- @OneToOne
- 5.2 @Embedded
- 5.3 Односторонний OneToOne
- 5.4 Двусторонний OneToOne
- One-to-One Relationship in JPA
- Get started with Spring Data JPA through the reference Learn Spring Data JPA course:
- 1. Overview
- Further reading:
- Overview of JPA/Hibernate Cascade Types
- Hibernate One to Many Annotation Tutorial
- 2. Description
- 3. Using a Foreign Key
- 3.1. Modeling With a Foreign Key
- 3.2. Implementing With a Foreign Key in JPA
- 4. Using a Shared Primary Key
- 4.1. Modeling With a Shared Primary Key
- 4.2. Implementing With a Shared Primary Key in JPA
- 5. Using a Join Table
- 5.1. Modeling With a Join Table
- 5.2. Implementing With a Join Table in JPA
- 6. Conclusion
@OneToOne
Есть еще один интересный и довольно специфический случай отношений между двумя Entity-классами – это отношение один-к-одному.
Я называю этот случай очень специфическим, так как это больше о Java-объектах, чем о базе данных. В базе данных есть всего два варианта связи между таблицами:
- Строка таблицы содержит ссылку на id другой таблицы.
- Служебная таблица используется для связи many-to-many.
В случае же с Entity-классами могут быть варианты, которые описываются несколькими аннотациями:
Ниже мы рассмотрим самые популярные из них.
5.2 @Embedded
Самый простой вариант связи one-to-one мы, кстати, уже рассмотрели – это аннотация @Embedded . В этом случае у нас два класса хранятся в одной таблице в базе.
Допустим, мы хотим хранить адрес пользователя в классе UserAddress:
@Embeddable class UserAddress < @Column(name="user_address_country") public String country; @Column(name="user_address_city") public String city; @Column(name="user_address_street") public String street; @Column(name="user_address_home") public String home; > Тогда нам нужно просто добавить поле с этим адресом в класс User:
@Entity @Table(name="user") class User < @Column(name="id") public Integer id; @Embedded public UserAddress address; @Column(name="created_date") public Date createdDate; > Все остальное сделает Hibernate: данные будут храниться в одной таблице, но при написании HQL-запросов тебе нужно будет оперировать именно полями классов.
select from User where address.city = 'Paris' 5.3 Односторонний OneToOne
Представим теперь ситуацию: у нас есть исходная таблица employee и task, который ссылается на employee. Но мы точно знаем, что на одного пользователя может быть назначена максимум одна задача. Тогда для описания этой ситуации мы можем воспользоваться аннотацией @OneToOne .
@Entity @Table(name="task") class EmployeeTask < @Column(name="id") public Integer id; @Column(name="name") public String description; @OneToOne @JoinColumn(name = "employee_id") public Employee employee; @Column(name="deadline") public Date deadline; > Hibernate будет следить за тем, чтобы не только у одной задачи был один пользователь, но и чтобы у одного пользователя была только одна задача. В остальном этот случай практически ничем не отличается от @ManyToOne .
5.4 Двусторонний OneToOne
Предыдущий вариант может быть немного неудобным, так как часто хочется не просто задаче присвоить сотрудника, но и сотруднику назначить задачу.
Для этого можно добавить поле EmployeeTask в класс Employee и выставить ему правильные аннотации.
@Entity @Table(name="employee") class Employee < @Column(name="id") public Integer id; @OneToOne(cascade = CascadeType.ALL, mappedBy="employee") private EmployeeTask task; > Важно! У таблицы employee нет поля task_id, вместо этого для установления связи между таблицами используется поле employee_id таблицы task.
Установление связи между объектами выглядит так:
Employee director = session.find(Employee.class, 4); EmployeeTask task = session.find(EmployeeTask.class, 101); task.employee = director; director.task = task; session.update(task); session.flush(); Для удаления связи ссылки тоже нужно удалить у обоих объектов:
Employee director = session.find(Employee.class, 4); EmployeeTask task = director.task; task.employee = null; session.update(task); director.task = null; session.update(director); session.flush(); One-to-One Relationship in JPA
![]()
The Kubernetes ecosystem is huge and quite complex, so it’s easy to forget about costs when trying out all of the exciting tools.
To avoid overspending on your Kubernetes cluster, definitely have a look at the free K8s cost monitoring tool from the automation platform CAST AI. You can view your costs in real time, allocate them, calculate burn rates for projects, spot anomalies or spikes, and get insightful reports you can share with your team.
