numpy.linalg.lstsq#
Return the least-squares solution to a linear matrix equation.
Computes the vector x that approximately solves the equation a @ x = b . The equation may be under-, well-, or over-determined (i.e., the number of linearly independent rows of a can be less than, equal to, or greater than its number of linearly independent columns). If a is square and of full rank, then x (but for round-off error) is the “exact” solution of the equation. Else, x minimizes the Euclidean 2-norm \(||b — ax||\) . If there are multiple minimizing solutions, the one with the smallest 2-norm \(||x||\) is returned.
Parameters : a (M, N) array_like
b array_like
Ordinate or “dependent variable” values. If b is two-dimensional, the least-squares solution is calculated for each of the K columns of b.
rcond float, optional
Cut-off ratio for small singular values of a. For the purposes of rank determination, singular values are treated as zero if they are smaller than rcond times the largest singular value of a.
Changed in version 1.14.0: If not set, a FutureWarning is given. The previous default of -1 will use the machine precision as rcond parameter, the new default will use the machine precision times max(M, N). To silence the warning and use the new default, use rcond=None , to keep using the old behavior, use rcond=-1 .
Least-squares solution. If b is two-dimensional, the solutions are in the K columns of x.
residuals ndarray
Sums of squared residuals: Squared Euclidean 2-norm for each column in b — a @ x . If the rank of a is < N or M b is 1-dimensional, this is a (1,) shape array. Otherwise the shape is (K,).
s (min(M, N),) ndarray
If computation does not converge.
Similar function in SciPy.
If b is a matrix, then all array results are returned as matrices.
Fit a line, y = mx + c , through some noisy data-points:
>>> x = np.array([0, 1, 2, 3]) >>> y = np.array([-1, 0.2, 0.9, 2.1])
By examining the coefficients, we see that the line should have a gradient of roughly 1 and cut the y-axis at, more or less, -1.
We can rewrite the line equation as y = Ap , where A = [[x 1]] and p = [[m], [c]] . Now use lstsq to solve for p:
>>> A = np.vstack([x, np.ones(len(x))]).T >>> A array([[ 0., 1.], [ 1., 1.], [ 2., 1.], [ 3., 1.]])
>>> m, c = np.linalg.lstsq(A, y, rcond=None)[0] >>> m, c (1.0 -0.95) # may vary
Plot the data along with the fitted line:
>>> import matplotlib.pyplot as plt >>> _ = plt.plot(x, y, 'o', label='Original data', markersize=10) >>> _ = plt.plot(x, m*x + c, 'r', label='Fitted line') >>> _ = plt.legend() >>> plt.show()
Метод наименьших квадратов
На этом занятии мы с вами рассмотрим алгоритм, который носит название метод наименьших квадратов. Для начала немного теории. Чтобы ее хорошо понимать нужны базовые знания по теории вероятностей, в частности понимание ПРВ, а также знать, что такое производная и как она вычисляется. Остальное я сейчас расскажу.
На практике встречаются задачи, когда производились измерения некоторой функциональной зависимости, но из-за погрешностей приборов, или неточных сведений или еще по какой-либо причине, измерения немного отстоят от истинных значений функции и образуют некий разброс:
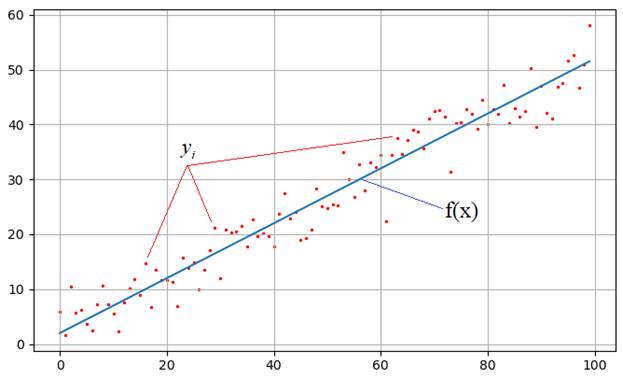
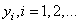
Наша задача: зная характер функциональной зависимости, подобрать ее параметры так, чтобы она наилучшим образом описывала экспериментальные данные Например, на рисунке явно прослеживается линейная зависимость. Мы это можем определить либо чисто визуально, либо заранее знать о характере функции. Но, в любом случае предполагается, что ее общий вид нам известен. Так вот, для линейной функции достаточно определить два параметра k и b:
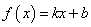
чтобы построить аппроксимацию (приближение) линейного графика к экспериментальным зависимостям. Конечно, вид функциональной зависимости может быть и другим, например, квадратической (парабола), синусоидальной, или даже определяться суммой известных функций, но для простоты понимания, мы для начала рассмотрим именно линейный график с двумя неизвестными коэффициентами.
Итак, будем считать, что на первый вопрос о характере функциональной зависимости экспериментальных данных ответ дан. Следующий вопрос: как измерить качество аппроксимации измерений функцией 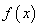 ? Вообще, таких критериев можно придумать множество, например:
? Вообще, таких критериев можно придумать множество, например:
— сумма квадратов ошибок отклонений:
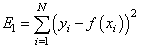
— сумма модулей ошибок отклонений:
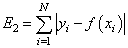
— минимум максимальной по модулю ошибки:
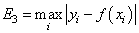
и так далее. Каждый из критериев может приводить к своему алгоритму обработки экспериментальных значений. Так вот, в методе наименьших квадратов используется минимум суммы квадратов ошибок. И этому есть математическое обоснование. Часто результаты реальных измерений имеют стандартное (гауссовское) отклонение относительно измеряемого параметра:
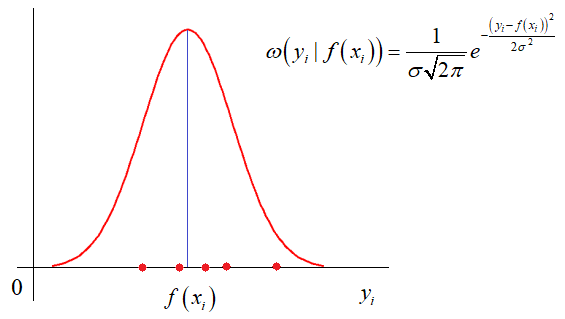
Здесь σ – стандартное отклонение (СКО) наблюдаемых значений от функции . Отсюда хорошо видно, что чем ближе измерение к истинному значению параметра, тем больше значение функции плотности распределения условной вероятности. И, так для всех точек измерения. Учитывая, что они выполняются независимо друг от друга, то можно записать следующее функциональное выражение:
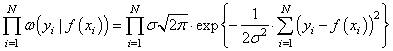
Получается, что лучшее описание экспериментальных данных с помощью функции должно проходить по точкам, в которых достигается максимум этого выражения. Очевидно, что при поиске максимума можно не учитывать множитель 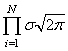 , а экспонента будет принимать максимальное значение при минимуме ее отрицательной степени:
, а экспонента будет принимать максимальное значение при минимуме ее отрицательной степени:
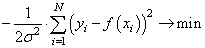
Здесь также множитель можно не учитывать, получаем критерий качества минимум суммы квадрата ошибок:
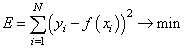
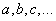
Как мы помним, наша цель – подобрать параметры функции
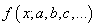
которые как раз и обеспечивают минимум этого критерия, то есть, величина E зависит от этих подбираемых величин:
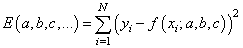
И ее можно рассматривать как квадратическую функцию от аргументов Из школьного курса математики мы знаем как находится точка экстремума функции – это точка, в которой производная равна нулю:
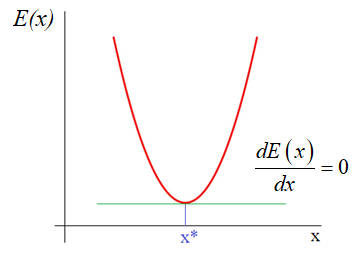
Здесь все также, нужно взять частные производные по каждому параметру и приравнять результат нулю, получим систему линейных уравнений:
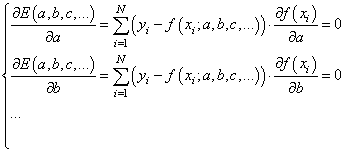
Чтобы наполнить конкретикой эту систему, нам нужно вернуться к исходному примеру с линейной функцией:
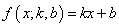
Эта функция зависит от двух параметров: k и b с частными производными:
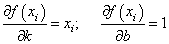
Подставляем все в систему, имеем:
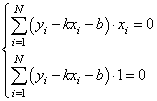
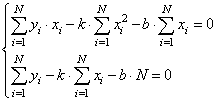
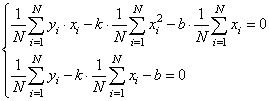
Смотрите, что в итоге получилось. Формулы с суммами представляют собой первые и вторые начальные моменты, а также один смешанный момент:
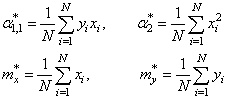
Здесь * означает экспериментальные моменты. В этих обозначениях, получаем:
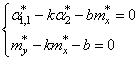
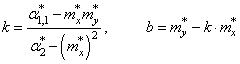
Все, мы получили оценки параметров k и b для линейной аппроксимации экспериментальных данных по методу наименьших квадратов. По аналогии можно вычислять параметры для других функциональных зависимостей, например, квадратической:
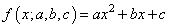
Здесь будет уже три свободных параметра и три уравнения, решая которые будем получать лучшую аппроксимацию по критерию минимума суммарной квадратической ошибки отклонений.
Реализация на Python
В заключение этого занятия реализуем метод наименьших квадратов на Python. Для этого нам понадобятся две довольно популярные библиотеки numpy и matplotlib. Если они у вас не установлены, то делается это просто – через команды:
После этого, мы можем их импортировать и использовать в программе:
import numpy as np import matplotlib.pyplot as plt
Первая довольно эффективная для выполнения различных математических операций, включая векторные и матричные. Вторая служит для построения графиков.
Итак, вначале определим необходимые начальные величины:
N = 100 # число экспериментов sigma = 3 # стандартное отклонение наблюдаемых значений k = 0.5 # теоретическое значение параметра k b = 2 # теоретическое значение параметра b
Формируем вспомогательный вектор
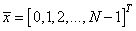
с помощью метода array, который возвращает объект-вектор на основе итерируемой функции range:
Затем, вычисляем значения теоретической функции:
f = np.array([k*z+b for z in range(N)])
и добавляем к ней случайные отклонения для моделирования результатов наблюдений:
y = f + np.random.normal(0, sigma, N)
Если сейчас отобразить наборы точек y, то они будут выглядеть следующим образом:
plt.scatter(x, y, s=2, c='red') plt.grid(True) plt.show()
Теперь у нас все есть для вычисления коэффициентов k и b по экспериментальным данным:
# вычисляем коэффициенты mx = x.sum()/N my = y.sum()/N a2 = np.dot(x.T, x)/N a11 = np.dot(x.T, y)/N kk = (a11 - mx*my)/(a2 - mx**2) bb = my - kk*mx
Здесь выражение x.T*x – это произведение:
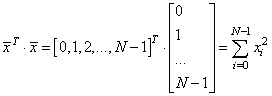
Далее, построим точки полученной аппроксимации:
ff = np.array([kk*z+bb for z in range(N)])
и отобразим оба линейных графика:
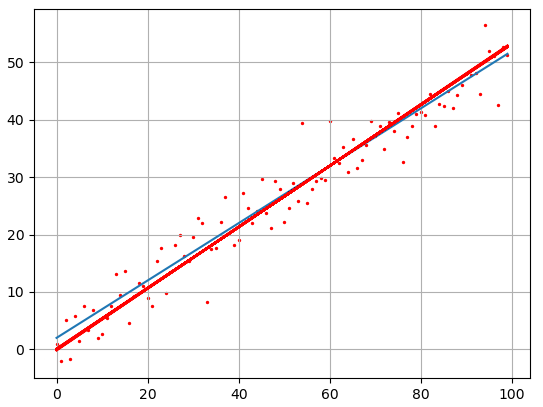
Как видите результат аппроксимации довольно близок начальному, теоретическому графику. Вот так работает метод наименьших квадратов.
Видео по теме

#1: Метод наименьших квадратов

#2: Метод градиентного спуска

#3: Метод градиентного спуска для двух параметров

#4: Марковские процессы в дискретном времени

#5: Фильтр Калмана дискретного времени

#6: Фильтр Калмана для авторегрессионого уравнения

#7: Векторный фильтр Калмана


#9: Байесовское построение оценок, метод максимального правдоподобия

#10: Байесовский классификатор, отношение правдоподобия
© 2023 Частичное или полное копирование информации с данного сайта для распространения на других ресурсах, в том числе и бумажных, строго запрещено. Все тексты и изображения являются собственностью сайта
Наименьшие квадраты в NumPy

В этой статье будет рассказано, как вычислить AX = B методом наименьших квадратов в Python.
Метод наименьших квадратов NumPy с функцией numpy.linalg.lstsq() в Python
Уравнение AX = B известно как линейное матричное уравнение. Функция numpy.linalg.lstsq() может использоваться для решения линейного матричного уравнения AX = B методом наименьших квадратов в Python. На самом деле это довольно просто. Эта функция принимает матрицы и возвращает решение линейного матричного уравнения методом наименьших квадратов в виде другой матрицы. См. Следующий пример кода.
import numpy as np A=[[1,1,1,1],[1,1,1,1],[1,1,1,1],[1,1,1,1],[1,1,0,0]] B=[1,1,1,1,1] X=np.linalg.lstsq(A, B, rcond = -1) print (X[0]) [5.00000000e-01 5.00000000e-01 1.09109979e-16 1.64621130e-16] В приведенном выше коде мы вычислили решение линейного матричного уравнения AX = B с помощью функции np.linalg.lstsq() в Python. Этот метод становится немного сложнее, когда мы начинаем добавлять веса к нашим матрицам. Есть два основных метода, которые мы можем использовать для решения этой проблемы.
Первое решение включает использование индексации массива со спецификатором np.newaxis для добавления нового измерения к весам. Это проиллюстрировано в приведенном ниже примере кодирования.
import numpy as np A=np.array([[1,1,1,1],[1,1,1,1],[1,1,1,1],[1,1,1,1],[1,1,0,0]]) B = np.array([1,1,1,1,1]) W = np.array([1,2,3,4,5]) Aw = A * np.sqrt(W[:,np.newaxis]) Bw = B * np.sqrt(W) X = np.linalg.lstsq(Aw, Bw, rcond = -1) print(X[0]) [ 5.00000000e-01 5.00000000e-01 -4.40221936e-17 1.14889576e-17] В приведенном выше коде мы вычислили решение линейного матричного уравнения AX = B вместе с весами W с помощью функций np.newaxis и np.linalg.lstsq() в Python. Этот метод работает нормально, но его не очень легко понять и прочитать.