scipy.integrate.quadrature#
Compute a definite integral using fixed-tolerance Gaussian quadrature.
Integrate func from a to b using Gaussian quadrature with absolute tolerance tol.
Parameters : func function
A Python function or method to integrate.
Lower limit of integration.
Upper limit of integration.
args tuple, optional
Extra arguments to pass to function.
tol, rtol float, optional
Iteration stops when error between last two iterates is less than tol OR the relative change is less than rtol.
maxiter int, optional
Maximum order of Gaussian quadrature.
vec_func bool, optional
True or False if func handles arrays as arguments (is a “vector” function). Default is True.
miniter int, optional
Minimum order of Gaussian quadrature.
Returns : val float
Gaussian quadrature approximation (within tolerance) to integral.
Difference between last two estimates of the integral.
adaptive Romberg quadrature
fixed-order Gaussian quadrature
adaptive quadrature using QUADPACK
integrator for sampled data
integrator for sampled data
cumulative integration for sampled data
>>> from scipy import integrate >>> import numpy as np >>> f = lambda x: x**8 >>> integrate.quadrature(f, 0.0, 1.0) (0.11111111111111106, 4.163336342344337e-17) >>> print(1/9.0) # analytical result 0.1111111111111111
>>> integrate.quadrature(np.cos, 0.0, np.pi/2) (0.9999999999999536, 3.9611425250996035e-11) >>> np.sin(np.pi/2)-np.sin(0) # analytical result 1.0
Метод наименьших квадратов
На этом занятии мы с вами рассмотрим алгоритм, который носит название метод наименьших квадратов. Для начала немного теории. Чтобы ее хорошо понимать нужны базовые знания по теории вероятностей, в частности понимание ПРВ, а также знать, что такое производная и как она вычисляется. Остальное я сейчас расскажу.
На практике встречаются задачи, когда производились измерения некоторой функциональной зависимости, но из-за погрешностей приборов, или неточных сведений или еще по какой-либо причине, измерения немного отстоят от истинных значений функции и образуют некий разброс:
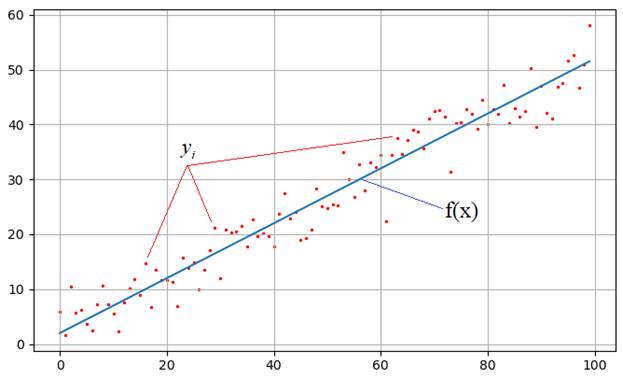
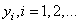
Наша задача: зная характер функциональной зависимости, подобрать ее параметры так, чтобы она наилучшим образом описывала экспериментальные данные Например, на рисунке явно прослеживается линейная зависимость. Мы это можем определить либо чисто визуально, либо заранее знать о характере функции. Но, в любом случае предполагается, что ее общий вид нам известен. Так вот, для линейной функции достаточно определить два параметра k и b:
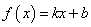
чтобы построить аппроксимацию (приближение) линейного графика к экспериментальным зависимостям. Конечно, вид функциональной зависимости может быть и другим, например, квадратической (парабола), синусоидальной, или даже определяться суммой известных функций, но для простоты понимания, мы для начала рассмотрим именно линейный график с двумя неизвестными коэффициентами.
