Метод наименьших квадратов
На этом занятии мы с вами рассмотрим алгоритм, который носит название метод наименьших квадратов. Для начала немного теории. Чтобы ее хорошо понимать нужны базовые знания по теории вероятностей, в частности понимание ПРВ, а также знать, что такое производная и как она вычисляется. Остальное я сейчас расскажу.
На практике встречаются задачи, когда производились измерения некоторой функциональной зависимости, но из-за погрешностей приборов, или неточных сведений или еще по какой-либо причине, измерения немного отстоят от истинных значений функции и образуют некий разброс:
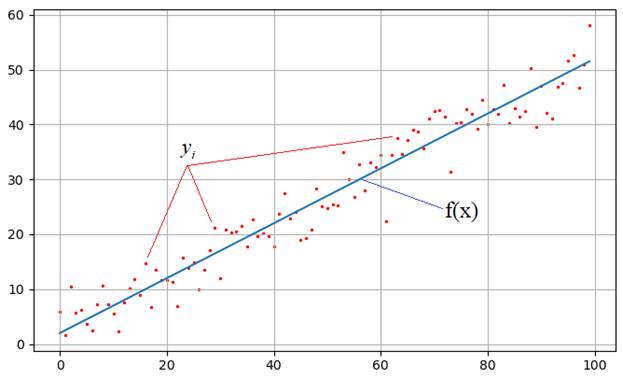
Наша задача: зная характер функциональной зависимости, подобрать ее параметры так, чтобы она наилучшим образом описывала экспериментальные данные Например, на рисунке явно прослеживается линейная зависимость. Мы это можем определить либо чисто визуально, либо заранее знать о характере функции. Но, в любом случае предполагается, что ее общий вид нам известен. Так вот, для линейной функции достаточно определить два параметра k и b:
чтобы построить аппроксимацию (приближение) линейного графика к экспериментальным зависимостям. Конечно, вид функциональной зависимости может быть и другим, например, квадратической (парабола), синусоидальной, или даже определяться суммой известных функций, но для простоты понимания, мы для начала рассмотрим именно линейный график с двумя неизвестными коэффициентами.
Итак, будем считать, что на первый вопрос о характере функциональной зависимости экспериментальных данных ответ дан. Следующий вопрос: как измерить качество аппроксимации измерений функцией  ? Вообще, таких критериев можно придумать множество, например:
? Вообще, таких критериев можно придумать множество, например:
— сумма квадратов ошибок отклонений:
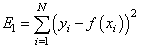
— сумма модулей ошибок отклонений:
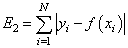
— минимум максимальной по модулю ошибки:
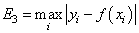
и так далее. Каждый из критериев может приводить к своему алгоритму обработки экспериментальных значений. Так вот, в методе наименьших квадратов используется минимум суммы квадратов ошибок. И этому есть математическое обоснование. Часто результаты реальных измерений имеют стандартное (гауссовское) отклонение относительно измеряемого параметра:
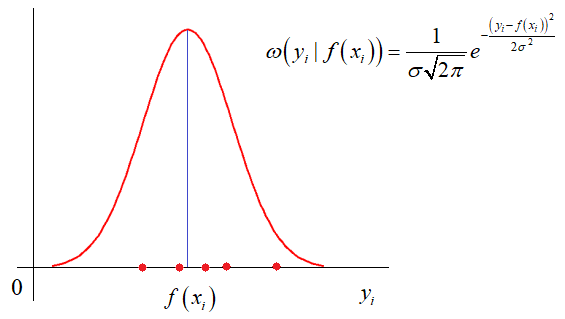
Здесь σ – стандартное отклонение (СКО) наблюдаемых значений от функции . Отсюда хорошо видно, что чем ближе измерение к истинному значению параметра, тем больше значение функции плотности распределения условной вероятности. И, так для всех точек измерения. Учитывая, что они выполняются независимо друг от друга, то можно записать следующее функциональное выражение:
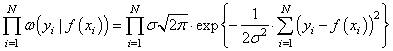
Получается, что лучшее описание экспериментальных данных с помощью функции должно проходить по точкам, в которых достигается максимум этого выражения. Очевидно, что при поиске максимума можно не учитывать множитель 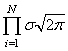 , а экспонента будет принимать максимальное значение при минимуме ее отрицательной степени:
, а экспонента будет принимать максимальное значение при минимуме ее отрицательной степени:
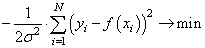
Здесь также множитель можно не учитывать, получаем критерий качества минимум суммы квадрата ошибок:
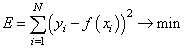
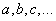
Как мы помним, наша цель – подобрать параметры функции
