- Python Read Big File Example
- 1. Python file object’s read() and readlines() method.
- 1.1 read([size]).
- 1.2 readlines().
- 2. How To Correctly Use read and readlines.
- 2.1 read a binary file.
- 2.2 read text file.
- 3. Question & Answer.
- 3.1 How to write python code to lazy read big file.
- Leave a Comment Cancel Reply
- How to read large text files in Python?
- Problem with readline() method to read large text files
- Read large text files in Python using iterate
- How to Read Large Text Files in Python
- Reading Large Text Files in Python
- What if the Large File doesn’t have lines?
- How to open large csv or text files using Python
- Putting it All Together
Python Read Big File Example
Read file content in python is very simple, you can use the Python file object’s method read and readlines to easily read them. But there are also some tricks in using them. This article will tell you how to use them correctly.
1. Python file object’s read() and readlines() method.
You often see the pairs of read() and readlines() functions in a handy tutorial for searching python read-write files. So we’ll often see the following code.
with open(file_path, 'rb') as f: for line in f.readlines(): print(line) with open(file_path, 'rb') as f: print(f.read())
This does not cause any exceptions when reading small files, but once reading large files, it can easily lead to memory leak MemoryError.
1.1 read([size]).
The read([size]) method reads size bytes from the current location of the file. If you do not specify the value of parameter size, it will read until the end of the file. All the data will be saved in one string object.
1.2 readlines().
This method reads one line at a time, so it takes up less memory to read and is more suitable for large files. But the readlines method will construct a list object to store each string line. So everything is saved in memory and memory overflow errors may occur.
2. How To Correctly Use read and readlines.
It is very dangerous to write the above code in a real running system. So let’s see how we can use it correctly.
2.1 read a binary file.
If the file is a binary file, the recommended way is to specify how many bytes the buffer read. Obviously the larger the buffer, the faster the read.
with open(file_path, 'rb') as f: while True: buf = f.read(1024) if buf: . else: break
2.2 read text file.
If it is a text file, you can use the readline method and directly iterate the file to read one line at a time, the efficiency is relatively low.
with open(file_path, 'rb') as f: while True: line = f.readline() if line: print(line) else: break
3. Question & Answer.
3.1 How to write python code to lazy read big file.
- My log file has 6GB size big data and when I use the python file object’s readlines function to read the log data, my python program hangs. My idea is to read the log data from my big log file piece by piece, it is something like a lazy load function, after reading the piece of data then I write the data to another file, then I can read the next piece of log data again. This can avoid reading the whole big file data into the memory at one time. But I do not know how to implement it, can anyone give me some help?
- You can use the python yield keyword to write a function that behaves like a lazy function as below.
''' This is the lazy function, in this function it will read a piece of chunk_size size data at one time. ''' def read_file_in_chunks(file_object, chunk_size=3072): while True: # Just read chunk_size size data. data = file_object.read(chunk_size) # If it reach to the end of the file. if not data: # Break the loop. break yield data # Open the big log data file. with open('big_log_file.dat') as f: # Invoke the above lazy file read data function. for piece in read_file_in_chunks(f): # Process the piece of data such as write the data to another file. process_data(piece) # First import the python fileinput module. >>> import fileinput >>> >>> for line in fileinput.input("C:\WorkSpace\Downloads\desktop.ini") File "", line 1 for line in fileinput.input("C:\WorkSpace\Downloads\desktop.ini") ^ SyntaxError: invalid syntax >>> >>> # Iterate the data file content. >>> for line in fileinput.input("C:\\WorkSpace\\Downloads\\log.dat"): # Print out each text line. . print(line) . Leave a Comment Cancel Reply
This site uses Akismet to reduce spam. Learn how your comment data is processed.
How to read large text files in Python?
In this article, we will try to understand how to read a large text file using the fastest way, with less memory usage using Python.
To read large text files in Python, we can use the file object as an iterator to iterate over the file and perform the required task. Since the iterator just iterates over the entire file and does not require any additional data structure for data storage, the memory consumed is less comparatively. Also, the iterator does not perform expensive operations like appending hence it is time-efficient as well. Files are iterable in Python hence it is advisable to use iterators.
Problem with readline() method to read large text files
In Python, files are read by using the readlines() method. The readlines() method returns a list where each item of the list is a complete sentence in the file. This method is useful when the file size is small. Since readlines() method appends each line to the list and then returns the entire list it will be time-consuming if the file size is extremely large say in GB. Also, the list will consume a large chunk of the memory which can cause memory leakage if sufficient memory is unavailable.
Read large text files in Python using iterate
In this method, we will import fileinput module. The input() method of fileinput module can be used to read large files. This method takes a list of filenames and if no parameter is passed it accepts input from the stdin, and returns an iterator that returns individual lines from the text file being scanned.
Note: We will also use it to calculate the time taken to read the file using Python time.
How to Read Large Text Files in Python

While we believe that this content benefits our community, we have not yet thoroughly reviewed it. If you have any suggestions for improvements, please let us know by clicking the “report an issue“ button at the bottom of the tutorial.
