- Scatterplot Matrix in Python
- Scatter matrix with Plotly Express¶
- Styled Scatter Matrix with Plotly Express¶
- Scatter matrix (splom) with go.Splom¶
- Splom of the Iris data set¶
- Как создать матрицу рассеяния в Pandas (с примерами)
- Пример 1: Базовая матрица рассеяния
- Пример 2: Матрица рассеяния для определенных столбцов
- Пример 3: Матрица рассеивания с пользовательскими цветами и ячейками
- Пример 4: Матрица рассеяния с графиком KDE
- Дополнительные ресурсы
- Диаграмма рассеивания Matplotlib — Учебное пособие и примеры
- Импортировать данные
- Постройте диаграмму рассеивания в Matplotlib
- Построение графиков множественного разброса в Matplotlib
- Построение трехмерной диаграммы рассеяния в Matplotlib
- Настройка точечной диаграммы в Matplotlib
- Вывод
Scatterplot Matrix in Python
How to make scatterplot matrices or sploms natively in Python with Plotly.
This page in another language
Plotly is a free and open-source graphing library for Python. We recommend you read our Getting Started guide for the latest installation or upgrade instructions, then move on to our Plotly Fundamentals tutorials or dive straight in to some Basic Charts tutorials.
Scatter matrix with Plotly Express¶
A scatterplot matrix is a matrix associated to n numerical arrays (data variables), $X_1,X_2,…,X_n$ , of the same length. The cell (i,j) of such a matrix displays the scatter plot of the variable Xi versus Xj.
Here we show the Plotly Express function px.scatter_matrix to plot the scatter matrix for the columns of the dataframe. By default, all columns are considered.
import plotly.express as px df = px.data.iris() fig = px.scatter_matrix(df) fig.show()
Specify the columns to be represented with the dimensions argument, and set colors using a column of the dataframe:
import plotly.express as px df = px.data.iris() fig = px.scatter_matrix(df, dimensions=["sepal_length", "sepal_width", "petal_length", "petal_width"], color="species") fig.show()
Styled Scatter Matrix with Plotly Express¶
The scatter matrix plot can be configured thanks to the parameters of px.scatter_matrix , but also thanks to fig.update_traces for fine tuning (see the next section to learn more about the options).
import plotly.express as px df = px.data.iris() fig = px.scatter_matrix(df, dimensions=["sepal_length", "sepal_width", "petal_length", "petal_width"], color="species", symbol="species", title="Scatter matrix of iris data set", labels=col:col.replace('_', ' ') for col in df.columns>) # remove underscore fig.update_traces(diagonal_visible=False) fig.show()
Scatter matrix (splom) with go.Splom¶
If Plotly Express does not provide a good starting point, it is possible to use the more generic go.Splom class from plotly.graph_objects . All its parameters are documented in the reference page https://plotly.com/python/reference/splom/.