Итак, будем считать, что на первый вопрос о характере функциональной зависимости экспериментальных данных ответ дан. Следующий вопрос: как измерить качество аппроксимации измерений функцией  ? Вообще, таких критериев можно придумать множество, например:
? Вообще, таких критериев можно придумать множество, например:
— сумма квадратов ошибок отклонений:
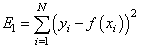
— сумма модулей ошибок отклонений:
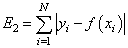
— минимум максимальной по модулю ошибки:
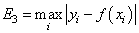
и так далее. Каждый из критериев может приводить к своему алгоритму обработки экспериментальных значений. Так вот, в методе наименьших квадратов используется минимум суммы квадратов ошибок. И этому есть математическое обоснование. Часто результаты реальных измерений имеют стандартное (гауссовское) отклонение относительно измеряемого параметра:
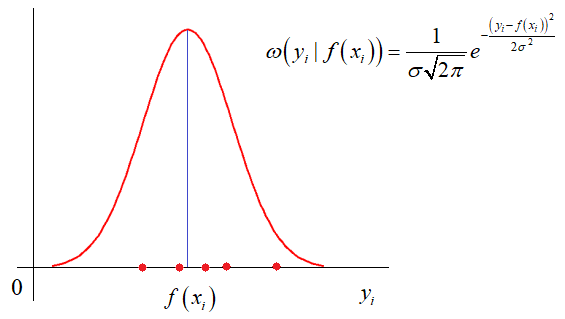
Здесь σ – стандартное отклонение (СКО) наблюдаемых значений от функции . Отсюда хорошо видно, что чем ближе измерение к истинному значению параметра, тем больше значение функции плотности распределения условной вероятности. И, так для всех точек измерения. Учитывая, что они выполняются независимо друг от друга, то можно записать следующее функциональное выражение:
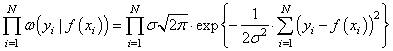
Получается, что лучшее описание экспериментальных данных с помощью функции должно проходить по точкам, в которых достигается максимум этого выражения. Очевидно, что при поиске максимума можно не учитывать множитель 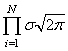 , а экспонента будет принимать максимальное значение при минимуме ее отрицательной степени:
, а экспонента будет принимать максимальное значение при минимуме ее отрицательной степени:
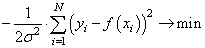
Здесь также множитель можно не учитывать, получаем критерий качества минимум суммы квадрата ошибок:
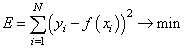
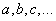
Как мы помним, наша цель – подобрать параметры функции
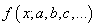
которые как раз и обеспечивают минимум этого критерия, то есть, величина E зависит от этих подбираемых величин:
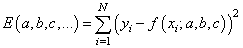
И ее можно рассматривать как квадратическую функцию от аргументов Из школьного курса математики мы знаем как находится точка экстремума функции – это точка, в которой производная равна нулю:
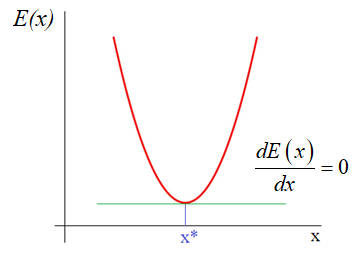
Здесь все также, нужно взять частные производные по каждому параметру и приравнять результат нулю, получим систему линейных уравнений:
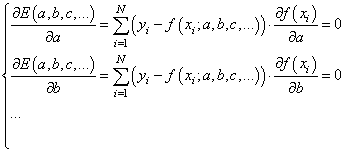
Чтобы наполнить конкретикой эту систему, нам нужно вернуться к исходному примеру с линейной функцией:
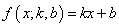
