

Фото с сайта Unsplash. Автор: Hitesh Choudhary
Получение такого же результата на Python, как и при SQL-запросе
Часто при работе над одним проектом нам приходится переключаться между SQL и Python. При этом некоторые из нас знакомы с управлением данными в SQL-запросах, но не на Python, что мешает нашей эффективности и производительности. На самом деле, используя Pandas, можно добиться на Python такого же результата, как в SQL-запросах.
Начало работы
Нужно установить пакет Pandas, если его нет.
Мы будем использовать знаменитый Датасет Титаник от Kaggle.
После установки пакета и загрузки данных нам необходимо импортировать их в наше окружение Python.

Для хранения данных мы будем использовать DataFrame. Управлять этой структурой данных нам помогут различные функции Pandas.
SELECT, DISTINCT, COUNT, LIMIT
Начнем с простых SQL-запросов, которые мы часто используем.
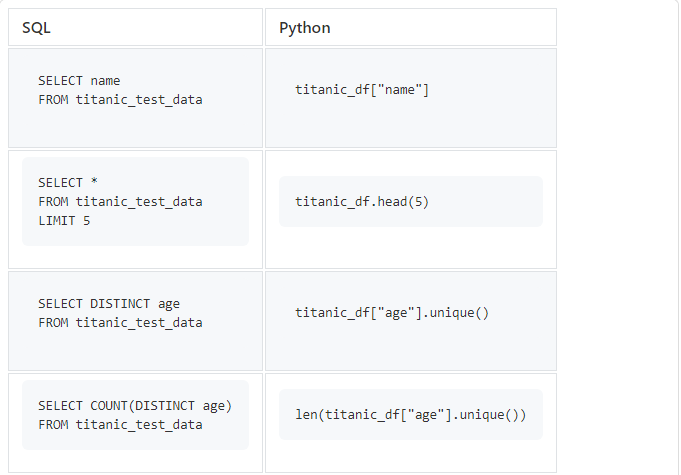
titanic_df[«age»].unique() вернет массив уникальных значений, поэтому нам придется использовать len() , чтобы посчитать их количество.
SELECT, WHERE, OR, AND, IN (SELECT с условиями)
После первой части вы узнали, как простыми способами исследовать DataFrame. Теперь попробуем сделать это с некоторыми условиями (это оператор WHERE в SQL).

Если мы хотим выбрать только определенные столбцы из DataFrame, мы можем сделать это с помощью дополнительной пары квадратных скобок.
Примечание: если вы выбираете несколько столбцов, вам нужно поместить массив [«name»,»age»] внутри квадратных скобок.
isin() работает точно так же, как IN в SQL-запросах. Чтобы использовать NOT IN , на Python нам нужно использовать отрицание (~) .
GROUP BY, ORDER BY, COUNT
GROUP BY и ORDER BY также являются популярными SQL-операторами при исследовании данных. А теперь давайте попробуем использовать их на Python.

Если мы хотим отсортировать только один столбец COUNT, то можем просто передать булево значение в метод sort_values . Если мы собираемся сортировать несколько столбцов, то должны передать массив булевых значений в метод sort_values .
Метод sum() выдаст суммы для каждого из столбцов в DataFrame, которые могут быть численно агрегированы. Если нам нужен только определенный столбец, то нужно указать имя столбца, используя квадратные скобки.
MIN, MAX, MEAN, MEDIAN
И наконец, давайте попробуем некоторые стандартные статистические функции, которые важны при исследовании данных.
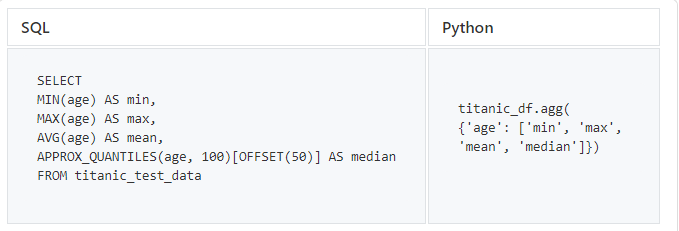
SQL не содержит операторов, возвращающих медианное значение, поэтому для получения медианного значения столбца с информацией о возрасте мы используем BigQuery APPROX_QUANTILES
В Pandas метод агрегации .agg() также поддерживает другие функции, например sum .
Теперь вы научились переписывать SQL-запросы на Python с помощью Pandas. Надеюсь, эта статья будет вам полезна.
Весь код можно найти в моем репозитории Github.