The Plotly splom trace implementation for the scatterplot matrix does not require to set $x=Xi$ , and $y=Xj$, for each scatter plot. All arrays, $X_1,X_2,…,X_n$ , are passed once, through a list of dicts called dimensions, i.e. each array/variable represents a dimension.
A trace of type splom is defined as follows:
trace=go.Splom(dimensions=[dict(label='string-1', values=X1), dict(label='string-2', values=X2), . . . dict(label='string-n', values=Xn)], . )The label in each dimension is assigned to the axes titles of the corresponding matrix cell.
Splom of the Iris data set¶
import plotly.graph_objects as go import pandas as pd df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/iris-data.csv') # The Iris dataset contains four data variables, sepal length, sepal width, petal length, # petal width, for 150 iris flowers. The flowers are labeled as `Iris-setosa`, # `Iris-versicolor`, `Iris-virginica`. # Define indices corresponding to flower categories, using pandas label encoding index_vals = df['class'].astype('category').cat.codes fig = go.Figure(data=go.Splom( dimensions=[dict(label='sepal length', values=df['sepal length']), dict(label='sepal width', values=df['sepal width']), dict(label='petal length', values=df['petal length']), dict(label='petal width', values=df['petal width'])], text=df['class'], marker=dict(color=index_vals, showscale=False, # colors encode categorical variables line_color='white', line_width=0.5) )) fig.update_layout( title='Iris Data set', dragmode='select', width=600, height=600, hovermode='closest', ) fig.show()
The scatter plots on the principal diagonal can be removed by setting diagonal_visible=False :
import plotly.graph_objects as go import pandas as pd df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/iris-data.csv') index_vals = df['class'].astype('category').cat.codes fig = go.Figure(data=go.Splom( dimensions=[dict(label='sepal length', values=df['sepal length']), dict(label='sepal width', values=df['sepal width']), dict(label='petal length', values=df['petal length']), dict(label='petal width', values=df['petal width'])], diagonal_visible=False, # remove plots on diagonal text=df['class'], marker=dict(color=index_vals, showscale=False, # colors encode categorical variables line_color='white', line_width=0.5) )) fig.update_layout( title='Iris Data set', width=600, height=600, ) fig.show()
Как создать матрицу рассеяния в Pandas (с примерами)
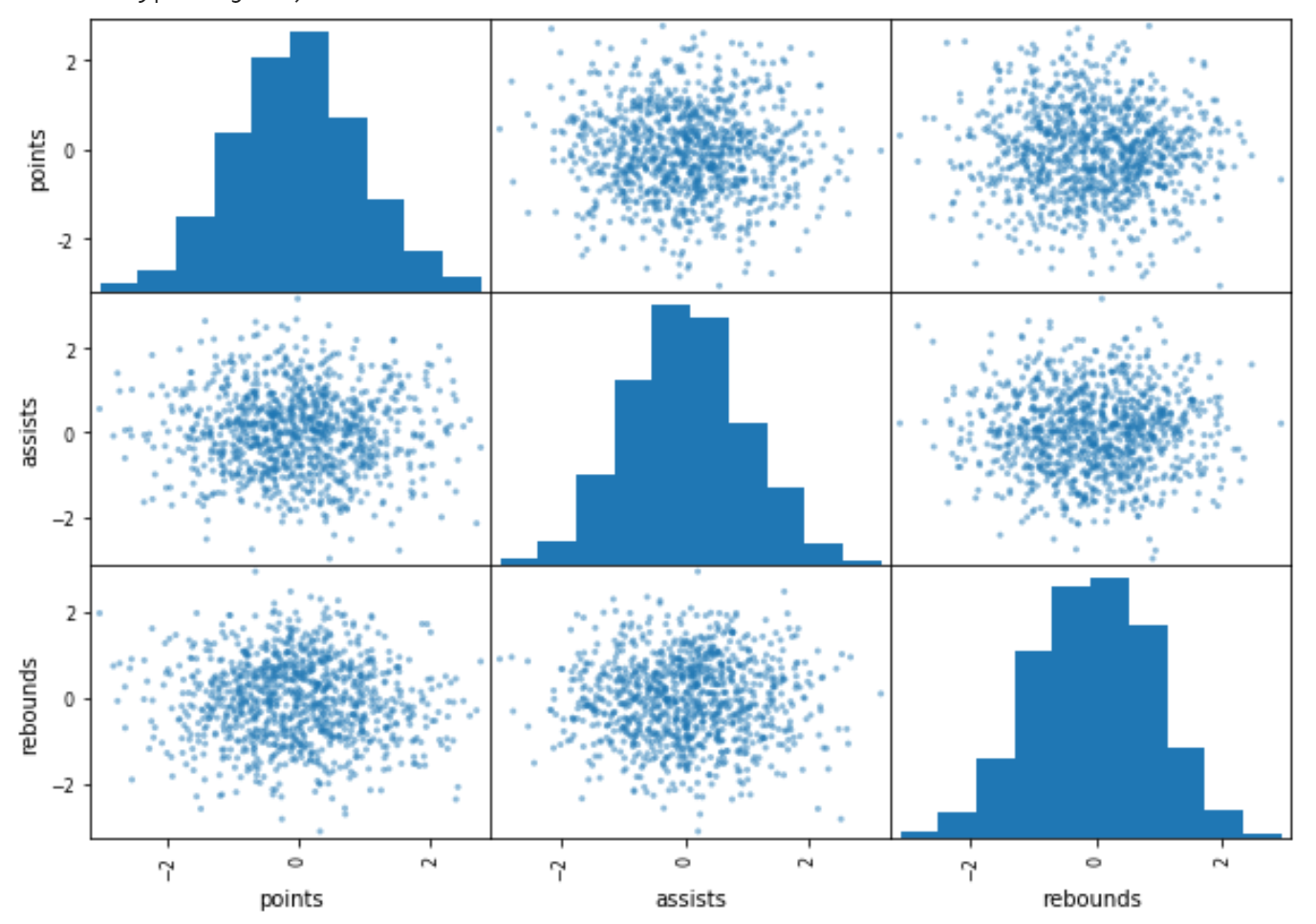
Матрица рассеяния — это именно то, на что это похоже — матрица диаграмм рассеяния.
Этот тип матрицы удобен тем, что позволяет визуализировать взаимосвязь между несколькими переменными в наборе данных одновременно.
