Поиск объектов на видео с помощью Python
В данной статье хочу рассказать про поиск объектов на видео с помощью Python и OpenCV. Помимо обычных видео, можно использовать и камеры.
Полный код и все исходники можно найти на моем Github.
Данный проект является продолжением моей предыдущей статьи — Поиск объектов на фото с помощью Python. Для того, чтобы не тратить много времени на ее изучение, я распишу весь процесс по новой.
Для того, чтобы написать легковесное приложение для обнаружения объектов на видео, установим необходимые библиотеки:
pip install opencv-python pip install numpy pip install artПерейдем к написанию самого приложения, которое будет находить объекты на видео при помощи YOLO и отмечать их.
Скачаем с моего Github исходники и поместим в директорию Resources в проекте. Посмотрим, какие объекты сможет определять наша будущая программа:
'person', 'bicycle', 'car', 'motorbike', 'aeroplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'sofa', 'pottedplant', 'bed', 'diningtable', 'toilet', 'tvmonitor', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'Первым делом импортируем необходимые библиотеки:
import cv2 import numpy as np from art import tprintНапишем функции для применения YOLO. С ее помощью определяются самые вероятные классы объектов на изображении, а также координаты их границ, которые в дальнейшем будут использованы для отрисовки.
def apply_yolo_object_detection(image_to_process): """ Recognition and determination of the coordinates of objects on the image :param image_to_process: original image :return: image with marked objects and captions to them """ height, width, _ = image_to_process.shape blob = cv2.dnn.blobFromImage(image_to_process, 1 / 255, (608, 608), (0, 0, 0), swapRB=True, crop=False) net.setInput(blob) outs = net.forward(out_layers) class_indexes, class_scores, boxes = ([] for i in range(3)) objects_count = 0 # Starting a search for objects in an image for out in outs: for obj in out: scores = obj[5:] class_index = np.argmax(scores) class_score = scores[class_index] if class_score > 0: center_x = int(obj[0] * width) center_y = int(obj[1] * height) obj_width = int(obj[2] * width) obj_height = int(obj[3] * height) box = [center_x - obj_width // 2, center_y - obj_height // 2, obj_width, obj_height] boxes.append(box) class_indexes.append(class_index) class_scores.append(float(class_score)) # Selection chosen_boxes = cv2.dnn.NMSBoxes(boxes, class_scores, 0.0, 0.4) for box_index in chosen_boxes: box_index = box_index box = boxes[box_index] class_index = class_indexes[box_index] # For debugging, we draw objects included in the desired classes if classes[class_index] in classes_to_look_for: objects_count += 1 image_to_process = draw_object_bounding_box(image_to_process, class_index, box) final_image = draw_object_count(image_to_process, objects_count) return final_imageДобавим функцию, которая обведет найденные на изображении объекты с помощью координат границ, полученных из функции apply_yolo_object_detection :
def draw_object_bounding_box(image_to_process, index, box): """ Drawing object borders with captions :param image_to_process: original image :param index: index of object class defined with YOLO :param box: coordinates of the area around the object :return: image with marked objects """ x, y, w, h = box start = (x, y) end = (x + w, y + h) color = (0, 255, 0) width = 2 final_image = cv2.rectangle(image_to_process, start, end, color, width) start = (x, y - 10) font_size = 1 font = cv2.FONT_HERSHEY_SIMPLEX width = 2 text = classes[index] final_image = cv2.putText(final_image, text, start, font, font_size, color, width, cv2.LINE_AA) return final_imageПомимо отрисовки объектов, можно добавить вывод их количества. Напишем для этого еще одну функцию:
def draw_object_count(image_to_process, objects_count): """ Signature of the number of found objects in the image :param image_to_process: original image :param objects_count: the number of objects of the desired class :return: image with labeled number of found objects """ start = (10, 120) font_size = 1.5 font = cv2.FONT_HERSHEY_SIMPLEX width = 3 text = "Objects found: " + str(objects_count) # Text output with a stroke # (so that it can be seen in different lighting conditions of the picture) white_color = (255, 255, 255) black_outline_color = (0, 0, 0) final_image = cv2.putText(image_to_process, text, start, font, font_size, black_outline_color, width * 3, cv2.LINE_AA) final_image = cv2.putText(final_image, text, start, font, font_size, white_color, width, cv2.LINE_AA) return final_imageНапишем функцию, которая будет обрабатывать видео по кадрам и выводить результат обработки на экран:
def start_video_object_detection(video: str): """ Real-time video capture and analysis """ while True: try: # Capturing a picture from a video video_camera_capture = cv2.VideoCapture(video) while video_camera_capture.isOpened(): ret, frame = video_camera_capture.read() if not ret: break # Application of object recognition methods on a video frame from YOLO frame = apply_yolo_object_detection(frame) # Displaying the processed image on the screen with a reduced window size frame = cv2.resize(frame, (1920 // 2, 1080 // 2)) cv2.imshow("Video Capture", frame) cv2.waitKey(1) video_camera_capture.release() cv2.destroyAllWindows() except KeyboardInterrupt: passЧтобы не нагружать устройство обработкой каждого кадра, можно добавить обновление экрана по нажатии любой клавиши:
def start_video_object_detection(video: str): """ Real-time video capture and analysis """ while True: try: # Capturing a picture from a video video_camera_capture = cv2.VideoCapture(video) while video_camera_capture.isOpened(): ret, frame = video_camera_capture.read() if not ret: break # Application of object recognition methods on a video frame from YOLO frame = apply_yolo_object_detection(frame) # Displaying the processed image on the screen with a reduced window size frame = cv2.resize(frame, (1920 // 2, 1080 // 2)) cv2.imshow("Video Capture", frame) cv2.waitKey(0): break video_camera_capture.release() cv2.destroyAllWindows() except KeyboardInterrupt: passТеперь напишем функцию main , где будем передавать аргументы в функции.
