Объектно ориентированное программирование на Си без плюсов. Часть 1. Введение
Каждый раз, когда начинаешь решать какую-либо большую задачу, то на пути появляется множество маленьких. И найденные или не найденные решения маленьких подзадач превращаются в то, что мы в дальнейшем называем опытом. Но к сожалению, если не пользуешься чем-то постоянно, то когда-то найденные оригинальные решения со временем начинаешь забывать, а когда необходимо, начинаешь вспоминать и с удивлением, а иногда и с не пониманием долго смотришь на свои же шедевры.
Статья рассчитана на тех кто уже знаком с Си, а все примеры ориентированы на ОС Linux. Мои познания Windows закончились на «WinXP», после которой в Windows стало уже очень много политики («безопасности») и коммерческой составляющей, но я сейчас не об этом и надеюсь, что здесь вы найдёте для себя полезные моменты, а если я в чём-то не прав или заблуждаюсь, то поправите.
И так, я решил попробовать писать в стиле объектно ориентированного программирования (далее ООП) на Си без плюсов. Многие скажут, что писать в стиле объектно ориентированного программирования (далее ООП) не для Си, и разные приёмы написания это — «псевдо-ООП». Но лично я считаю ООП всего лишь абстрактной парадигмой, определяющей стиль написания ПО и не более чем. А Си очень мощный и самодостаточный язык программирования.
Так сложилось, что изучать традиции ООП я начал с Delphi и Java, являющихся, как считается, на 100% объектно ориентированными языками программирования, а потому аналогия решений у меня ассоциируется именно с ними. И далее в тексте я иногда буду на них ссылаться, что надеюсь не испортит суть полного понимания.
В соответствии с определениями ООП все сущности должны быть объектами обладающими некоторыми свойствами и принадлежать к определённому классу.
- Конструктор и деструктор для рождения и уничтожения объектов соответственно;
- Методы информирующие о изменении состояния (события);
- Методы определяющие поведение объектов.
Для написания классов я предлагаю постепенно в тексте вводить простые правила нотации:
- Новый файл — новый класс, как в Java. Вернее заголовочный файл mynewclass.h + основной файл mynewclass.c;
- Перед именем функции пишется имя класса, например: void myclass_namefunction(…);
- Перед новым определяемым типом пишется « t_ », например: t_mynewtype;
- В макросах все вновь вводимые переменные начинаются с двойного подчёркивания, например: __i;
1. Начну с конструктора и деструктора.
В Си нет понятия классов и объектов, но есть структуры, есть макросы, чего вполне, как оказалось достаточно. В качестве объекта класса можно рассматривать переменную типа структуры, а основная задача конструктора это выделение необходимой памяти, инициализация переменных, иных необходимых объектов и возврат указателя на память, где создаётся «объект». В структуре не может быть функций, но никто не запрещает иметь ссылку на другую функцию или структуру.
У деструктора обратная задача — навести порядок и высвободить задействованные вычислительные ресурсы.
В соответствии с принятой нотацией типовой конструктор это функция, которая может выглядеть, как-то так:
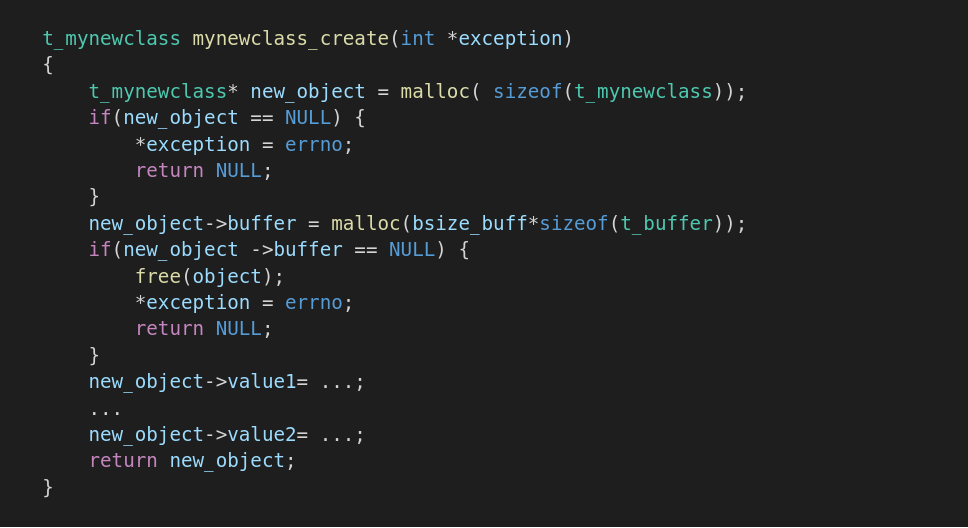
Ну, а деструктор соответственно:

Реализацию событий можно организовать при помощи указателей на функции. Я посчитал, что включать указатели на функции в общую структуру объекта нет смысла, да и расточительно выделять дополнительную память каждый раз при создании объекта. И, указатели на функции обратных вызовов (событий) решил объединять в отдельную структуру, имя которой содержит имя класса, а имена функций начинаются с «on_» например:

Таким образом, помещая объявленную структуру в заголовочный файл получаем аналогию интерфейса, как в Java, который можно использовать например так:
В структуру нашего нового класса добавляем указатель на тип t_mynewclass_events, т.е.:

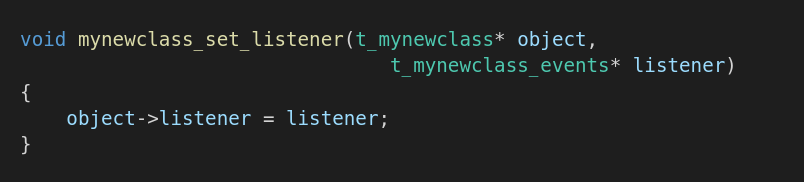
В файлах классах реализуем функцию «сеттер»:
В основном файле программы, используем всё это как-то так:
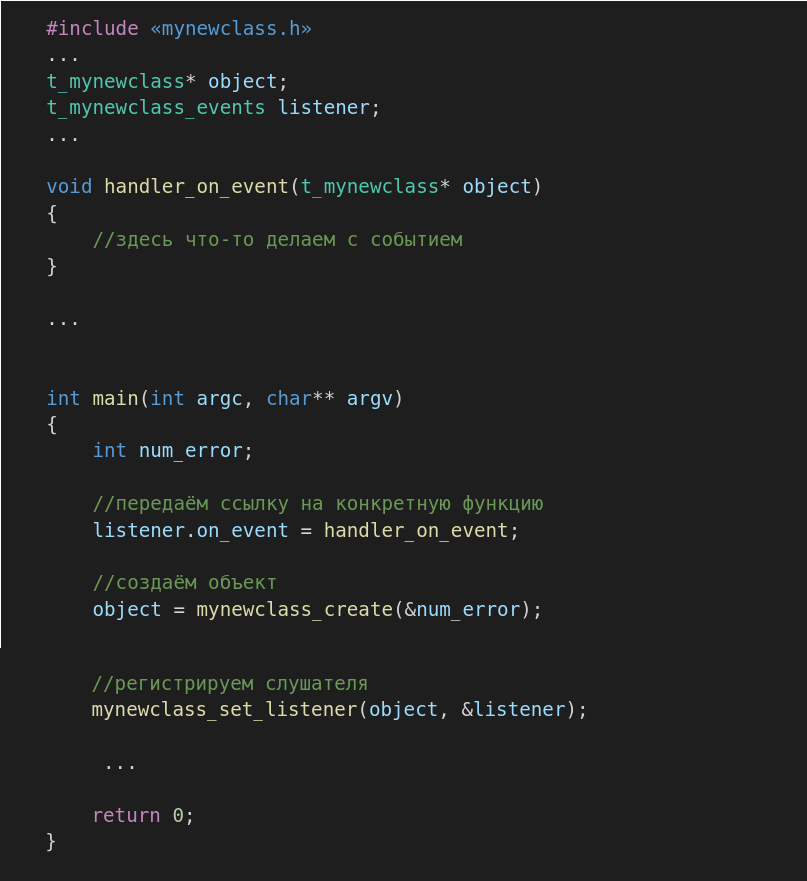
Ну, а в функциях класса вызываем событие так:

Собственно вот и вся реализация так называемого callback-а.
В части методов, определяющих поведение объекта и доступных из вне (т.е. публичных), я ещё раз повторюсь и обобщу принятое мной правило, это не включать в структуру объекта ссылки на функции (методы класса), а, просто, название функций начинать с имени класса, например: void myclass_namefunction(…);. Считаю, такое решение вполне рациональным. Принадлежность к классу всегда можно определить по имени функции, а единственное неудобство «много букв» простить.
Двигаемся далее. В основе ООП есть три основополагающих понятия: инкапсуляция, полиморфизм и наследование.
Смысл её в том, что бы разделить частное (protected, private … ) и общедоступное ( public, published … ). Частное это внутренняя «кухня» определённого класса доступ до которой ограничен.
- В заголовочном файле mynewclass.h пишем:

- Саму структуру определяем в файле mynewclass.с:
- Для доступа к полям структуры в заголовочном файле прописываем прототипы публичных функций:
- Реализация функций в файле mynewclass.с буде выглядеть как-то так:



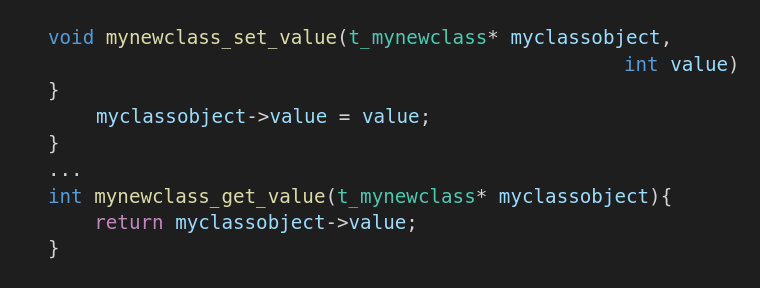
Теперь доступ к переменным структуры определяется «сетерами» и «гетерами», как в Java, а в структуре struct mynewclass могут быть приватные поля и методы объекта. Здесь стоит наверное отметить следующее, в одном процессе все методы (функции) для одного нашего «Класса» являются общими. А чтобы понимать с каким объектом должна отработать функция, то первым параметром отправляем ссылку на объект её вызывающего.
С инкапсуляцией надеюсь разобрались.
В моём понимании это способность функции обрабатывать входные параметры различных типов, и в Си для этого есть несколько интересных решений.
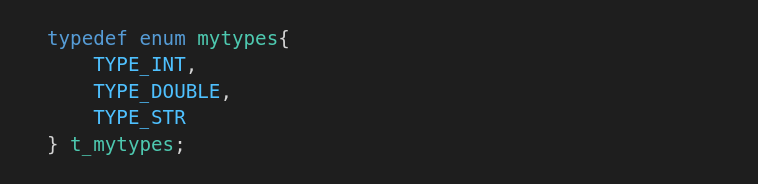
- Передача параметра в функцию через указатель void*, например так: В начале для красоты введём собственные наименования типов при помощи перечисления:
Тогда функцию оформляем следующим образом, например:

Вызов функции будет соответственно:

Надеюсь идея ясна и понятна.
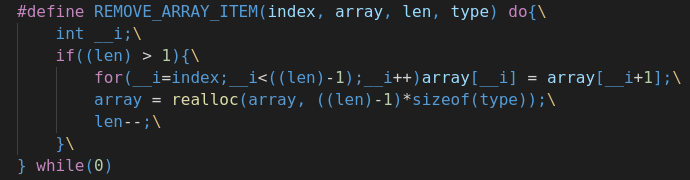
2. Можно задачу полиморфизма решить через определение макроса. В отличие от функции в макросах в качестве параметра можно прописать тип передаваемого параметра. Например ниже представлен макрос, который удаляет элементы из массива любого типа:
3. А можно в функцию передать любую другую функцию, например так:

Это вроде аналогичной функции Synchronize(@function) из Delphi, но сейчас не об этом.
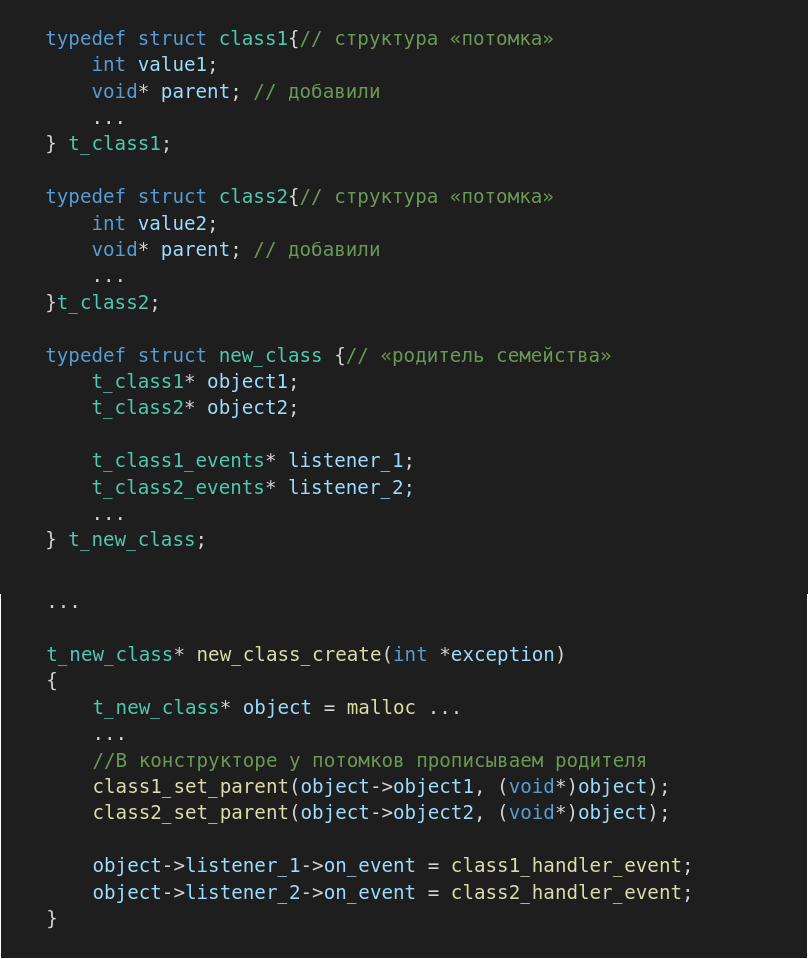
С наследованием в Си на самом деле не всё так, как хотелось бы. И вариант здесь похоже один — в структуру объекта включить указатель на структуру другого объекта, как-то так:

А потом даже можно написать:

Компилятор такую запись должен понять, но это всё равно не похоже на наследование свойств и методов от какого-то родительского класса, а скорее наоборот — порождение потомков с определёнными свойствами и методами принадлежащими новому «родителю семейства».
Но вот, что бы потомки знали, в случае обработки события, к какому экземпляру родителя оно относится, я предлагаю у потомков прописывать «фамилию родителя», то есть добавить в структуру каждого класса переменную указатель: void* parent и пару функций для работы с ней:

И, когда потомок вызовет указанную ему функцию-обработчик, мы сможем однозначно знать к какому экземпляру родителя это событие относится.
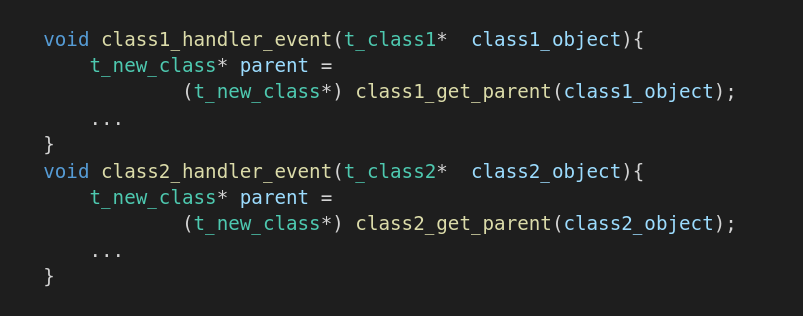
Такая реализация наследования может быть и не выглядит классической, но если посмотреть с другой стороны, то чего-то большего возможно и не нужно.
Хотя почему реализация не классическая? В Delphi при объявлении нового класса это обычная практика включать в класс поля переменных других классов.
В общем, разобрав реализацию основных понятий ООП для создания класса получился некий шаблон, где заголовочный файл myclass.h должен выглядеть как-то так:
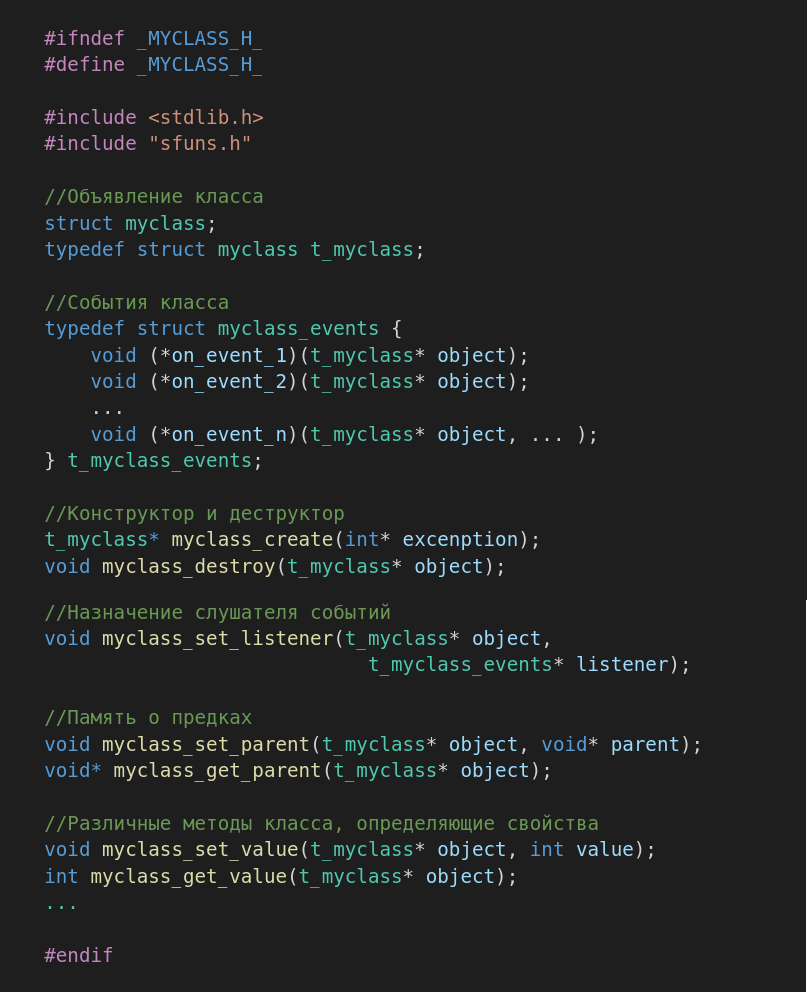
Соответственно файл myclass.с должен выглядеть как-то так:
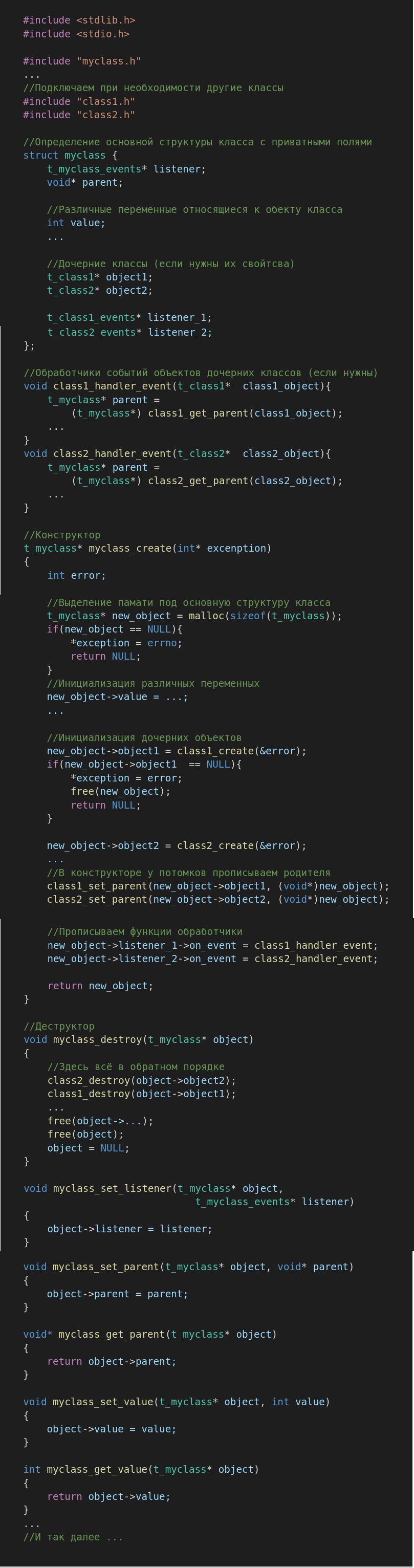
Теоретически, представленного выше, для создания объектов должно быть достаточно, а вот для практического применения и написания подавляющего большинства программ необходимо решение в виде таймера, но об этом я хочу рассказать в следующей части.