Вы можете использовать функцию scatter_matrix() для создания матрицы рассеяния из кадра данных pandas:
pd.plotting.scatter_matrix(df) В следующих примерах показано, как использовать этот синтаксис на практике со следующими пандами DataFrame:
import pandas as pd import numpy as np #make this example reproducible np.random.seed (0) #create DataFrame df = pd.DataFrame() #view first five rows of DataFrame df.head () points assists rebounds 0 1.764052 0.555963 -1.532921 1 0.400157 0.892474 -1.711970 2 0.978738 -0.422315 0.046135 3 2.240893 0.104714 -0.958374 4 1.867558 0.228053 -0.080812 Пример 1: Базовая матрица рассеяния
Следующий код показывает, как создать базовую матрицу рассеяния:
pd.plotting.scatter_matrix(df) 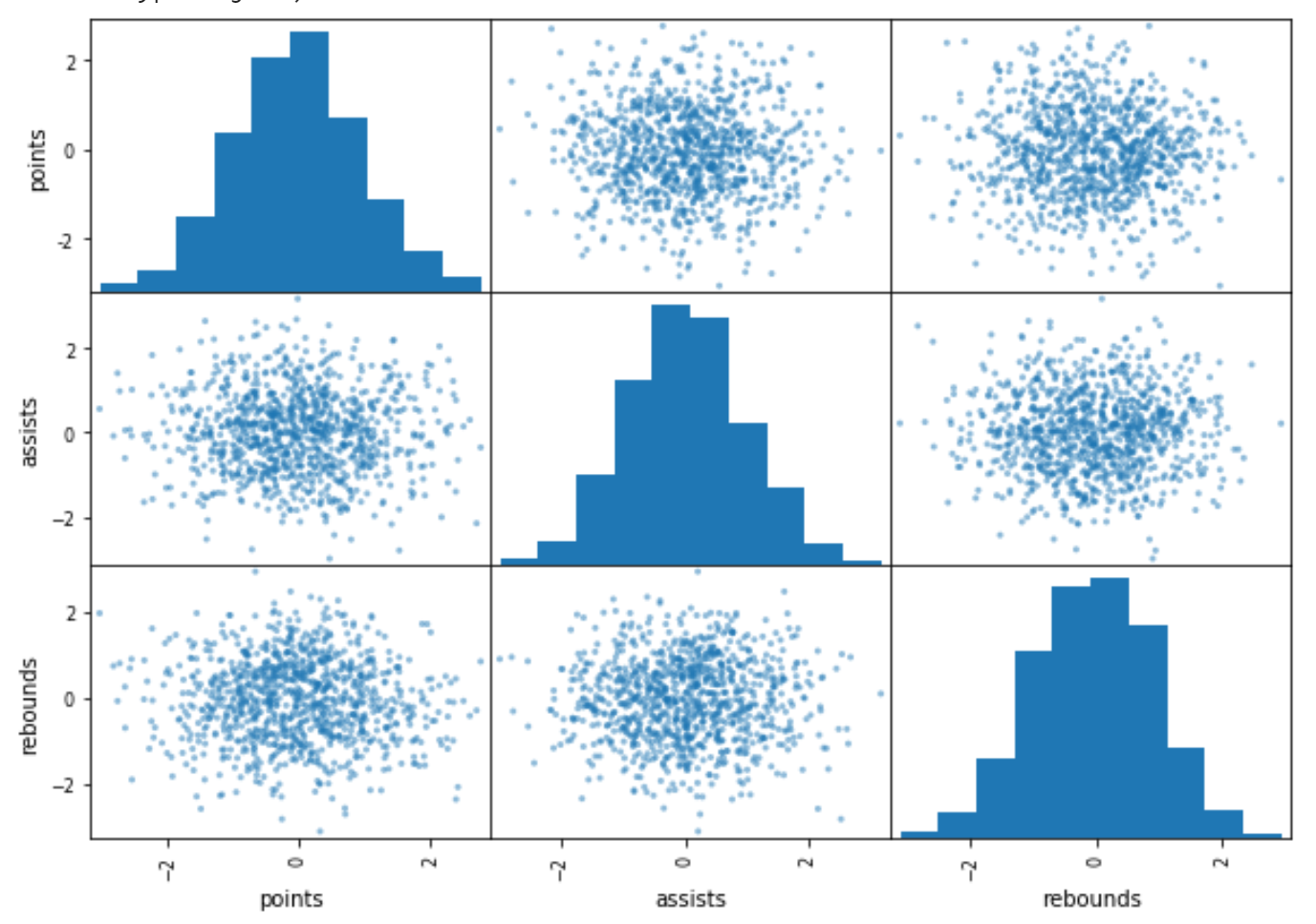
Пример 2: Матрица рассеяния для определенных столбцов
