Метод парзеновского окна
Метод парзеновского окна — метод байесовской классификации, основанный на непараметрическом восстановлении плотности по имеющейся выборке.
После ввода метрики, метод парзеновского окна можно использовать, не опираясь на вероятностную природу данных.
Идея метода
В основе подхода лежит идея о том, что плотность выше в тех точках, рядом с которыми находится большое количество объектов выборки.
Если мощность множества элементарных исходов много меньше размера выборки, то в качестве восстановленной по выборке плотности мы вполне можем взять и гистограмму значений выборки.
В противном случае (например, непрерывном) данный подход не применим, так как плотность концентрируется вблизи обучающих объектов, и функция распределения претерпевает резкие скачки. Приходится использовать восстановление методом Парзена-Розенблатта.
Формулы
Парзеновская оценка плотности имеет вид:
Соответствующее решающее правило, полученное после преобразований:
Функция ядра (окна)
— произвольная четная функция, называемая функцией ядра или окна. Термин окно происходит из классического вида функции:
Восстановленная плотность имеет такую же степень гладкости, как и функция ядра. Поэтому на практике обычно используются все же более гладкие функции.
Вид функции окна не влияет на качество классификации определяющим образом.
Ширина окна
Ширина окна сильно влияет на качество восстановления плотности и, как следствие, классификации. При слишком малом окне мы получаем тот же эффект, что и при использовании гистограммы значений. При слишком большом окне плотность вырождается в константу.
Для нахождения оптимальной ширины окна удобно использовать принцип максимума правдоподобия с исключением объектов по одному (leave-one-out, LOO).
Возможные проблемы
Проблема локальных сгущений
Возникает в тех случаях, когда распределение объектов в пространстве сильно неравномерно, и одно и то же значение ширины окна h приводит к чрезмерному сглаживанию плотности в одних местах, и недостаточному сглаживанию в других. Проблему решают окна переменной ширины.
Проблема «проклятия размерности»
Если число признаков велико и учитываются все они, то все объекты оказываются примерно на одинаковом расстоянии друг от друга. Выход заключается в понижении размерности с помощью преобразования пространства признаков, либо путём отбора информативных признаков.
См. также
Литература
До указанного срока статья не должна редактироваться другими участниками проекта MachineLearning.ru. По его окончании любой участник вправе исправить данную статью по своему усмотрению и удалить данное предупреждение, выводимое с помощью шаблона >.
См. также методические указания по использованию Ресурса MachineLearning.ru в учебном процессе.
Методы парзеновского окна и потенциальных функций
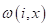
На предыдущем занятии мы с вами рассмотрели простейший алгоритм метрической классификации k ближайших соседей. И отметили существенный недостаток его весовых коэффициентов :
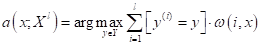
они принимают только два значения:
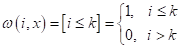
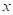
Я напомню, что индекс i означает i-й образ в упорядоченной по возрастанию расстояний последовательности относительно классифицируемого вектора :
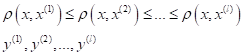
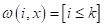
просто выделяет k ближайших соседей для вектора . Но, наверное, было бы логично учитывать соседние объекты с учетом расстояния 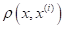 до них: чем оно больше, тем меньший вес должно иметь данное наблюдение.
до них: чем оно больше, тем меньший вес должно иметь данное наблюдение.
(близкие соседи несут больший вклад, чем далекие). Для реализации этой идеи веса предлагается выбирать с использованием некоторой невозрастающей функции 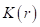 (ее еще называют ядром):
(ее еще называют ядром):
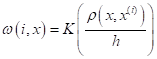
Причем, часто ее выбирают ограниченной (финитной) на интервале [0; 1] и симметричной относительно нуля (четной):
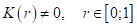
Такие ядра получили название окно Парзена или парзеновские окна.
Для окон параметр h в формуле весов определяет область охвата объектов относительно вектора (с центром в точке ). Например, если h = 1, то максимальное ненулевое расстояние будет равно единице. Если h взять равным 4, то расстояние (охват) также увеличится в 4 раза.
Остается вопрос, какую функцию ядра взять? Часто на практике используют следующие варианты:
Здесь 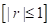 — индикатор того, что
— индикатор того, что 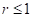 , то есть, возвращается 1, если это так и 0 – в противном случае.
, то есть, возвращается 1, если это так и 0 – в противном случае.
В результате, мы получаем следующий алгоритм классификации с помощью парзеновского окна:
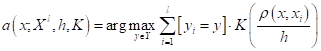
Здесь мы уже можем не сортировать наблюдения по расстояниям, т.к. функция расстояния используется в самом ядре.
