Распознавание поднятых пальцев на Python+OpenCV
В данной статье хочу рассмотреть банальный и несложный проект, а именно подсчет количества поднятых пальцев.
Все исходники можно найти на моем Github.
Код будем рассматривать с самого начала, но лучше всего ознакомиться с моими предыдущими статьями.
Подготавливаем среду и устанавливаем следующие библиотеки:
pip install mediapipe pip install opencv-python pip install mathСоздаем файл HandTrackingModule.py с привычным для моих читателей классом handDetector :
import cv2 import mediapipe as mp import time import math class handDetector(): def __init__(self, mode=False, maxHands=2, modelComplexity=1, detectionCon=0.5, trackCon=0.5): self.mode = mode self.maxHands = maxHands self.modelComplexity = modelComplexity self.detectionCon = detectionCon self.trackCon = trackCon self.mpHands = mp.solutions.hands self.hands = self.mpHands.Hands(self.mode, self.maxHands, self.modelComplexity, self.detectionCon, self.trackCon) self.mpDraw = mp.solutions.drawing_utils self.tipIds = [4, 8, 12, 16, 20] def findHands(self, img, draw=True): imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) self.results = self.hands.process(imgRGB) #print(results.multi_hand_landmarks) if self.results.multi_hand_landmarks: for handLms in self.results.multi_hand_landmarks: if draw: self.mpDraw.draw_landmarks(img, handLms, self.mpHands.HAND_CONNECTIONS) return img def findPosition(self, img, handNo=0, draw=True): xList = [] yList = [] bbox = [] self.lmList = [] if self.results.multi_hand_landmarks: myHand = self.results.multi_hand_landmarks[handNo] for id, lm in enumerate(myHand.landmark): #print(id, lm) h, w, c = img.shape cx, cy = int(lm.x*w), int(lm.y*h) xList.append(cx) yList.append(cy) #print(id, cx, cy) self.lmList.append([id, cx, cy]) if draw: cv2.circle(img, (cx, cy), 5, (255,0,255), cv2.FILLED) xmin, xmax = min(xList), max(xList) ymin, ymax = min(yList), max(yList) bbox = xmin, ymin, xmax, ymax if draw: cv2.rectangle(img, (bbox[0]-20, bbox[1]-20), (bbox[2]+20, bbox[3]+20), (0, 255, 0), 2) return self.lmList, bbox def findDistance(self, p1, p2, img, draw=True): x1, y1 = self.lmList[p1][1], self.lmList[p1][2] x2, y2 = self.lmList[p2][1], self.lmList[p2][2] cx, cy = (x1+x2)//2, (y1+y2)//2 if draw: cv2.circle(img, (x1,y1), 15, (255,0,255), cv2.FILLED) cv2.circle(img, (x2,y2), 15, (255,0,255), cv2.FILLED) cv2.line(img, (x1,y1), (x2,y2), (255,0,255), 3) cv2.circle(img, (cx,cy), 15, (255,0,255), cv2.FILLED) length = math.hypot(x2-x1, y2-y1) return length, img, [x1, y1, x2, y2, cx, cy] def fingersUp(self): fingers = [] # Thumb if self.lmList[self.tipIds[0]][1] < self.lmList[self.tipIds[0]-1][1]: fingers.append(1) else: fingers.append(0) # 4 Fingers for id in range(1,5): if self.lmList[self.tipIds[id]][2] < self.lmList[self.tipIds[id]-2][2]: fingers.append(1) else: fingers.append(0) return fingers def main(): pTime = 0 cTime = 0 cap = cv2.VideoCapture(0) detector = handDetector() while True: success, img = cap.read() img = detector.findHands(img) lmList = detector.findPosition(img) if len(lmList) != 0: print(lmList[1]) cTime = time.time() fps = 1. / (cTime - pTime) pTime = cTime cv2.putText(img, str(int(fps)), (10,70), cv2.FONT_HERSHEY_PLAIN, 3, (255,0,255), 3) cv2.imshow("Image", img) cv2.waitKey(1) if __name__ == "__main__": main()Данный класс является шаблонным и я его всегда использую в своих проектах, связанных с OpenCV.
Подготовим исходники. Скачаем изображения с Github и поместим их в папку fingers . Посмотрим на их названия, логика тут простая - изображение называется .jpg , где num - количество поднятых пальцев.