Данный блок не является обязательным, но я захотел сделать красивый вывод текста в консоль:
# Logo tprint("Object detection") tprint("by") tprint("paveldat")Создадим функцию main , в которой настроим нашу сеть:
if __name__ == '__main__': # Loading YOLO scales from files and setting up the network net = cv2.dnn.readNetFromDarknet("Resources/yolov4-tiny.cfg", "Resources/yolov4-tiny.weights") layer_names = net.getLayerNames() out_layers_indexes = net.getUnconnectedOutLayers() out_layers = [layer_names[index - 1] for index in out_layers_indexes] # Loading from a file of object classes that YOLO can detect with open("Resources/coco.names.txt") as file: classes = file.read().split("\n") # Determining classes that will be prioritized for search in an image # The names are in the file coco.names.txt video = input("Path to video (or URL): ") look_for = input("What we are looking for: ").split(',') # Delete spaces list_look_for = [] for look in look_for: list_look_for.append(look.strip()) classes_to_look_for = list_look_for start_video_object_detection(video)Программа будет запрашивать путь до видео и объекты, которые хотим найти. Вместо пути до видео можно использовать ссылку на видео с камеры. Объекты должны перечисляться через запятую, если их несколько.
Запускаем программу и тестируем.
Path to video (or URL): Result/input/example.mp4 What we are looking for: person, car, busМы проверили, как алгоритм YOLO справился с тестам. Погрешность все же есть, но в основном программа успешно находит необходимые объекты.
Поиск объектов на изображении. Часть 1
Компьютерное зрение — удивительная область, которая позволяет компьютерам видеть и понимать мир через обработку изображений и видео. Одним из наиболее популярных инструментов для работы с компьютерным зрением является библиотека OpenCV. В этой статье мы рассмотрим, как использовать OpenCV для распознавания обьектов на изображении.
Допустим мы хотим найти карты из игры Дурак онлайн. Вот такое изображение мы будем обрабатывать.
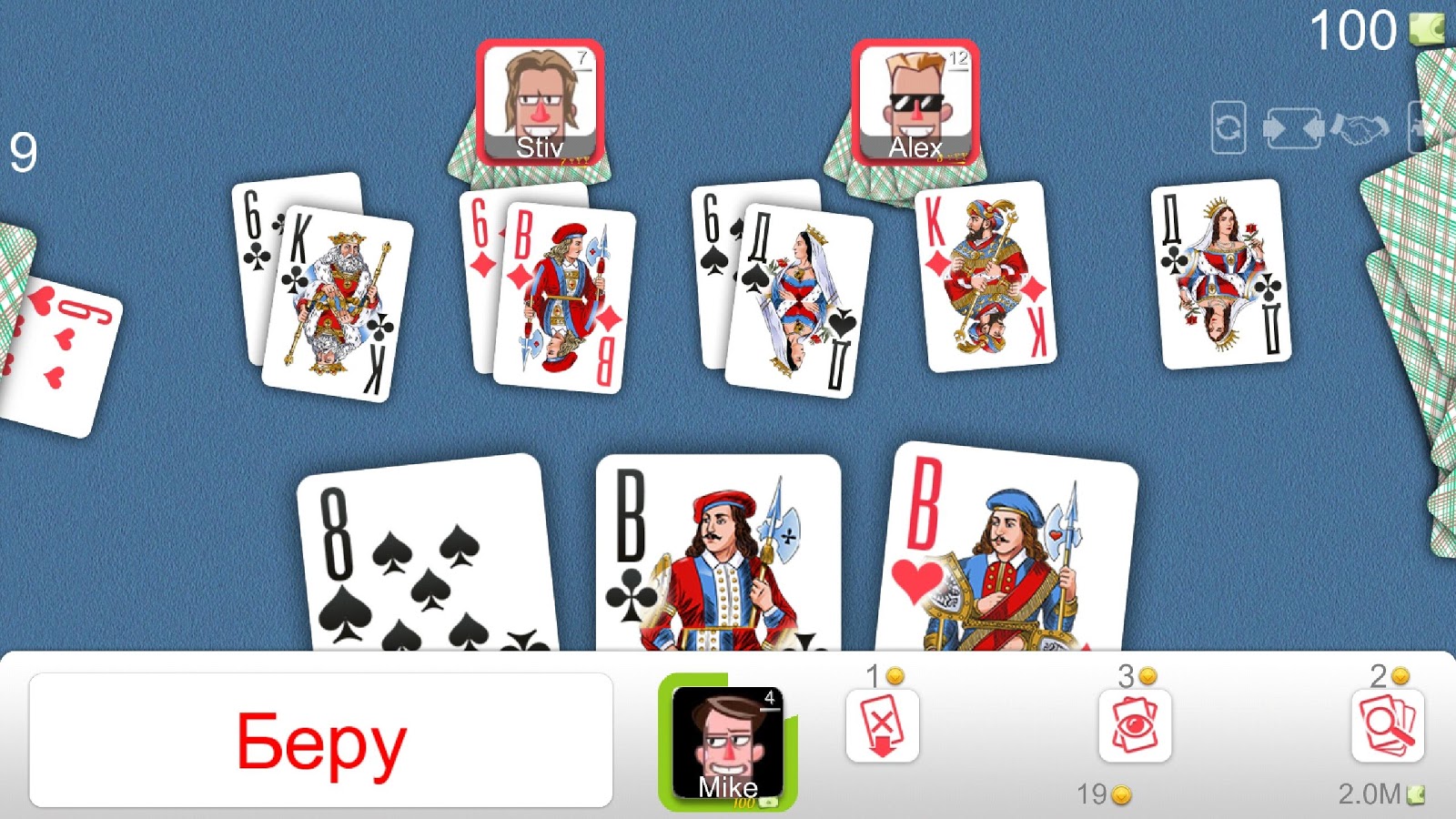
Шаг 1: Установка и настройка OpenCV
Первым шагом будет установка и настройка OpenCV. Вы можете установить OpenCV с помощью pip, выполнив следующую команду:
Шаг 2: Загрузка и предобработка изображения
Прежде чем начать распознавание карт, нам нужно загрузить изображение стола с картами. Мы используем функцию cv2.imread , чтобы загрузить изображение в переменную image :
image = cv2.imread('table_image.jpg') Затем мы можем преобразовать изображение в оттенки серого и применить размытие для удаления шума:
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) blurred = cv2.GaussianBlur(gray, (5, 5), 0) Шаг 3: Пороговая обработка