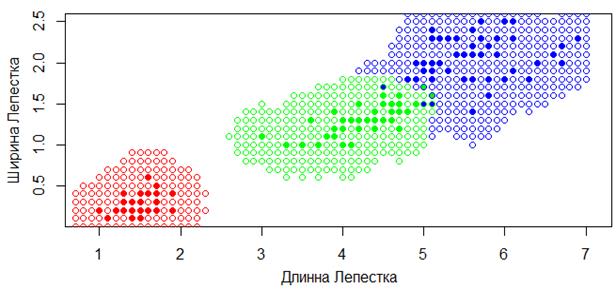
Фактически, алгоритм работает по похожему принципу, что и метод k ближайших соседей, только рассматривает всех соседей на расстоянии h и с учетом расстояния до них. Например, вот так выглядит карта классификации для квадратического парзеновского окна с параметром h=0,4 в пространстве двух признаков для цветов ирисов:
В сравнении та же карта классификации для метода k ближайших соседей при k=6, выглядит следующим образом:
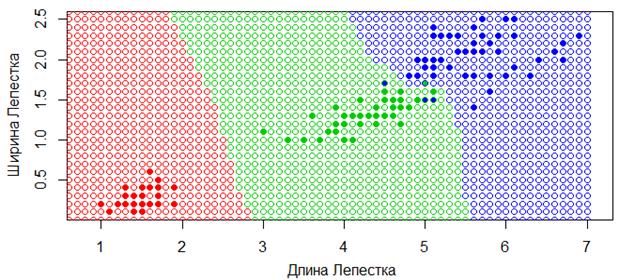
Видите, как заметно отличаются результаты моделей при этих двух подходах. И, наверное, более логичные результаты, мы получаем именно при использовании парзеновских окон, так как области принятия решений становятся ограниченными, как и должно быть в большинстве задач классификации.
Однако, у рассмотренного подхода есть один существенный недостаток. Нам нужно как то выбирать параметр h для каждой конкретной задачи. Сделать это можно двумя способами. В первом поступить также, как мы делали в задаче k ближайших соседей, используя метод leave-one-out (LOO):
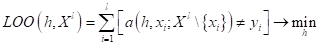
То есть, поочередно отбрасываем по одному наблюдению из обучающей выборки и оцениваем качество классификации по оставшимся данным при заданном значении параметра h. Затем, меняем h и повторяем эту процедуру. По полученным результатам выбираем h, который приводит к меньшему числу ошибок на обучающей выборке.
Второй вариант – это «скрестить» метод k ближайших соседей с парзеновским окном. Если считать, что ядро отлично от нуля только на интервале [0; 1], то ширину окна h можно выбрать такую, чтобы оно охватывало k ближайших соседей относительно оцениваемого вектора :
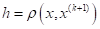
и алгоритм классификации принимает вид:
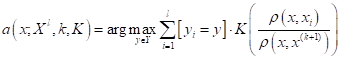
Правда, здесь нам снова придется вернуться к идее упорядочивания наблюдений по возрастанию расстояний, чтобы определить ширину окна для каждого конкретного вектора .
Однако, этот второй подход, как правило, дает лучшие результаты, чем окна с фиксированной шириной. Особенно актуально это для тех задач, в которых плотность (кучность) объектов разных классов разная. Тогда подобрать адекватно фиксированную ширину не всегда удается, а вот адаптивный выбор ширины работает гораздо лучше. Поэтому, на практике чаще используют именно такой второй подход.
Ну а общим недостатком этих методов является необходимость выбора ядра . Обычно, это делается из некоего «здравого смысла» в каждой конкретной задаче и, как правило, выбором одного из часто используемых ядер, приведенных в таблице. Также можно перебрать несколько вариантов ядер и с помощью метода LOO отобрать лучшее.
Метод потенциальных функций
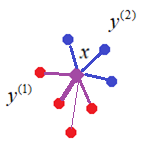
Немного другой взгляд на алгоритмы метрической классификации дает метод потенциальных функций. Здесь рассуждения идут не относительно классифицируемого вектора , а относительно объектов  обучающей выборки:
обучающей выборки:
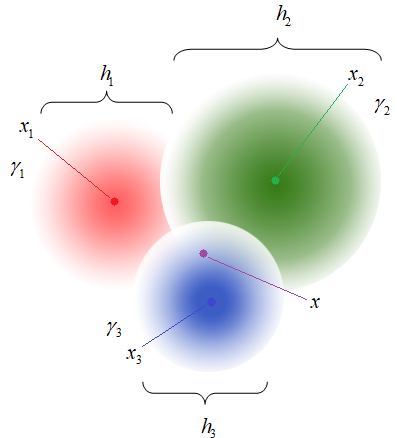
Каждый объект выборки – это точка в n-мерном пространстве признаков, которые как бы «испускают» поля (потенциалы) размерами 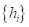 и интенсивностями
и интенсивностями 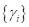 . Все, что нам остается, это в точке определить, какой потенциал наибольший и, соответственно, к тому классу и отнести вектор .
. Все, что нам остается, это в точке определить, какой потенциал наибольший и, соответственно, к тому классу и отнести вектор .
Математически этот алгоритм можно записать, следующим образом:
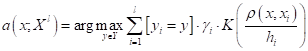
где 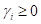 — веса i-х объектов (интенсивности);
— веса i-х объектов (интенсивности); 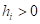 — мера ширины распределения значений ядра (ядро может быть неограниченным по r).
— мера ширины распределения значений ядра (ядро может быть неограниченным по r).
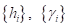
Недостатком и в то же время преимуществом такого подхода является большое число настраиваемых параметров . В самом простом случае их можно считать равными и выбрать некоторые значения h и γ. Либо, если у нас есть некоторые «знания» о свойствах объектов выборки, то всегда можно тонко настроить эти параметры для каждой группы объектов.
Метод потенциальных функций при бинарной классификации
Интересную интерпретацию метода потенциальных функций можно сделать для бинарной классификации, когда у нас всего два класса с метками:
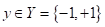
В этом случае, у нас в точке наибольшим может оказаться суммарный потенциал полей или 1-го или 2-го класса:
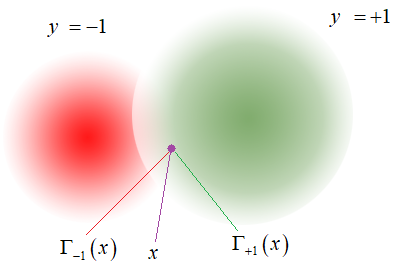
Здесь 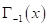 — суммарный потенциал от объектов класса
— суммарный потенциал от объектов класса  , а
, а 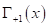 — суммарный потенциал от объектов класса
— суммарный потенциал от объектов класса 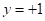 . Тогда алгоритм принятия решения можно записать через знаковую функцию:
. Тогда алгоритм принятия решения можно записать через знаковую функцию:
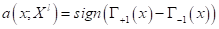
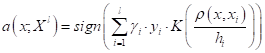
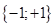
В последней формуле значение разности суммарных потенциалов достигается за счет меток классов . Для всех объектов класса +1 получаем обычную сумму, а для объектов класса -1 – сумму со знаком минус. В итоге имеем суммарную разность потенциалов объектов обоих классов.
Если теперь выделить выражение:
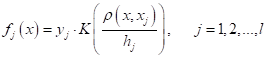
то его можно воспринимать как формирование нового признака для j-го объекта обучающей выборки. Причем, этот признак формируется, как функция от расстояния между классифицируемым вектором и j-м объектом 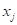 . Далее, автоматически получаем следующий алгоритм классификации:
. Далее, автоматически получаем следующий алгоритм классификации:
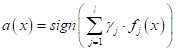
Что вам напоминает эта формула? Да, это общая запись линейного алгоритма бинарной классификации образов. А 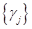 — набор весовых коэффициентов, определяющих ориентацию гиперплоскости в пространстве признаков. В нашем случае число признаков получается равным размеру всей обучающей выборки. Но мы можем их сократить, если, например, подбирать коэффициенты градиентным (или псевдогралиентным) алгоритмом с L1-регуляризацией. Тогда незначимые объекты обучающей выборки просто занулятся и останется некоторое количество ненулевых , которые и будут определять размерность признакового пространства.
— набор весовых коэффициентов, определяющих ориентацию гиперплоскости в пространстве признаков. В нашем случае число признаков получается равным размеру всей обучающей выборки. Но мы можем их сократить, если, например, подбирать коэффициенты градиентным (или псевдогралиентным) алгоритмом с L1-регуляризацией. Тогда незначимые объекты обучающей выборки просто занулятся и останется некоторое количество ненулевых , которые и будут определять размерность признакового пространства.
Этот пример показывает, что мы можем создавать новые признаки для объектов обучающей выборки, используя расстояния до них. Для ряда задач, где мы можем использовать метрическое пространство, это очень полезный прием для расширения признакового пространства.