Эта функция зависит от двух параметров: k и b с частными производными:
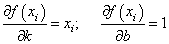
Подставляем все в систему, имеем:
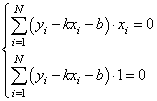
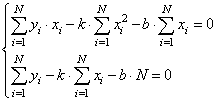
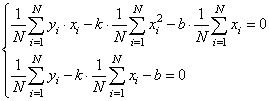
Смотрите, что в итоге получилось. Формулы с суммами представляют собой первые и вторые начальные моменты, а также один смешанный момент:
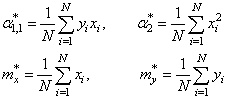
Здесь * означает экспериментальные моменты. В этих обозначениях, получаем:
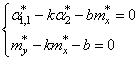
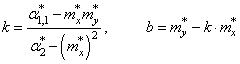
Все, мы получили оценки параметров k и b для линейной аппроксимации экспериментальных данных по методу наименьших квадратов. По аналогии можно вычислять параметры для других функциональных зависимостей, например, квадратической:
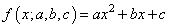
Здесь будет уже три свободных параметра и три уравнения, решая которые будем получать лучшую аппроксимацию по критерию минимума суммарной квадратической ошибки отклонений.
Реализация на Python
В заключение этого занятия реализуем метод наименьших квадратов на Python. Для этого нам понадобятся две довольно популярные библиотеки numpy и matplotlib. Если они у вас не установлены, то делается это просто – через команды:
После этого, мы можем их импортировать и использовать в программе:
import numpy as np import matplotlib.pyplot as plt
Первая довольно эффективная для выполнения различных математических операций, включая векторные и матричные. Вторая служит для построения графиков.
Итак, вначале определим необходимые начальные величины:
N = 100 # число экспериментов sigma = 3 # стандартное отклонение наблюдаемых значений k = 0.5 # теоретическое значение параметра k b = 2 # теоретическое значение параметра b
Формируем вспомогательный вектор
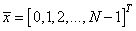
с помощью метода array, который возвращает объект-вектор на основе итерируемой функции range:
Затем, вычисляем значения теоретической функции:
f = np.array([k*z+b for z in range(N)])
и добавляем к ней случайные отклонения для моделирования результатов наблюдений:
y = f + np.random.normal(0, sigma, N)
Если сейчас отобразить наборы точек y, то они будут выглядеть следующим образом:
plt.scatter(x, y, s=2, c='red') plt.grid(True) plt.show()
Теперь у нас все есть для вычисления коэффициентов k и b по экспериментальным данным:
# вычисляем коэффициенты mx = x.sum()/N my = y.sum()/N a2 = np.dot(x.T, x)/N a11 = np.dot(x.T, y)/N kk = (a11 - mx*my)/(a2 - mx**2) bb = my - kk*mx
Здесь выражение x.T*x – это произведение:
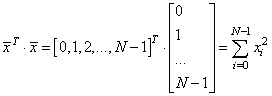
Далее, построим точки полученной аппроксимации:
ff = np.array([kk*z+bb for z in range(N)])
и отобразим оба линейных графика:
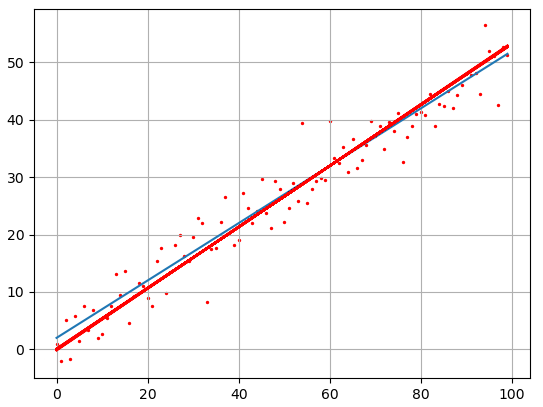
Как видите результат аппроксимации довольно близок начальному, теоретическому графику. Вот так работает метод наименьших квадратов.
Видео по теме