Python File object provides various ways to read a text file. The popular way is to use the readlines() method that returns a list of all the lines in the file. However, it’s not suitable to read a large text file because the whole file content will be loaded into the memory.
Reading Large Text Files in Python
We can use the file object as an iterator. The iterator will return each line one by one, which can be processed. This will not read the whole file into memory and it’s suitable to read large files in Python. Here is the code snippet to read large file in Python by treating it as an iterator.
import resource import os file_name = "/Users/pankaj/abcdef.txt" print(f'File Size is MB') txt_file = open(file_name) count = 0 for line in txt_file: # we can process file line by line here, for simplicity I am taking count of lines count += 1 txt_file.close() print(f'Number of Lines in the file is ') print('Peak Memory Usage =', resource.getrusage(resource.RUSAGE_SELF).ru_maxrss) print('User Mode Time =', resource.getrusage(resource.RUSAGE_SELF).ru_utime) print('System Mode Time =', resource.getrusage(resource.RUSAGE_SELF).ru_stime) File Size is 257.4920654296875 MB Number of Lines in the file is 60000000 Peak Memory Usage = 5840896 User Mode Time = 11.46692 System Mode Time = 0.09655899999999999 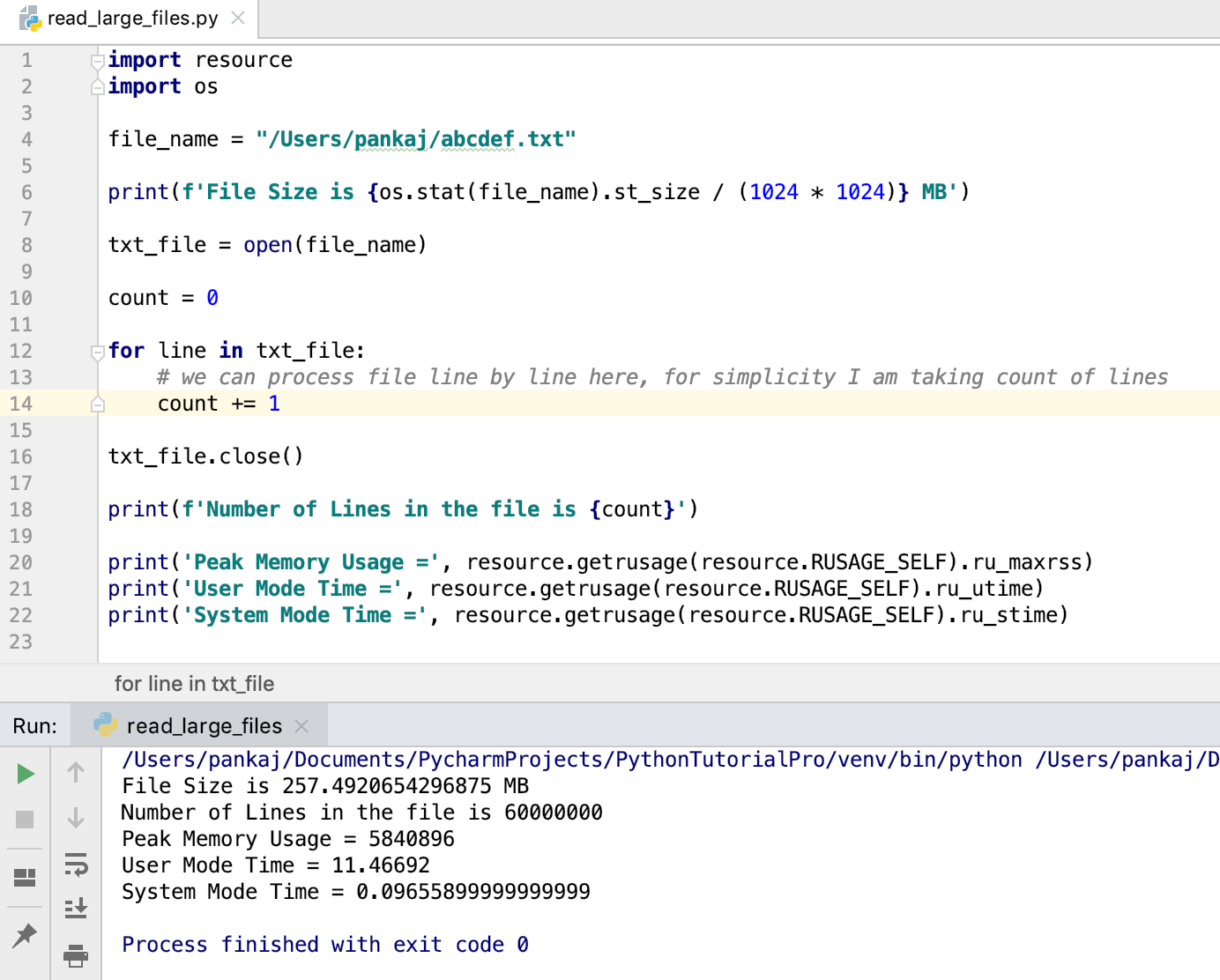
- I am using os module to print the size of the file.
- The resource module is used to check the memory and CPU time usage of the program.