Создадим новый файл main.py и импортируем библиотеки:
import cv2 import time import os import HandTrackingModule as htmwCam, hCam = 640, 480 cap = cv2.VideoCapture(0) cap.set(3, wCam) cap.set(4, hCam)При подключении камеры могут возникнуть ошибки, поменяйте 0 из `cap = cv2.VideoCapture(0)` на 1 или 2 .
folderPath = "fingers" # name of the folder, where there are images of fingers fingerList = os.listdir(folderPath) # list of image titles in 'fingers' folder overlayList = [] for imgPath in fingerList: image = cv2.imread(f'/') overlayList.append(image)Объявляем дополнительные переменные:
pTime = 0 detector = htm.handDetector(detectionCon=0.75, maxHands=1) totalFingers = 0Запускаем бесконечный цикл (можно добавить остановку, если требуется), запускаем камеру и начинаем отслеживать руку в кадре:
while True: sucess, img = cap.read() img = cv2.flip(img, 1) img = detector.findHands(img) lmList, bbox = detector.findPosition(img, draw=False)Если список с позициями руки не пустой, то считаем количество поднятых пальцев:
if lmList: fingersUp = detector.fingersUp() totalFingers = fingersUp.count(1)Также будем выводить изображение, соответствующее количеству поднятых пальцев:
h, w, c = overlayList[totalFingers].shape img[0:h, 0:w] = overlayList[totalFingers]И последнее, считаем FPS и выводим надписи в окне:
cTime = time.time() fps = 1/ (cTime-pTime) pTime = cTime cv2.putText(img, f'FPS: ', (400, 70), cv2.FONT_HERSHEY_PLAIN, 3, (255, 0, 0), 3) cv2.rectangle(img, (20, 225), (170, 425), (0, 255, 0), cv2.FILLED) cv2.putText(img, str(totalFingers), (45, 375), cv2.FONT_HERSHEY_PLAIN, 10, (255, 0, 0), 25) cv2.imshow("Image", img) cv2.waitKey(1) Запускаем программу и тестируем:
OpenCV в Python. Часть 1
Привет, Хабр! Запускаю цикл статей по библиотеке OpenCV в Python. Кому интересно, добро пожаловать под кат!

Введение
OpenCV — это open source библиотека компьютерного зрения, которая предназначена для анализа, классификации и обработки изображений. Широко используется в таких языках как C, C++, Python и Java.
Установка
Будем считать, что Python и библиотека OpenCV у вас уже установлены, если нет, то вот инструкция для установки python на windows и на ubuntu, установка OpenCV на windows и на ubuntu.
Немного про пиксели и цветовые пространства
Перед тем как перейти к практике, нам нужно разобраться немного с теорией. Каждое изображение состоит из набора пикселей. Пиксель — это строительный блок изображения. Если представить изображение в виде сетки, то каждый квадрат в сетке содержит один пиксель, где точке с координатой ( 0, 0 ) соответствует верхний левый угол изображения. К примеру, представим, что у нас есть изображение с разрешением 400x300 пикселей. Это означает, что наша сетка состоит из 400 строк и 300 столбцов. В совокупности в нашем изображении есть 400*300 = 120000 пикселей.
В большинстве изображений пиксели представлены двумя способами: в оттенках серого и в цветовом пространстве RGB. В изображениях в оттенках серого каждый пиксель имеет значение между 0 и 255, где 0 соответствует чёрному, а 255 соответствует белому. А значения между 0 и 255 принимают различные оттенки серого, где значения ближе к 0 более тёмные, а значения ближе к 255 более светлые:

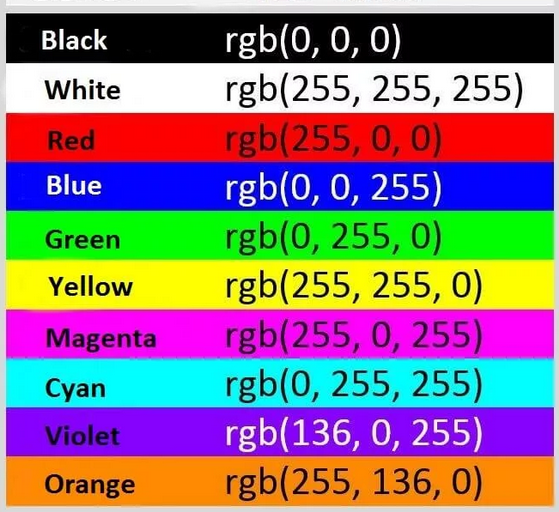
Цветные пиксели обычно представлены в цветовом пространстве RGB(red, green, blue — красный, зелёный, синий), где одно значение для красной компоненты, одно для зелёной и одно для синей. Каждая из трёх компонент представлена целым числом в диапазоне от 0 до 255 включительно, которое указывает как «много» цвета содержится. Исходя из того, что каждая компонента представлена в диапазоне [0,255], то для того, чтобы представить насыщенность каждого цвета, нам будет достаточно 8-битного целого беззнакового числа. Затем мы объединяем значения всех трёх компонент в кортеж вида (красный, зеленый, синий). К примеру, чтобы получить белый цвет, каждая из компонент должна равняться 255: (255, 255, 255). Тогда, чтобы получить чёрный цвет, каждая из компонент должна быть равной 0: (0, 0, 0). Ниже приведены распространённые цвета, представленные в виде RGB кортежей:
Импорт библиотеки OpenCV
Теперь перейдём к практической части. Первое, что нам необходимо сделать — это импортировать библиотеку. Есть несколько путей импорта, самый распространённый — это использовать выражение:
Также можно встретить следующую конструкцию для импорта данной библиотеки:
Загрузка, отображение и сохранение изображения
def loading_displaying_saving(): img = cv2.imread('girl.jpg', cv2.IMREAD_GRAYSCALE) cv2.imshow('girl', img) cv2.waitKey(0) cv2.imwrite('graygirl.jpg', img)Для загрузки изображения мы используем функцию cv2.imread(), где первым аргументом указывается путь к изображению, а вторым аргументом, который является необязательным, мы указываем, в каком цветовом пространстве мы хотим считать наше изображение. Чтобы считать изображение в RGB — cv2.IMREAD_COLOR, в оттенках серого — cv2.IMREAD_GRAYSCALE. По умолчанию данный аргумент принимает значение cv2.IMREAD_COLOR. Данная функция возвращает 2D (для изображения в оттенках серого) либо 3D (для цветного изображения) массив NumPy. Форма массива для цветного изображения: высота x ширина x 3, где 3 — это байты, по одному байту на каждую из компонент. В изображениях в оттенках серого всё немного проще: высота x ширина.
С помощью функции cv2.imshow() мы отображаем изображение на нашем экране. В качестве первого аргумента мы передаём функции название нашего окна, а вторым аргументом изображение, которое мы загрузили с диска, однако, если мы далее не укажем функцию cv2.waitKey(), то изображение моментально закроется. Данная функция останавливает выполнение программы до нажатия клавиши, которую нужно передать первым аргументом. Для того, чтобы любая клавиша была засчитана передаётся 0. Слева представлено изображение в оттенках серого, а справа в формате RGB:

И, наконец, с помощью функции cv2.imwrite() записываем изображение в файл в формате jpg(данная библиотека поддерживает все популярные форматы изображений:png, tiff,jpeg,bmp и т. д., поэтому можно было сохранить наше изображение в любом из этих форматов), где первым аргументом передаётся непосредственно само название и расширение, а следующим параметром изображение, которое мы хотим сохранить.
Доступ к пикселям и манипулирование ими
Для того, чтобы узнать высоту, ширину и количество каналов у изображения можно использовать атрибут shape:
print("Высота:"+str(img.shape[0])) print("Ширина:" + str(img.shape[1])) print("Количество каналов:" + str(img.shape[2]))Важно помнить, что у изображений в оттенках серого img.shape[2] будет недоступно, так как данные изображения представлены в виде 2D массива.
Чтобы получить доступ к значению пикселя, нам просто нужно указать координаты x и y пикселя, который нас интересует. Также важно помнить, что библиотека OpenCV хранит каналы формата RGB в обратном порядке, в то время как мы думаем в терминах красного, зеленого и синего, то OpenCV хранит их в порядке синего, зеленого и красного цветов:
(b, g, r) = img[0, 0] print("Красный: <>, Зелёный: <>, Синий: <>".format(r, g, b))Cначала мы берём пиксель, который расположен в точке (0,0). Данный пиксель, да и любой другой пиксель, представлены в виде кортежа. Заметьте, что название переменных расположены в порядке b, g и r. В следующей строке выводим значение каждого канала на экран. Как можно увидеть, доступ к значениям пикселей довольно прост, также просто можно и манипулировать значениями пикселей:
img[0, 0] = (255, 0, 0) (b, g, r) = img[0, 0] print("Красный: <>, Зелёный: <>, Синий: <>".format(r, g, b))В первой строке мы устанавливаем значение пикселя (0, 0) равным (255, 0, 0), затем мы снова берём значение данного пикселя и выводим его на экран, в результате мне на консоль вывелось следующее:
Красный: 251, Зелёный: 43, Синий: 65 Красный: 0, Зелёный: 0, Синий: 255На этом у нас конец первой части. Если вдруг кому-то нужен исходный код и картинка, то вот ссылка на github. Всем спасибо за внимание!