#1: Метод наименьших квадратов

#2: Метод градиентного спуска

#3: Метод градиентного спуска для двух параметров

#4: Марковские процессы в дискретном времени

#5: Фильтр Калмана дискретного времени

#6: Фильтр Калмана для авторегрессионого уравнения

#7: Векторный фильтр Калмана


#9: Байесовское построение оценок, метод максимального правдоподобия

#10: Байесовский классификатор, отношение правдоподобия
© 2023 Частичное или полное копирование информации с данного сайта для распространения на других ресурсах, в том числе и бумажных, строго запрещено. Все тексты и изображения являются собственностью сайта
Метод наименьших квадратов (МНК) в две строчки на Python, scipy, matplotlib
Построение гипотез по методу наименьших квадратов — это, пожалуй, простейшая и наиболее распространённая задача машинного обучения и построения прогнозов.
Здесь я приведу полезные и наиболее употребительные сниппеты для Python. Однако, я хотел бы сделать эту заметку чуть-чуть более полезной, что просто сниппет. Предлагаю решить практическую задачу.
Постановка задачи
Я написал расширение для браузера Chrome, позволяющее слушать радио. Я слежу за статистикой установок и имею данные по количеству пользователей. Накопив определённую статистику, я хочу получить ответы на два простых вопроса:
- Через сколько дней количество пользователей достигнет 1000?
- Сколько пользователей будет через 60 дней?
Чтобы решить эту задачу нам нужна модель. Давайте исходить из того, что зависимость числа пользователей от дня — полиномиальная.
Решение
#!/usr/bin/python # coding: utf8 import scipy as sp import matplotlib.pyplot as plt from scipy.optimize import fsolve # читаем данные data = sp.genfromtxt("data.tsv", delimiter="\t") #print(data[:10]) # часть данных можно напечатать, чтобы убедиться, что всё в порядке # берём срезы: первую и вторую колонку нашего файла x = data[:,0] y = data[:,1] # настраиваем детали отрисовки графиков plt.figure(figsize=(8, 6)) plt.title("Installations") plt.xlabel("Days") plt.ylabel("Installations") #plt.xticks([. ], [. ]) # можно назначить свои тики plt.autoscale(tight=True) # рисуем исходные точки plt.scatter(x, y) legend = [] # аргументы для построения графиков моделей: исходный интервал + 60 дней fx = sp.linspace(x[0], x[-1] + 60, 1000) for d in range(1, 6): # получаем параметры модели для полинома степени d fp, residuals, rank, sv, rcond = sp.polyfit(x, y, d, full=True) #print("Параметры модели: %s" % fp1) # функция-полином, если её напечатать, то увидите математическое выражение f = sp.poly1d(fp) #print(f) # рисуем график модельной функции plt.plot(fx, f(fx), linewidth=2) legend.append("d=%i" % f.order) f2 = f - 1000 # из полинома можно вычитать t = fsolve(f2, x[-1]) # ищем решение уравнения f2(x)=0, отплясывая от точки x[-1] print "Полином %d-й степени:" % f.order print "- Мы достигнем 1000 установок через %d дней" % (t[0] - x[-1]) print "- Через 60 дней у нас будет %d установок" % f(x[-1] + 60) plt.legend(legend, loc="upper left") plt.grid() plt.savefig('data.png', dpi=50) plt.show() Полином 1-й степени: - Мы достигнем 1000 установок через 462 дней - Через 60 дней у нас будет 561 установок Полином 2-й степени: - Мы достигнем 1000 установок через 368 дней - Через 60 дней у нас будет 579 установок Полином 3-й степени: - Мы достигнем 1000 установок через 166 дней - Через 60 дней у нас будет 660 установок Полином 4-й степени: - Мы достигнем 1000 установок через 57 дней - Через 60 дней у нас будет 1021 установок Полином 5-й степени: - Мы достигнем 1000 установок через 28 дней - Через 60 дней у нас будет 1692 установок Мы так же можем взглянуть на графики, построенные с помощью matplotlib.pyplot :
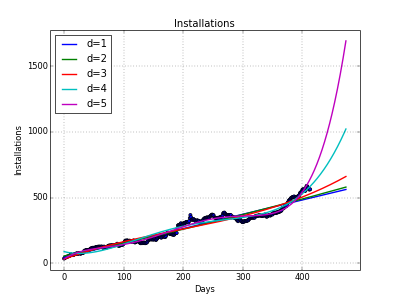
Здесь хорошо видны примеры и переученности (overfitting) и недоученности (underfitting). Видно, что наиболее реалистичны кривые первой и второй степени. Результаты же, полученные на кривых четвёртой и пятой степеней, скорее всего, обманчивы.