Connect your cluster and start monitoring your K8s costs right away:
![]()
We rely on other people’s code in our own work. Every day.
It might be the language you’re writing in, the framework you’re building on, or some esoteric piece of software that does one thing so well you never found the need to implement it yourself.
The problem is, of course, when things fall apart in production — debugging the implementation of a 3rd party library you have no intimate knowledge of is, to say the least, tricky.
Lightrun is a new kind of debugger.
It’s one geared specifically towards real-life production environments. Using Lightrun, you can drill down into running applications, including 3rd party dependencies, with real-time logs, snapshots, and metrics.
Learn more in this quick, 5-minute Lightrun tutorial:
![]()
Slow MySQL query performance is all too common. Of course it is. A good way to go is, naturally, a dedicated profiler that actually understands the ins and outs of MySQL.
The Jet Profiler was built for MySQL only, so it can do things like real-time query performance, focus on most used tables or most frequent queries, quickly identify performance issues and basically help you optimize your queries.
Critically, it has very minimal impact on your server’s performance, with most of the profiling work done separately — so it needs no server changes, agents or separate services.
Basically, you install the desktop application, connect to your MySQL server, hit the record button, and you’ll have results within minutes:
![]()
DbSchema is a super-flexible database designer, which can take you from designing the DB with your team all the way to safely deploying the schema.
The way it does all of that is by using a design model, a database-independent image of the schema, which can be shared in a team using GIT and compared or deployed on to any database.
And, of course, it can be heavily visual, allowing you to interact with the database using diagrams, visually compose queries, explore the data, generate random data, import data or build HTML5 database reports.
![]()
The Kubernetes ecosystem is huge and quite complex, so it’s easy to forget about costs when trying out all of the exciting tools.
To avoid overspending on your Kubernetes cluster, definitely have a look at the free K8s cost monitoring tool from the automation platform CAST AI. You can view your costs in real time, allocate them, calculate burn rates for projects, spot anomalies or spikes, and get insightful reports you can share with your team.
Connect your cluster and start monitoring your K8s costs right away:
Get started with Spring Data JPA through the reference Learn Spring Data JPA course:
We’re looking for a new Java technical editor to help review new articles for the site.
1. Overview
In this tutorial, we’ll have a look at different ways of creating one-to-one mappings in JPA.
We’ll need a basic understanding of the Hibernate framework, so please check out our guide to Hibernate 5 with Spring for extra background.
Further reading:
Overview of JPA/Hibernate Cascade Types
Hibernate One to Many Annotation Tutorial
In this tutorial we’ll have a look at the one-to-many mapping using JPA annotations with a practical example.
2. Description
Let’s suppose we are building a user management system, and our boss asks us to store a mailing address for each user. A user will have one mailing address, and a mailing address will have only one user tied to it.
This is an example of a one-to-one relationship, in this case between user and address entities.
Let’s see how we can implement this in the next sections.
3. Using a Foreign Key
3.1. Modeling With a Foreign Key
Let’s have a look at the following ER diagram, which represents a foreign key-based one-to-one mapping:
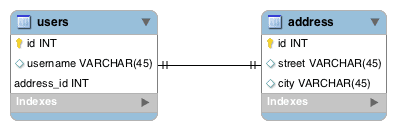
In this example, the address_id column in users is the foreign key to address.
3.2. Implementing With a Foreign Key in JPA
First, let’s create the User class and annotate it appropriately:
@Entity @Table(name = "users") public class User < @Id @GeneratedValue(strategy = GenerationType.AUTO) @Column(name = "id") private Long id; //. @OneToOne(cascade = CascadeType.ALL) @JoinColumn(name = "address_id", referencedColumnName = "id") private Address address; // . getters and setters >Note that we place the @OneToOne annotation on the related entity field, Address.
Also, we need to place the @JoinColumn annotation to configure the name of the column in the users table that maps to the primary key in the address table. If we don’t provide a name, Hibernate will follow some rules to select a default one.
Finally, note in the next entity that we won’t use the @JoinColumn annotation there. This is because we only need it on the owning side of the foreign key relationship. Simply put, whoever owns the foreign key column gets the @JoinColumn annotation.
