RSS-файл для Яндекс Турбо-страниц
Турбо-страницы позволяют пользователям посмотреть «легкую» версию сайта, которая загружается быстрее в десятки раз, а ведь это увеличивает вероятность, что посетитель останется на странице и найдет нужную информацию. Также на такие страницы можно добавить рекламные блоки и веб-аналитику.
Некоторые ограничения
| Количество символов в элементах , | 240 |
| Общее количество картинок в RSS-канале | 5000 |
| Количество картинок в одном элементе | 30 |
| Количество элементов | 500 |
| Размер RSS-канала | 15 МБ |
| Максимальное количество ссылок в элементе | 10 |
Генерация xml файла
' . $url . 'ОПИСАНИЕ_САЙТА ru '; $dbh = new PDO('mysql:dbname=DB_NAME;host=localhost', 'ЛОГИН', 'ПАРОЛЬ'); $sth = $dbh->prepare("SELECT `name`, `text` FROM `articles`"); $sth->execute(); $articles = $sth->fetchAll(PDO::FETCH_ASSOC); foreach ($articles as $row) < $text = $row['text']; // Удаление лишних тегов. $text = strip_tags($text, '![]()
'); // Замена относительных ссылок. $text = str_replace('src="https://snipp.ru/',%20'src="https://snipp.ru/php/'%20.%20$url%20.%20'/',%20$text);%20$text%20=%20str_replace('href="/', 'href="' . $url . '/', $text); $out .= ' - ' . $url . '/URL_СТРАНИЦЫ
' . $row['name'] . '
' . $text . ' ]]> '; > $out .= '
Пример сгенерированного файла
http://snipp.ru ru - http://snipp.ru/view/113
Релевантный поиск c помощью LIKE
Например, на сайте статей есть поиск, он ищет ключевое слово по полям: название статьи, title и основной текст. SQL запрос получается следующим:
]]> Далее URL фида нужно добавить в источники Турбо-страниц в Яндекс вебмастере, и после проверки в поисковой выдаче появится у иконка:
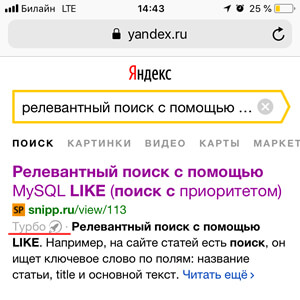
А сам сайт и меню будет следующего вида:
 |  |
Удаление турбо-страниц из выдачи
Если отключить и удалить в вебмастере источник (ссылку на RSS канал), то в выдаче Яндекса турбо-страницы все равно останутся. Для полного удаления нужно вернуть источник и выставить false для всех статей.
Парсим выдачу Яндекса
Я начал заниматься SEO недавно, и сразу же столкнулся с задачей определения позиций продвигаемых сайтов по ключевым словам в поисковиках. Задача тривиальная и решается на ура различным ПО, которое у всех SEO-специалистов на устах: Semonitor, AllSubmitter, etc. Помимо проприетарности, которой попахивает от всех подобного рода программ, в них есть, как это не парадоксально, ряд технических моментов, из-за которых хочется выбросить компьютер в окно.
Я бы не прочь купить Semonitor, но попользовав демо-версию, решил от этой идеи отказаться — на оф.сайте программы доступная для скачивания версия у меня глючила, требовала обновить себя, а после выпрошенного у меня обновления и вовсе отказывалась заниматься анализом позиций. Самому настроить, как Вы понимаете, нельзя.
AllSubmitter в этом плане получше, позволяет даже кастомизировать регулярные выражения для поисковиков, что вроде как делает этот софт устойчивым к смене формата выдачи, однако и с ним не все слава богу — когда 18.08.2008г. Яндекс вдруг изменил формат выдачи результатов поиска, вместе с тем поменяв и URL ссылок (возможно, эксперименты с вводом учета переходов, подробнее об этом писалось здесь), то и AllSub оказался бессилен. Правда, на следующий день Яндекс снова вернулся к старому формату выдачи, но прецедент, тем не менее, произошел.
Я тогда ради интереса изобретал велосипед: решил написать анализатор позиций, причем на PHP. У меня не было цели дойти до production’а, просто хотелось прочувствовать, как работают всякие там Semonitor’ы и Allsubmitter’ы. А потому, написав классы для парсинга Яши, Гугла и Рамблера, потестив и убедившись, что все пашет, удовлетворенно забыл, поскольку был AllSubmitter, и огород городить было незачем, было предостаточно и других задач.
Постановка задачи
Когда на Хабре написали про PHP-класс для работы с Яндекс.XML и я обильно прокомментировался по этому поводу, то по наличию плюсов в карму понял, что тема неплоха для оформления в статью, тем более что возможность появилась — я вылез из минусов. И хотя речь там шла немного о другом — об организации поиска по сайту, используя Yandex.XML, задача анализа позиций сайта по ключевым словам и фразам пересекается с первой. Итак, моя задача:
создать анализатор позиций сайтов в выдаче поисковых систем (пока Яндекса)
Решение
Во-первых,
- text — текст поискового запроса. URL-кодированный.
- p — номер страницы выдачи (p=0, 1, 2. ). Without comments
- numdoc — число выдаваемых результатов на страницу(numdoc=10, 20, 30, 50; допустимы только эти значения и никакие более). Для анализа позиций сайта по ключевым словам лучше всего юзать наибольшее значение, т.к. явное уменьшение нагрузки на сервер и, как следствие — меньше подозрений, что «Я, робот»
Во-вторых,
Выдача Яндекса подвергается разбору на нужные нам составляющие, путем прогона через регулярное выражение вида:
В результате чего получается массив (в нем numdoc элементов) массивов (3 элемента в подмассиве: html с одним результатом выдачи, url найденной страницы выдачи, ее заголовок).
В итоге,
- получаю первую страницу с выдачей
- если это не «страница недоверия» Яндекса с капчей — прогоняю через регвыр, перебираю результаты в поиске нужного.
- если нахожу, возвращаю результат — номер позиции страницы в выдаче, не нахожу — получаю следующую страницу и возвращаюсь к п.2, подождав секунды 3-5
- resultsLimit — ограничение по глубине поиска, по умолчанию
люблю ставить 200 - url — имя хоста, который ищем в выдаче. Учитывается любая страница с этого хоста
- keyword — запрос к поисковику.
Реализовано
это посредством иерархии классов (чтобы при надобности легко расширять функциональность анализатора на другие поисковики).
Абстрактный класс — SomeAnalyzer:
- abstract class SomeAnalyzer
- //// ИНТЕРФЕЙС
- // функция анализа
- public abstract function analyzeThis($url);
- // получение имени хоста из url (parse_url с дополнительным функционалом, поскольку убедился что просто parse_url не всегда почему-то работает, когда url слишком неудобочитаемый)
- public function getHost($url)
- $url=@parse_url($url);
- if ($url[ ‘path’ ] && !$url[ ‘host’ ])
- $url[ ‘host’ ]=$url[ ‘path’ ];
- $url[ ‘host’ ]=ereg_replace( «/.*$» , «» , $url[ ‘host’ ]);
- $url[ ‘host’ ]=ereg_replace( «^www\.» , «» , $url[ ‘host’ ]);
- return $url[ ‘host’ ];
- >
- //// РЕАЛИЗАЦИЯ
- // функция сравнения 2-х url на предмет принадлежности к одному хосту
- protected function compareURL($url1, $url2)
- $url1=$ this ->getHost($url1);
- $url2=$ this ->getHost($url2);
- return (strtoupper($url1[ ‘host’ ])==strtoupper($url2[ ‘host’ ])? true : false );
- >
- >
Класс анализатора выдачи Яндекса:
- class YandexAnalyzer extends SomeAnalyzer
- //// ИНТЕРФЕЙС
- // настройки
- public $resultsLimit=200; // лимит результатов выдачи
- public $url;
- public $keyword;
- public $resultsOnPage=50; // можно только 10, 20, 30, 50
- // функция анализа
- public function analyzeThis($url, $keyword= » )
- $ this ->url=$url;
- $ this ->keyword=$keyword;
- $x=0;
- while ($x*$ this ->resultsOnPageresultsLimit-1)
- if ($results=$ this ->analyzePage(str_replace(array( «\r» , «\n» , «\t» ), » , $ this ->downloadPage($x))))
- $results[0]=$x*$ this ->resultsOnPage+$results[0];
- return $results;
- >
- $x++;
- sleep(rand(3, 5));
- >
- return false ;
- >
- //// РЕАЛИЗАЦИЯ
- protected $regexpParseResults= ‘#
- .*
- protected $urlMask= ‘http://yandex.ru/yandsearch?text=[KEYWORD]&p=[PAGE_NUMBER]&numdoc=[RESULTS_ON_PAGE]’ ;
- protected function downloadPage($pageNumber)
- $mask=str_replace( ‘[KEYWORD]’ , urlencode($ this ->keyword), $ this ->urlMask);
- $mask=str_replace( ‘[PAGE_NUMBER]’ , $pageNumber, $mask);
- $mask=str_replace( ‘[RESULTS_ON_PAGE]’ , $ this ->resultsOnPage, $mask);
- return file_get_contents($mask);
- >
- protected function analyzePage($content)
- if (preg_match_all($ this ->regexpParseResults, $content, $matches, PREG_SET_ORDER)!== false )
- if (count($matches) <=0)
- deb( ‘
Не найдено вхождений или ошибка парсера: возможно гугл подозревает, что Вы робот!‘ ); - else
- foreach ($matches as $num=>$match)
- if ($ this ->compareURL($match[1], $ this ->url))
- return array($num+1, $match[1], $match[2]);
- >
- >
- else deb( ‘Не найдено вхождений или ошибка парсера: возможно йандекс подозревает, что Вы робот!‘ );
- return false ;
- >
- >
Результат
Вот небольшой код для тестирования:
- $url= «vinzavod.ru» ;
- $keywords=array(
- ‘винзавод’ ,
- ‘алкоголь производство’ ,
- ‘производство алкоголя’ ,
- ‘продажа алкоголя’ ,
- ‘производители алкоголя’ ,
- ‘вино’ ,
- ‘вина’ ,
- ‘производство вина’ ,
- ‘продажа вина’ ,
- ‘коньяк’ ,
- ‘коньяки’ ,
- ‘производство коньяка’ ,
- ‘продажа коньяков’ ,
- ‘продажа коньяка’ ,
- ‘продажа коньяк’ ,
- ‘настойка’ ,
- ‘настойки’ ,
- ‘производство настоек’ ,
- ‘продажа настоек’ ,
- ‘вермут’ ,
- ‘вермуты’ ,
- ‘производство вермута’ ,
- ‘портвейн’ ,
- ‘портвейны’ ,
- ‘портвейн 777’ ,
- ‘продажа портвейнов’ ,
- ‘алкоголь’ ,
- ‘алкогольная продукция’ ,
- ‘фирменный алкоголь’ ,
- ‘алкогольные напитки’ ,
- ‘классические алкогольные напитки’
- );
- $g= new YandexAnalyzer();
- foreach ($keywords as $keyword)
- if ($res=$g->analyzeThis($url, $keyword))
- deb( ‘‘ .$res[0]. ‘-я позиция сайта ‘ .$url. ‘ по фразе ‘»‘ .$keyword. ‘»‘ );
- >
- else
- deb($url. ‘ не найден в первых ‘ .$g->resultsLimit. ‘ результатах по фразе «‘ .$keyword. ‘»‘ );
- sleep(rand(3, 5));
- >
и результат тестирования:
4-я позиция сайта vinzavod.ru по фразе «винзавод»
13-я позиция сайта vinzavod.ru по фразе «алкоголь производство»
158-я позиция сайта vinzavod.ru по фразе «производство алкоголя»
45-я позиция сайта vinzavod.ru по фразе «продажа алкоголя»
vinzavod.ru не найден в первых 300 результатах по фразе «производители алкоголя»
181-я позиция сайта vinzavod.ru по фразе «вино»
255-я позиция сайта vinzavod.ru по фразе «вина»
4-я позиция сайта vinzavod.ru по фразе «производство вина»
56-я позиция сайта vinzavod.ru по фразе «продажа вина»
94-я позиция сайта vinzavod.ru по фразе «коньяк»
56-я позиция сайта vinzavod.ru по фразе «коньяки»
7-я позиция сайта vinzavod.ru по фразе «производство коньяка»
5-я позиция сайта vinzavod.ru по фразе «продажа коньяков»
7-я позиция сайта vinzavod.ru по фразе «продажа коньяка»
5-я позиция сайта vinzavod.ru по фразе «продажа коньяк»
11-я позиция сайта vinzavod.ru по фразе «настойка»
17-я позиция сайта vinzavod.ru по фразе «настойки»
3-я позиция сайта vinzavod.ru по фразе «производство настоек»
1-я позиция сайта vinzavod.ru по фразе «продажа настоек»
30-я позиция сайта vinzavod.ru по фразе «вермут»
25-я позиция сайта vinzavod.ru по фразе «вермуты»
32-я позиция сайта vinzavod.ru по фразе «производство вермута»
32-я позиция сайта vinzavod.ru по фразе «портвейн»
15-я позиция сайта vinzavod.ru по фразе «портвейны»
93-я позиция сайта vinzavod.ru по фразе «портвейн 777»
4-я позиция сайта vinzavod.ru по фразе «продажа портвейнов»
Перспективы и планы на будущее
- обуздать как минимум тройку Яндекс, Гугл, Рабмлер.
- сделать человеческую оболочку для пользования, лучший вариант — ajax-приложение, с поддержкой проектов и сохранением на сервере результатов анализов