В следующем коде показано, как создать матрицу рассеяния только для первых двух столбцов в DataFrame:
pd.plotting.scatter_matrix(df.iloc [:, 0:2]) 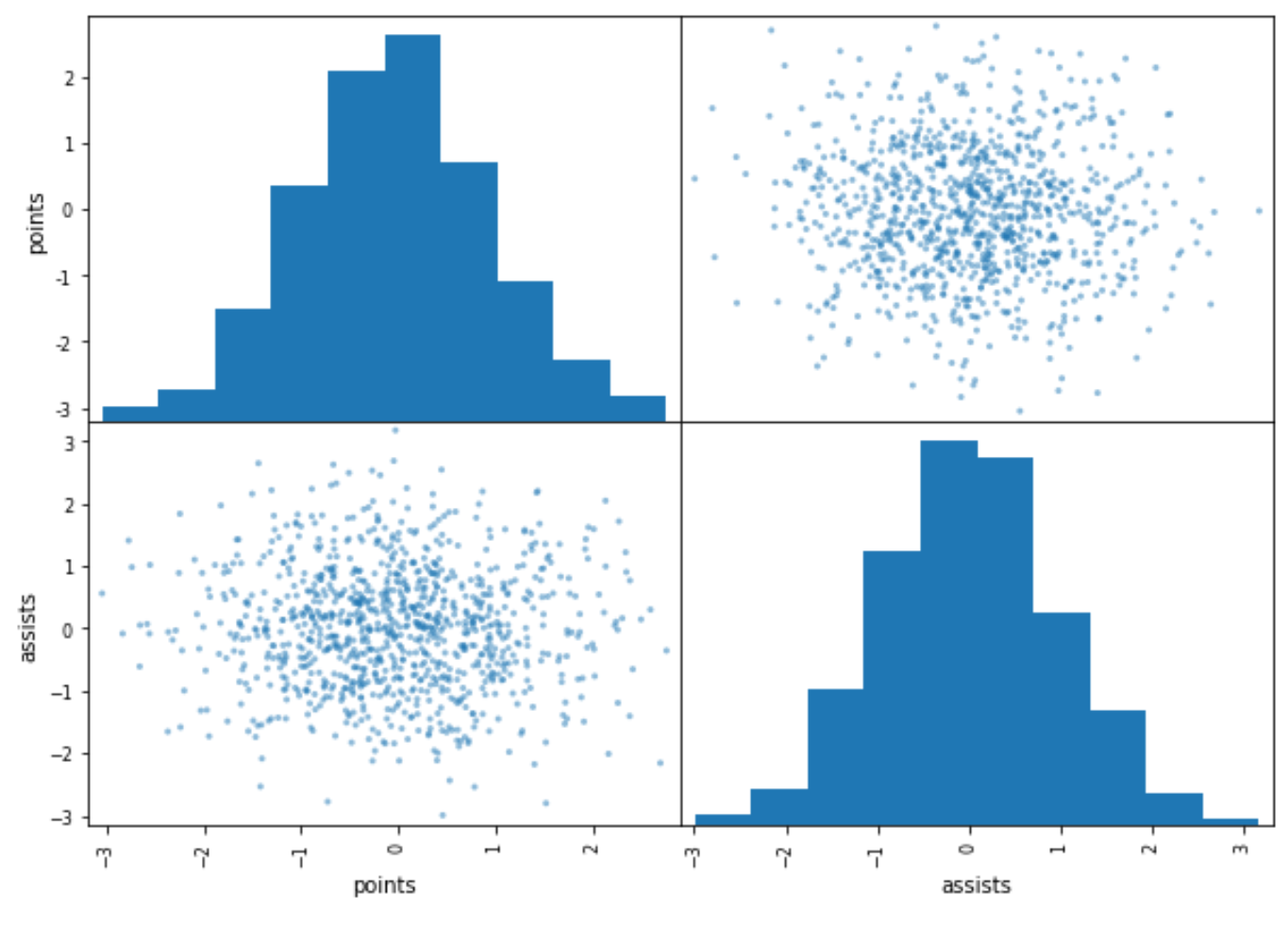
Пример 3: Матрица рассеивания с пользовательскими цветами и ячейками
В следующем коде показано, как создать матрицу рассеяния с пользовательскими цветами и определенным количеством интервалов для гистограмм:
pd.plotting.scatter_matrix(df, color='red', hist_kwds=) 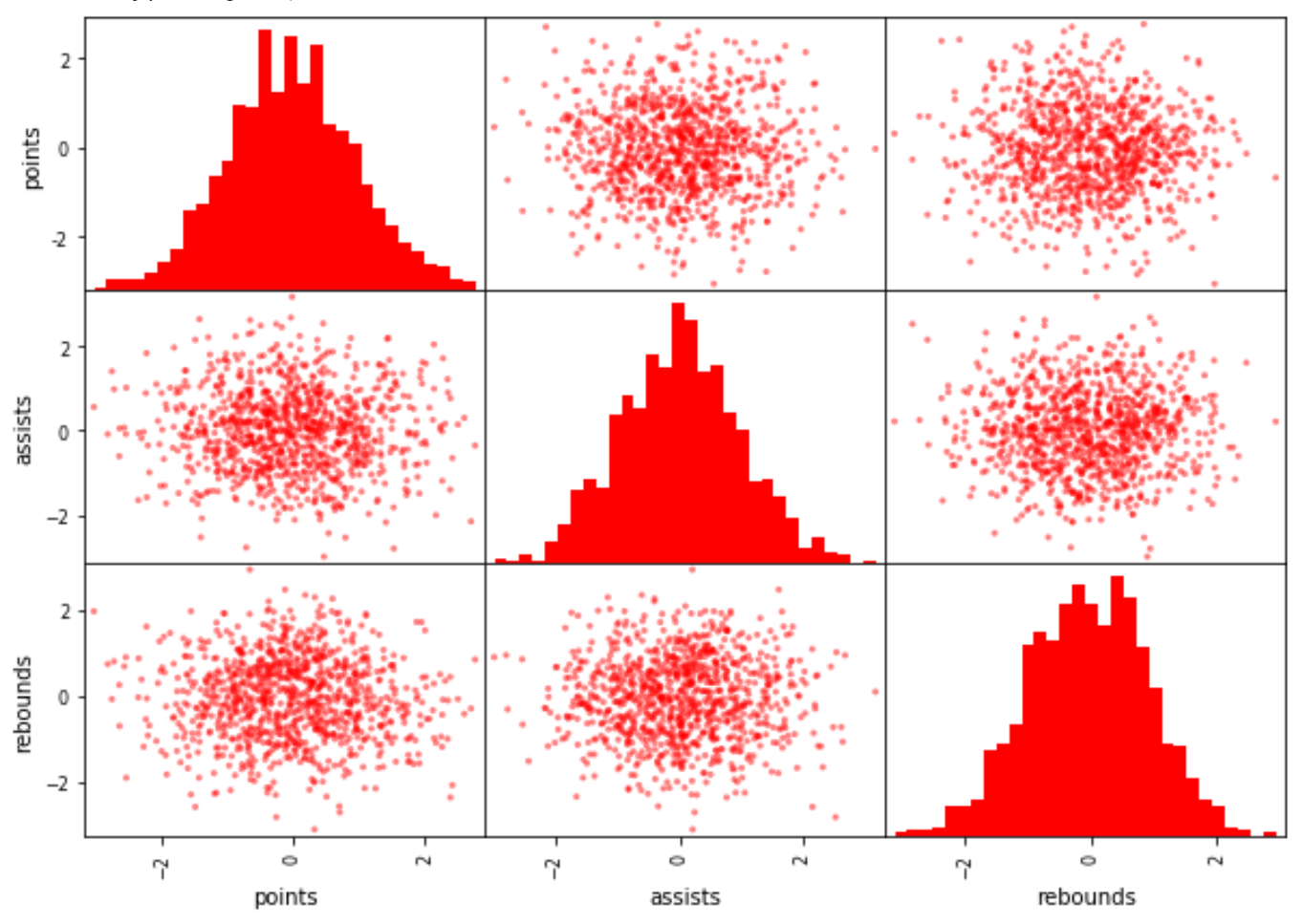
Пример 4: Матрица рассеяния с графиком KDE
В следующем коде показано, как создать матрицу рассеяния с графиком оценки плотности ядра вдоль диагоналей матрицы вместо гистограммы:
pd.plotting.scatter_matrix(df, diagonal='kde') 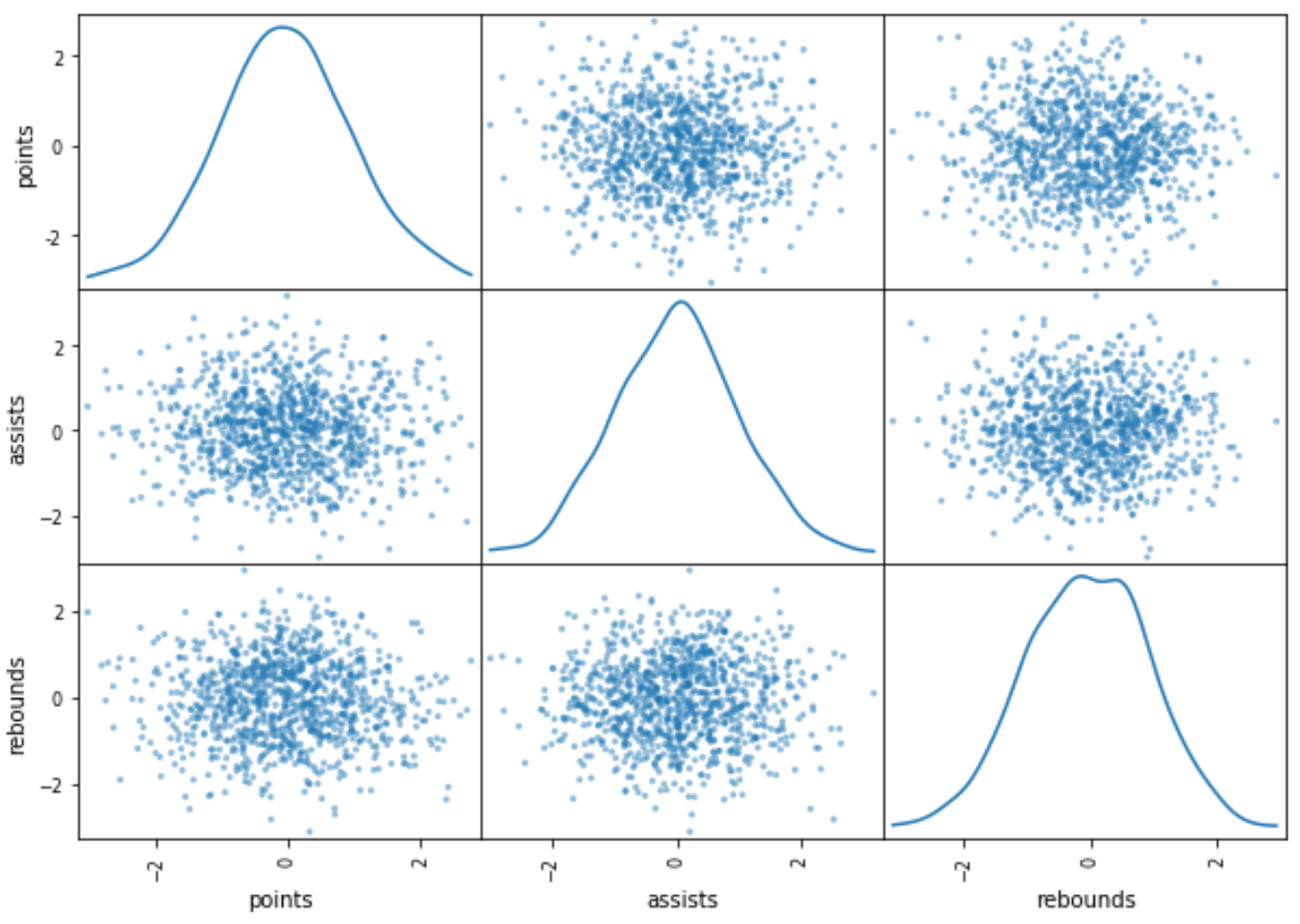
Полную онлайн-документацию по функции scatter_matrix() можно найти здесь .
Дополнительные ресурсы