The Address entity turns out a bit simpler:
@Entity @Table(name = "address") public class Address < @Id @GeneratedValue(strategy = GenerationType.AUTO) @Column(name = "id") private Long id; //. @OneToOne(mappedBy = "address") private User user; //. getters and setters >We also need to place the @OneToOne annotation here too. That’s because this is a bidirectional relationship. The address side of the relationship is called the non-owning side.
4. Using a Shared Primary Key
4.1. Modeling With a Shared Primary Key
In this strategy, instead of creating a new column address_id, we’ll mark the primary key column (user_id) of the address table as the foreign key to the users table:
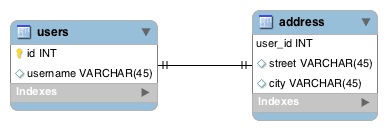
We’ve optimized the storage space by utilizing the fact that these entities have a one-to-one relationship between them.
4.2. Implementing With a Shared Primary Key in JPA
Notice that our definitions change only slightly:
@Entity @Table(name = "users") public class User < @Id @GeneratedValue(strategy = GenerationType.AUTO) @Column(name = "id") private Long id; //. @OneToOne(mappedBy = "user", cascade = CascadeType.ALL) @PrimaryKeyJoinColumn private Address address; //. getters and setters >@Entity @Table(name = "address") public class Address < @Id @Column(name = "user_id") private Long id; //. @OneToOne @MapsId @JoinColumn(name = "user_id") private User user; //. getters and setters >The mappedBy attribute is now moved to the User class since the foreign key is now present in the address table. We’ve also added the @PrimaryKeyJoinColumn annotation, which indicates that the primary key of the User entity is used as the foreign key value for the associated Address entity.
We still have to define an @Id field in the Address class. But note that this references the user_id column, and it no longer uses the @GeneratedValue annotation. Also, on the field that references the User, we’ve added the @MapsId annotation, which indicates that the primary key values will be copied from the User entity.
5. Using a Join Table
One-to-one mappings can be of two types: optional and mandatory. So far, we’ve seen only mandatory relationships.
Now let’s imagine that our employees get associated with a workstation. It’s one-to-one, but sometimes an employee might not have a workstation and vice versa.
5.1. Modeling With a Join Table
The strategies that we have discussed until now force us to put null values in the column to handle optional relationships.
Typically, we think of many-to-many relationships when we consider a join table, but using a join table in this case can help us to eliminate these null values:
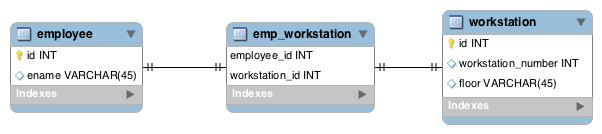
Now, whenever we have a relationship, we’ll make an entry in the emp_workstation table and avoid nulls altogether.
5.2. Implementing With a Join Table in JPA
Our first example used @JoinColumn. This time, we’ll use @JoinTable:
@Entity @Table(name = "employee") public class Employee < @Id @GeneratedValue(strategy = GenerationType.AUTO) @Column(name = "id") private Long id; //. @OneToOne(cascade = CascadeType.ALL) @JoinTable(name = "emp_workstation", joinColumns = < @JoinColumn(name = "employee_id", referencedColumnName = "id") >, inverseJoinColumns = < @JoinColumn(name = "workstation_id", referencedColumnName = "id") >) private WorkStation workStation; //. getters and setters >@Entity @Table(name = "workstation") public class WorkStation < @Id @GeneratedValue(strategy = GenerationType.AUTO) @Column(name = "id") private Long id; //. @OneToOne(mappedBy = "workStation") private Employee employee; //. getters and setters >@JoinTable instructs Hibernate to employ the join table strategy while maintaining the relationship.
Also, Employee is the owner of this relationship, as we chose to use the join table annotation on it.
6. Conclusion
In this article, we learned different ways of maintaining a one-to-one association in JPA and Hibernate, and when to use each.
The source code for this article can be found over on GitHub.
![]()
Slow MySQL query performance is all too common. Of course it is. A good way to go is, naturally, a dedicated profiler that actually understands the ins and outs of MySQL.
The Jet Profiler was built for MySQL only, so it can do things like real-time query performance, focus on most used tables or most frequent queries, quickly identify performance issues and basically help you optimize your queries.
Critically, it has very minimal impact on your server’s performance, with most of the profiling work done separately — so it needs no server changes, agents or separate services.
Basically, you install the desktop application, connect to your MySQL server, hit the record button, and you’ll have results within minutes: