- How to Open HTML File From a Terminal?
- Method 1: Open HTML File in Browser
- Using open Command
- Syntax:
- Using a Browser
- Method 2: Open HTML File Using lynx
- Syntax:
- Bonus Tip: How to Edit the Content of the HTML File?
- Syntax:
- Conclusion
- Linux Command Line: Parsing HTML with w3m and awk
- Download using curl
- Normalize the HTML
- Extract the table we care about
- Format the HTML
- Grab the columns we we want
- All together
- How to Quickly Render Basic HTML in the Command Line
- 1. Overview
- 2. lynx
- 2.1. Rendering a Local HTML File
- 2.2. Fetching and Rendering a Page From the Web
- 3. w3m
- 3.1. Rendering a Local HTML File
- 3.2. Render a Page From the Web
- 4. html2text
- 4.1. Converting HTML Documents to Plain Text
- 4.2. Fetching a Page From the Web
- 5. Conclusion
How to Open HTML File From a Terminal?
Html file is a combination of symbols and text which displays the content of the web page. These files have .html extensions. In Linux, various methods exist to open Html files using the terminal or a graphical user interface. In this post, you will learn how to open Html files using the terminal in Linux. The content of the post is:
Method 1: Open HTML File in Browser
In Linux, you can open any Html file in your browser. There are two ways available for opening any Html file through the terminal. Let’s discuss these two functions one by one.
Using open Command
The “open” is a built-in utility to open any files or directories in Linux. The syntax to open any file using the “open” command is given below:
Syntax:
Write the “open” keyword and then type your Html file name.
Let’s move and check how it works. We have an index.html file in our home directory, which can be seen below:

Let’s open it in the browser using the “open command”.
To open any Html file using the “open” command is obtained as follows:

After executing the above command, it will automatically open the Html in your browser:
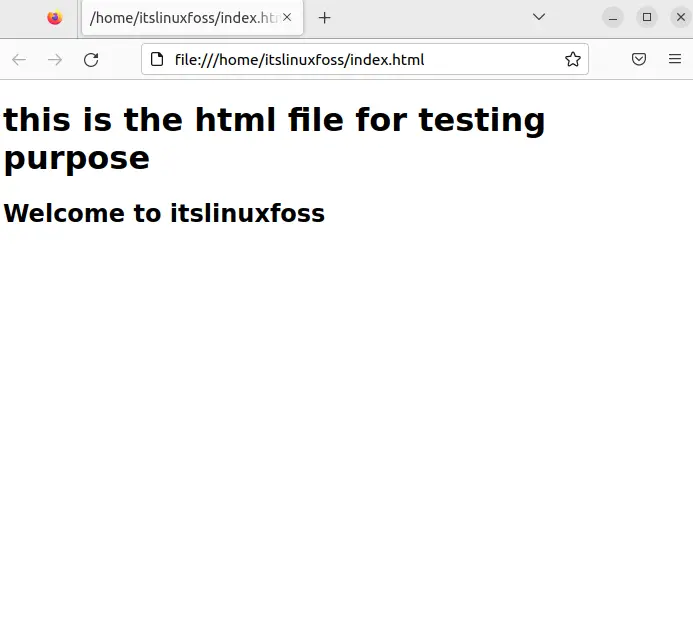
The index.html file is opened in the Firefox browser.
Using a Browser
You can open any Html file using a browser as well, and for that, you need to follow the below-mentioned syntax:
Type any browser name and then type your Html file name.
To open any Html file using the browser name, execute the following command in the terminal:
Once the above command is executed, the file will be opened in the browser. In our scenario, we have opened it in the chromium browser as shown in the below image:
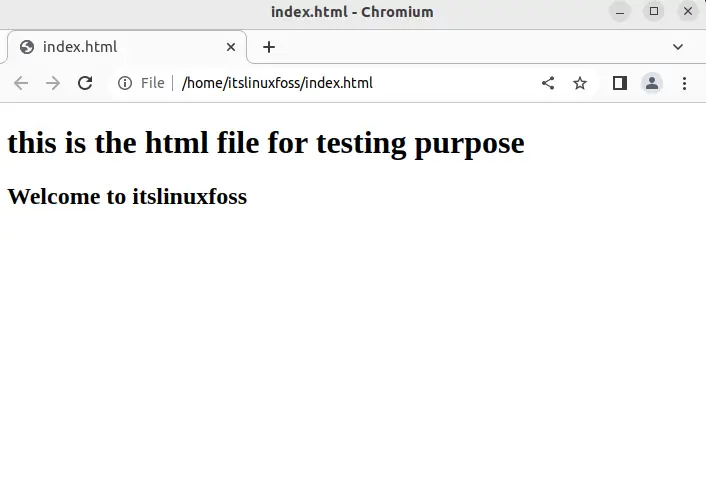
The index.html file has been opened in the chromium browser.
Note: You can also use the bash script to open Html files in the browser. Just type in the bash script file and save it:
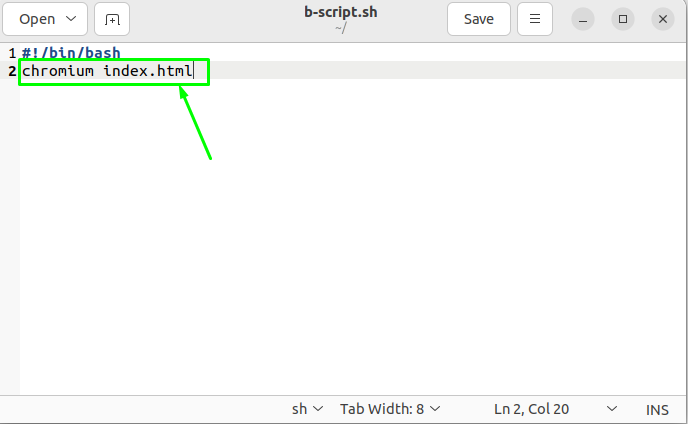
Once you save it, run the bash script file in the terminal:
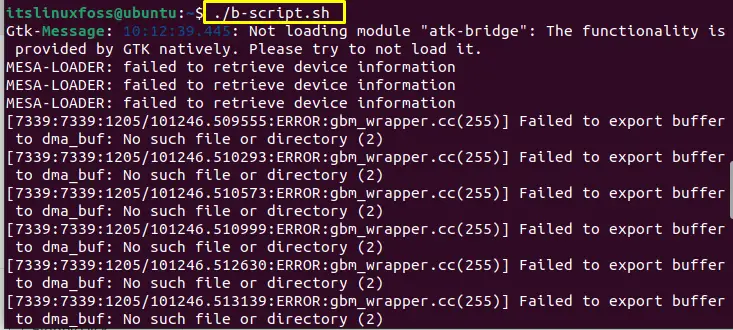
The execution of the above command will give you the same output.
Let’s move towards method 2 to open Html files.
Method 2: Open HTML File Using lynx
Another method that can be used to open an Html file is using the “lynx”. “lynx” is a terminal-based web browser that prints the output of the file as plain text in the terminal. In simple words, it’s a non-graphical web browser that shows the web pages on the terminal. It is not pre-installed in Linux distributions; user can install it manually by executing the below command:
For Ubuntu/Debian:
For Fedora/CentOS/RHEL:
The syntax for using the “lynx” is shown below:
Syntax:
Type the “lynx” keyword, “options” for different modes and then file name.
To open an HTML file using “lynx”, use the “dump” option. “dump” option represents the standard output (stdout). Run the following command to see the results:

The content of the Html has been displayed as plain text.
Note: lynx will only print the Html content of the file. However, if you put any javascript content in an Html file, the javascript content will not be printed.
Using lynx, users can also open the Html file in its editor. To do so, use the lynx without option:

Once you type the command, press Enter:

An Html file is opened in the lynx text editor.
These are the possible methods to open an Html file using the terminal.
Bonus Tip: How to Edit the Content of the HTML File?
There are different commands available to open and edit the files in the text editor, such as pico, nano, vi, and much more. In our case, we are using the “nano” editor to open the Html file. The syntax for the nano editor command is shown below:
Syntax:
Write the “nano” keyword and then type the file name.
To open any Html file using the “nano” command is obtained as follows:
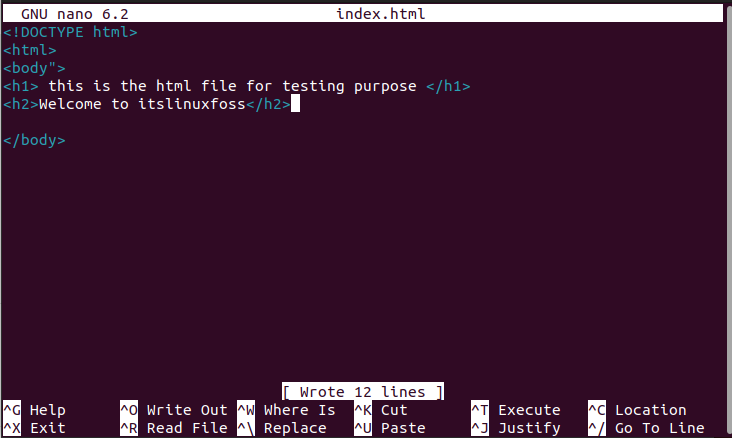
Once you execute the above command, it will open the Html file in the nano text editor from where you can edit the content of that HTML file.
Conclusion
To open any HTML file using the terminal, there are three methods. The first method is to open an HTML file in the browser using the “open” command or use any browser name along with the file name. The second method is to open an HTML file in text editors such as nano, while the third is to open an HTML file using lynx. This post has demonstrated all the possible ways to open an HTML file through a terminal in Linux.
Linux Command Line: Parsing HTML with w3m and awk
I needed to generate some fake data to simulate transactions. I wanted some valid merchant names to make the data look reasonable. After failing to search the internt for a nice CSV containing merchant names I settled on this Top 100 Retailers Chart 2011. Unfortunatly when you copy and paste the table you get a run together mess.
1 Wal-Mart Bentonville, Ark. $307,736,000 0.6% $421,886,000 72.9% 4,358 1.3% 2 Kroger Cincinnati $78,326,000 6.4% $78,326,000 100.0% 3,609 -0.4% 3 Target Minneapolis $65,815,000 3.8% $65,815,000 100.0% 1,750 0.6% 4 Walgreen Deerfield, Ill. $61,240,000 6.3% $63,038,000 97.1% 7,456 8.1% 5 The Home Depot Atlanta $60,194,000 2.2% $68,000,000 88.5% 1,966 0.0% — See more at: https://nrf.com/resources/top-retailers-list/top-100-retailers-2011#sthash.RUUwpfm0.dpuf
Download using curl
This is the easiest part and most Linux systems will have this installed by default.
curl -s https://nrf.com/resources/top-retailers-list/top-100-retailers-2011-s will tell curl to be silent with it’s messages. The output will go to standard output.
Normalize the HTML
Before we extract content from the HTML we need it to be normalized. To do this we can use hxnormalize by w3.org in their HTML-XML-utils package.
-x will tell hxnormalize to output XHTML.
Extract the table we care about
Now we need only the content we care about. HTML-XML-utils package has a tool for this as well hxselect .
‘table.views-table’ tells hxselect to extract all table with a CSS selector of views-table .
Format the HTML
w3m is a command line text based web browser. It can also just dump formatted HTML to standard out which is what I used it for.
. | w3m -dump -cols 2000 -T 'text/html'-dump tells w3m to write it’s output to standard out as opposed to a scrollable viewer. -cols 2000 ensures we don’t have wrapping of the lines which would make parsing more tedious. -T ‘text/html tells w3m that the input should be treated as HTML.
Grab the columns we we want
Finally we need to grab only the first column. awk will help with that.
Lets break down the awk script a little. BEGIN <. >is used to run something before we start processing data. In this case FIELDWIDTHS=»5 29″ tells awk that the first 5 columns are field 1 and the next 29 columns are field 2 and the remaining columns are field 3.
The second part of the awk script is what will run on each line. The first two gsub statements will trim the start and end of the respectively. Finally print $2 will print the 2nd column which in our case is the company name.
All together
Here is the final full command to run.
curl -s https://nrf.com/resources/top-retailers-list/top-100-retailers-2011 \ | hxnormalize -x \ | hxselect -s '\n' 'table.views-table' \ | w3m -dump -cols 2000 -T 'text/html' \ | awk 'BEGIN' How to Quickly Render Basic HTML in the Command Line
![]()
The Kubernetes ecosystem is huge and quite complex, so it’s easy to forget about costs when trying out all of the exciting tools.
To avoid overspending on your Kubernetes cluster, definitely have a look at the free K8s cost monitoring tool from the automation platform CAST AI. You can view your costs in real time, allocate them, calculate burn rates for projects, spot anomalies or spikes, and get insightful reports you can share with your team.
Connect your cluster and start monitoring your K8s costs right away:
1. Overview
In this tutorial, we’ll discuss several text-based web browsers and tools used for converting HTML to plain text. These tools are particularly useful for those who prefer a minimalist approach to web browsing or who need to convert web pages into a format that is easier to read or manipulate.
Indeed, we cannot use the command line for complex web functions like dynamic content generation and complex input controls like the select menu, date picker, color chooser, and so on.
Therefore, for our example, we’ll render a basic HTML page with the following source code:
2. lynx
lynx is a versatile text-based web browser that allows users to browse the internet and access websites without the need for a graphical user interface.
By default, it doesn’t ship with most Linux distributions. However, it’s available on most official repositories. We can install it with a package manager like apt under the canonical name lynx:
Once installed, let’s verify it:
$ lynx --versoin Lynx Version 2.8.9rel.1 (08 Jul 2018) libwww-FM 2.14, SSL-MM 1.4.1, OpenSSL 3.1.0, ncurses 5.7.200811022.1. Rendering a Local HTML File
By default, running lynx will open up the browser, which we can use to navigate the web. However, it has a specific -dump option that takes an HTML page as an argument.
Let’s see its general syntax:
-dump renders the HTML page in the command line:
$ lynx -dump index.html Baeldung * [1]About * [2]Tutorials * [3]Contact About Baeldung Baeldung is a website that offers a wide range of articles and tutorials on various Java-related topics. Tutorials Baeldung offers tutorials on topics such as Spring Framework, Hibernate, Linux, and many more. Contact You can contact Baeldung through their website or by email at [email protected] ? 2023 Baeldung References 1. file:///Users/himhaidar/Documents/index.html#about 2. file:///Users/himhaidar/Documents/index.html#tutorials 3. file:///Users/himhaidar/Documents/index.html#contactIt isn’t that pretty, but it gets the job done quickly.
2.2. Fetching and Rendering a Page From the Web
In addition to that, we can also fetch and render a page from the web using curl:
$ curl -Ls "https://en.wikipedia.org/wiki/Cryptosystem" | lynx -dump -stdin . In [64]cryptography, a cryptosystem is a suite of [65]cryptographic algorithms needed to implement a particular security service, such as confidentiality ([66]encryption).^[67][1] Typically, a cryptosystem consists of three algorithms: one for [68]key . The -stdin flag lets lynx read the contents from the standard output instead of a file. However, we can also directly type in the URL and dump the page:
$ lynx -dump "https://en.wikipedia.org/wiki/Cryptosystem"3. w3m
w3m is a Text-based UI(TUI) web browser that allows us to render and view web pages in an efficient manner. Additionally, we can also integrate it with text editors like Vim and Emacs for quick browsing.
Like lynx, it’s not installed on most distributions. So, we’ll need to install it using its canonical name, w3m:
Once installed, we can verify it:
$ w3m -version w3m version w3m/0.5.3+git20200502, options lang=en,m17n,color,ansi-color,mouse,menu,cookie,ssl,ssl-verify,external-uri-loader,w3mmailer,nntp,ipv6,alarm,mark3.1. Rendering a Local HTML File
Here’s the usage syntax for w3m:
Similar to lynx, w3m also has a -dump option that lets us render an HTML file:
As we can see, there’s less clutter as compared to the lynx result.
3.2. Render a Page From the Web
We can render a page from the web by giving the URL as an input instead of a local file:
$ w3m -dump https://en.wikipedia.org/wiki/Cryptosystem4. html2text
html2text is a Python script that lets us extract textual data from an HTML page. We can use it to render local HTML files on the system.
Like the other tools, html2text isn’t installed on most Linux distributions. So, we’ll need to install it from the PyPI using pip:
Once installed, let’s verify it:
$ html2text -version This is html2text, version 2.1.14.1. Converting HTML Documents to Plain Text
Like the other tools, html2text has a straightforward syntax:
Notably, it can only render a file on the disk and cannot fetch a page from the web on its own. So, let’s go ahead and feed it our HTML file:
4.2. Fetching a Page From the Web
We can use curl to fetch and input a page to html2text:
In the snippet, instead of a file, we used a Here String that emulates the same process as providing a file as an input.
5. Conclusion
In this article, we discuss how we can render and view HTML pages in the command line. For that purpose, we used the famous lynx, w3m, and html2text tools.
While there are other tools available on the web, these are readily available for installation on most package repositories.