В следующих руководствах объясняется, как создавать другие распространенные диаграммы в Python:
Диаграмма рассеивания Matplotlib — Учебное пособие и примеры
Matplotlib — одна из наиболее широко используемых библиотек визуализации данных в Python. От простых до сложных визуализаций — это библиотека для большинства.
В этом уроке мы рассмотрим, как построить график рассеивания в Matplotlib.
Импортировать данные
Мы будем использовать набор данных Ames Housing и визуализировать корреляции между объектами из него.
Давайте импортируем Pandas и загрузим набор данных:
import pandas as pd df = pd.read_csv('AmesHousing.csv') Постройте диаграмму рассеивания в Matplotlib
Теперь, когда набор данных загружен, давайте импортируем Matplotlib, определимся с функциями, которые мы хотим визуализировать, и построим диаграмму рассеивания:
import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('AmesHousing.csv') fig, ax = plt.subplots(figsize=(10, 6)) ax.scatter(x = df['Gr Liv Area'], y = df['SalePrice']) plt.xlabel("Living Area Above Ground") plt.ylabel("House Price") plt.show() Здесь мы создали график, используя экземпляр PyPlot, и установили размер фигуры. Используя возвращенный объект Axes , который возвращается из функции subplots() , мы вызвали функцию scatter() .
Мы должны поставить аргументы x и y , которые мы хотели бы использовать, чтобы заполнить участок. Выполнение этого кода приводит к:
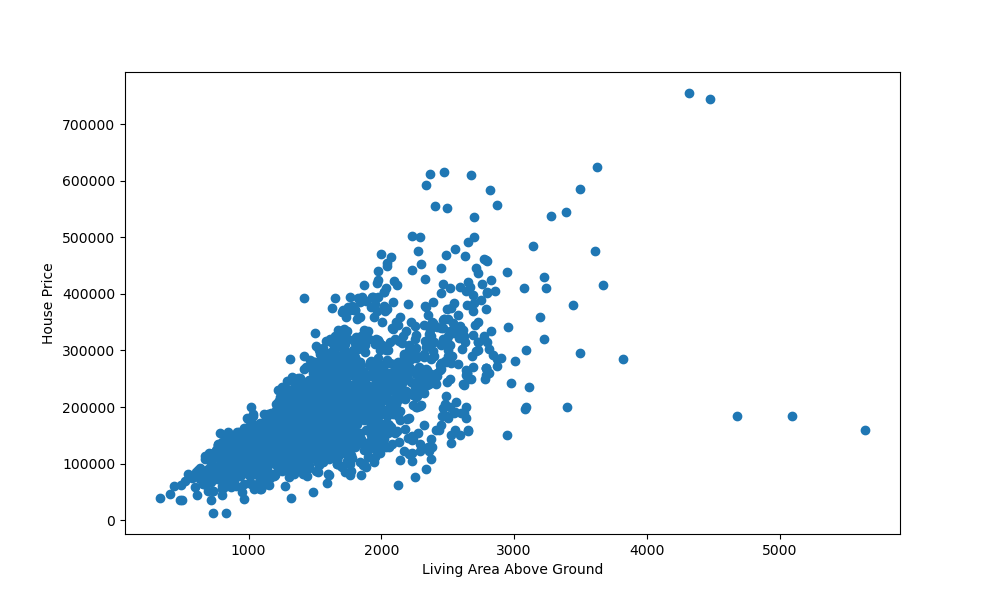
Мы также установили метки x и y, чтобы указать, что представляют собой переменные. Между этими двумя переменными существует явная положительная корреляция. Чем больше площадь над землей, тем выше была цена дома.
Есть несколько отклонений, но подавляющее большинство следует этой гипотезе.
Построение графиков множественного разброса в Matplotlib
Если вы хотите сравнить более одной переменной с другой, например — проверьте корреляцию между общим качеством дома и продажной ценой, а также площадью над уровнем земли — нет необходимости создавать трехмерный график для этого.
Хотя существуют 2D-графики, которые визуализируют корреляции между более чем двумя переменными, некоторые из них не совсем подходят для начинающих.
Самый простой способ сделать это — построить два участка: на одном мы построим график площади над уровнем земли в зависимости от продажной цены, а на другом — общее качество в зависимости от продажной цены.
Давайте посмотрим, как это сделать:
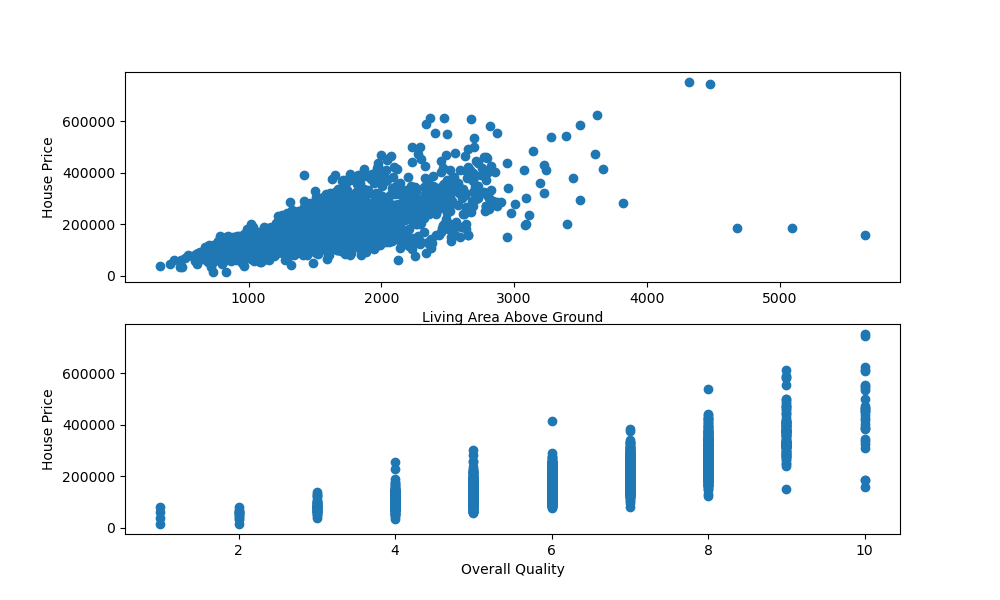
import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('AmesHousing.csv') fig, ax = plt.subplots(2, figsize=(10, 6)) ax[0].scatter(x = df['Gr Liv Area'], y = df['SalePrice']) ax[0].set_xlabel("Living Area Above Ground") ax[0].set_ylabel("House Price") ax[1].scatter(x = df['Overall Qual'], y = df['SalePrice']) ax[1].set_xlabel("Overall Quality") ax[1].set_ylabel("House Price") plt.show() Здесь мы вызвали plt.subplots() , с параметром 2 , чтобы указать, что мы хотели бы создать экземпляры двух подзаголовков на рисунке.
Мы можем получить к ним доступ через экземпляр Axes — ax . ax[0] относится к осям первого подзаголовка, а ax[1] относится к осям второго подзаголовка.
Здесь мы вызвали функцию scatter() для каждого из них, снабдив их метками. Выполнение этого кода приводит к:
Построение трехмерной диаграммы рассеяния в Matplotlib
Если вы не хотите визуализировать это в двух отдельных подзаголовках, вы можете построить корреляцию между этими переменными в 3D. Matplotlib имеет встроенную функцию трехмерного построения графиков, так что сделать это очень просто.
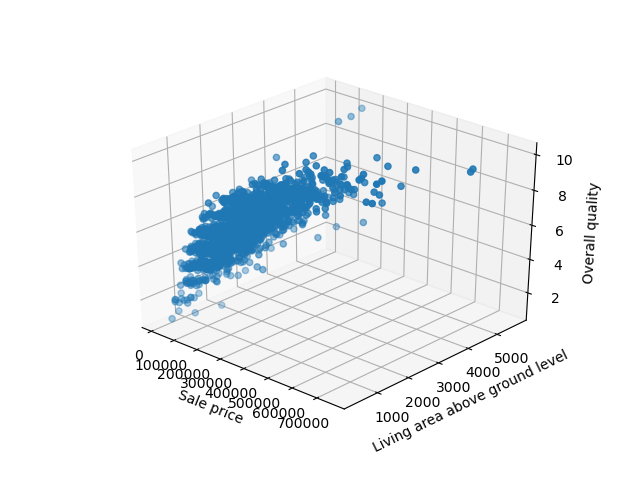
Во-первых, нам нужно импортировать класс Axes3D из mpl_toolkits.mplot3d . Этот специальный тип необходим для 3D-визуализации. С его помощью мы можем передать другой аргумент z — это третья функция, которую мы хотели бы визуализировать.
Давайте продолжим и импортируем объект Axes3D и построим диаграмму рассеяния для трех предыдущих функций:
import matplotlib.pyplot as plt import pandas as pd from mpl_toolkits.mplot3d import Axes3D df = pd.read_csv('AmesHousing.csv') fig = plt.figure() ax = fig.add_subplot(111, projection = '3d') x = df['SalePrice'] y = df['Gr Liv Area'] z = df['Overall Qual'] ax.scatter(x, y, z) ax.set_xlabel("Sale price") ax.set_ylabel("Living area above ground level") ax.set_zlabel("Overall quality") plt.show() Запуск этого кода приводит к интерактивной трехмерной визуализации, которую мы можем панорамировать и исследовать в трехмерном пространстве:
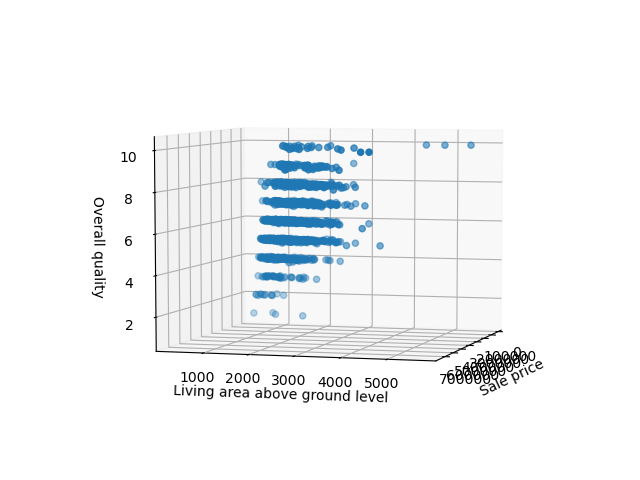
Настройка точечной диаграммы в Matplotlib
Вы можете изменить внешний вид графика, снабдив функцию scatter() дополнительными аргументами, такими как color , alpha и т.д.:
ax.scatter(x = df['Gr Liv Area'], y = df['SalePrice'], color = "blue", edgecolors = "white", linewidths = 0.1, alpha = 0.7) Выполнение этого кода приведет к:
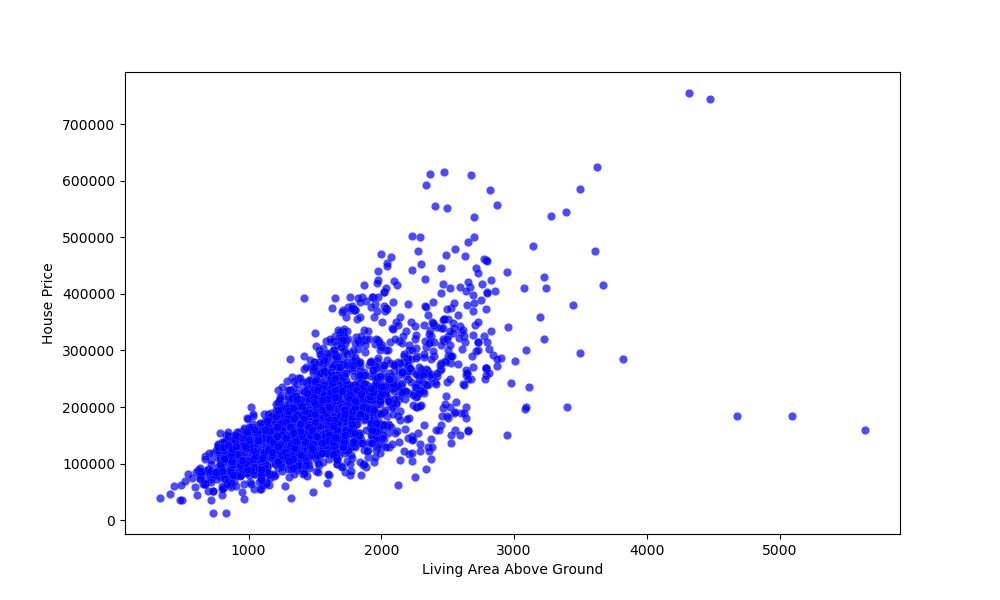
Вывод
В этом руководстве мы рассмотрели несколько способов построения графика рассеяния с использованием Matplotlib и Python