Для обнаружения контуров карт на изображении мы используем пороговую обработку. Пороговая обработка преобразует изображение в бинарное изображение, где каждый пиксель считается либо черным, либо белым. Мы можем использовать функцию cv2.threshold для этого:
thresholded = cv2.threshold(blurred, 100, 255, cv2.THRESH_BINARY)[1] Шаг 4: Поиск контуров
Теперь мы можем использовать функцию cv2.findContours , чтобы найти контуры на изображении:
contours, _ = cv2.findContours(thresholded, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) Функция cv2.findContours возвращает список контуров на изображении.
Шаг 5: Обводка найденных карт на экране
Чтобы обвести найденные карты на экране, мы используем функцию cv2.drawContours . Например, чтобы обвести контуры зеленым цветом, мы можем использовать следующий код:
cv2.draw Contours(image, contours, -1, (0, 255, 0), 2) Этот код обведет все найденные контуры зеленым цветом толщиной 2 пикселя.
Шаг 6: Отображение изображения с обведенными картами
Наконец, мы можем отобразить изображение с обведенными картами на экране с помощью функции cv2.imshow :
cv2.imshow('Detected Cards', image) cv2.waitKey(0) cv2.destroyAllWindows() Этот код откроет окно с изображением, на котором будут обведены найденные карты. Ожидание нажатия клавиши cv2.waitKey(0) позволяет пользователю просмотреть изображение до его закрытия.
import cv2 # Загрузка изображения image = cv2.imread('test_card.jpg') # Предобработка изображения gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) blurred = cv2.GaussianBlur(gray, (5, 5), 0) thresholded = cv2.threshold(blurred, 100, 255, cv2.THRESH_BINARY)[1] # Поиск контуров на изображении contours, _ = cv2.findContours(thresholded, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # Отображение контуров на изображении cv2.drawContours(image, contours, -1, (0, 255, 0), 2) # Отображение изображения с контурами cv2.imshow('Detected Cards', image) cv2.waitKey(0) cv2.destroyAllWindows() 
Как мы видим программа успешно справилась с поиском карт на переднем и боковых планах, однако в центре все сработало не очень.
Заключение
В этой статье мы рассмотрели, как использовать библиотеку OpenCV для распознавания карт на столе и обводки их на экране. Мы рассмотрели шаги от загрузки и предобработки изображения до поиска контуров и обводки найденных карт. OpenCV предоставляет мощные инструменты для обработки изображений и компьютерного зрения, и вы можете использовать эти техники для создания различных проектов, связанных с распознаванием и обработкой изображений. Однако в целом все распозналось не очень, ничего страшного, в следующих статьях мы исправим это.