We can also use with statement to open the file. In this case, we don’t have to explicitly close the file object.
with open(file_name) as txt_file: for line in txt_file: # process the line pass What if the Large File doesn’t have lines?
The above code will work great when the large file content is divided into many lines. But, if there is a large amount of data in a single line then it will use a lot of memory. In that case, we can read the file content into a buffer and process it.
with open(file_name) as f: while True: data = f.read(1024) if not data: break print(data) The above code will read file data into a buffer of 1024 bytes. Then we are printing it to the console. When the whole file is read, the data will become empty and the break statement will terminate the while loop. This method is also useful in reading a binary file such as images, PDF, word documents, etc. Here is a simple code snippet to make a copy of the file.
with open(destination_file_name, 'w') as out_file: with open(source_file_name) as in_file: for line in in_file: out_file.write(line) Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
How to open large csv or text files using Python
In this tutorial, we’ll learn how to open very large csv or text files using Python. My colleague once received a large csv file of 8GB. He wanted to take a peek at the content, but he couldn’t open it using any program he tried, Notepad, Excel, etc. The file was simply too large for the program to load.
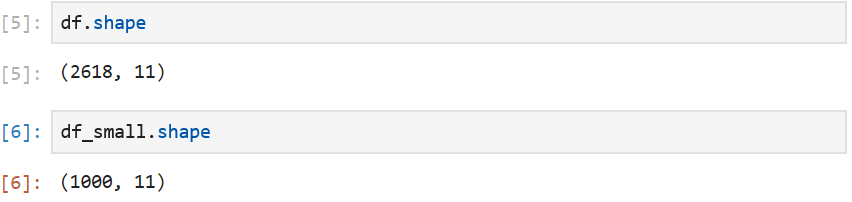
So he reached out to me for help. His request was relatively simple: open up the 8GB large csv file and potentially look at data in the first couple of thousand lines. This seemingly impossible task is easy when you pick the right tool – Python.
As shown above, the “large_data.csv” file contains 2618 rows and 11 columns of data in total. And we can also confirm that in the df_small variable, we only loaded the first 1,000 rows of data, also 11 columns.
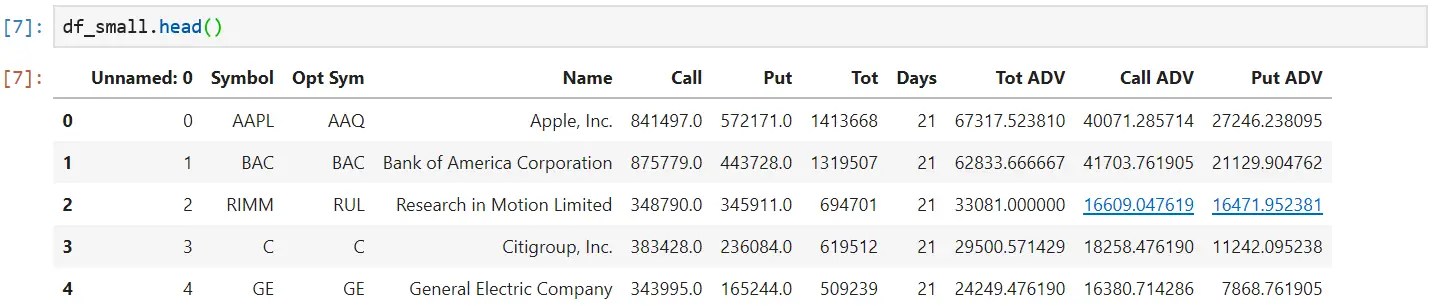
Typing df_small.head() shows the first 5 rows of data within the df_small dataframe. We can take a peek into the large file this way!
Next, what if we want to be able to open the data file using only Excel? You know, people like Excel so we have to stick to it!
Although we can’t use magic to allow Excel to open this 8GB file, we can “divide and conquer” by breaking down it into smaller files. For example, 8 files with 1GB each, or 16 files with 500MB each. A modern version of Excel can handle those file sizes easily.
This time, we’ll load the dataframe slightly differently – with an optional argument chunksize . Again, for demonstration purpose, we are using a much smaller file.
df = pd.read_csv('large_data.csv', chunksize = 900)Without getting into too much technical detail, the chunksize argument allows us to load data in chunks, with each chunk having a size of 900 rows of data in our example. The number of chunks is determined automatically by the program. Given that our csv file contains 2,618 rows, we expect to see 2618 / 900 = 2.9, which means 3 chunks in total. The first two chunks contain 900 rows, and the last chunk contains the remaining 818 rows.

Let’s see if that’s true.
We’ve successfully loaded and broken down one file into smaller pieces, next let’s save them into smaller individual files.
i = 1 for file in df: file.to_csv(f'file_.csv') i += 1
Putting it All Together
import pandas as pd df = pd.read_csv('large_data.csv', chunksize = 900) df_small = pd.read_csv('large_data.csv', nrows = 1000) i = 1 for file in df: print(file.shape) file.to_csv(f'file_.csv') i += 1We used only 8 lines of code to solve what seems impossible to achieve in Excel. I hope you are starting to love Python ❤️.