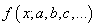
которые как раз и обеспечивают минимум этого критерия, то есть, величина E зависит от этих подбираемых величин:
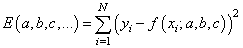
И ее можно рассматривать как квадратическую функцию от аргументов Из школьного курса математики мы знаем как находится точка экстремума функции – это точка, в которой производная равна нулю:
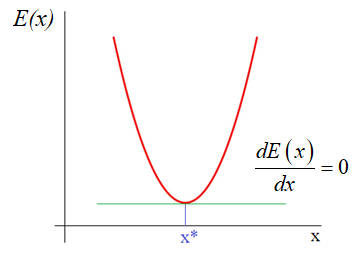
Здесь все также, нужно взять частные производные по каждому параметру и приравнять результат нулю, получим систему линейных уравнений:
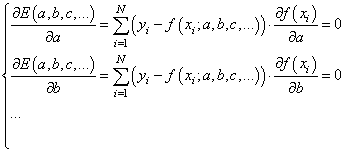
Чтобы наполнить конкретикой эту систему, нам нужно вернуться к исходному примеру с линейной функцией:
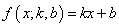
Эта функция зависит от двух параметров: k и b с частными производными:
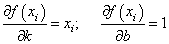
Подставляем все в систему, имеем:
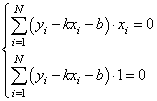
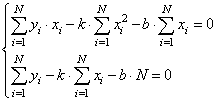
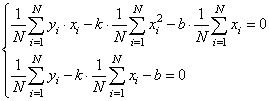
Смотрите, что в итоге получилось. Формулы с суммами представляют собой первые и вторые начальные моменты, а также один смешанный момент:
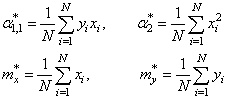
Здесь * означает экспериментальные моменты. В этих обозначениях, получаем:
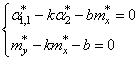
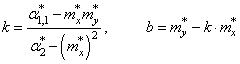
Все, мы получили оценки параметров k и b для линейной аппроксимации экспериментальных данных по методу наименьших квадратов. По аналогии можно вычислять параметры для других функциональных зависимостей, например, квадратической:
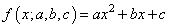
Здесь будет уже три свободных параметра и три уравнения, решая которые будем получать лучшую аппроксимацию по критерию минимума суммарной квадратической ошибки отклонений.
Реализация на Python
В заключение этого занятия реализуем метод наименьших квадратов на Python. Для этого нам понадобятся две довольно популярные библиотеки numpy и matplotlib. Если они у вас не установлены, то делается это просто – через команды:
После этого, мы можем их импортировать и использовать в программе:
import numpy as np import matplotlib.pyplot as plt
Первая довольно эффективная для выполнения различных математических операций, включая векторные и матричные. Вторая служит для построения графиков.
Итак, вначале определим необходимые начальные величины:
N = 100 # число экспериментов sigma = 3 # стандартное отклонение наблюдаемых значений k = 0.5 # теоретическое значение параметра k b = 2 # теоретическое значение параметра b
Формируем вспомогательный вектор
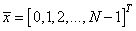
с помощью метода array, который возвращает объект-вектор на основе итерируемой функции range:
Затем, вычисляем значения теоретической функции:
f = np.array([k*z+b for z in range(N)])
и добавляем к ней случайные отклонения для моделирования результатов наблюдений:
y = f + np.random.normal(0, sigma, N)
Если сейчас отобразить наборы точек y, то они будут выглядеть следующим образом:
plt.scatter(x, y, s=2, c='red') plt.grid(True) plt.show()
Теперь у нас все есть для вычисления коэффициентов k и b по экспериментальным данным:
# вычисляем коэффициенты mx = x.sum()/N my = y.sum()/N a2 = np.dot(x.T, x)/N a11 = np.dot(x.T, y)/N kk = (a11 - mx*my)/(a2 - mx**2) bb = my - kk*mx
Здесь выражение x.T*x – это произведение:
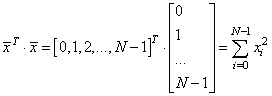
Далее, построим точки полученной аппроксимации:
ff = np.array([kk*z+bb for z in range(N)])
и отобразим оба линейных графика:
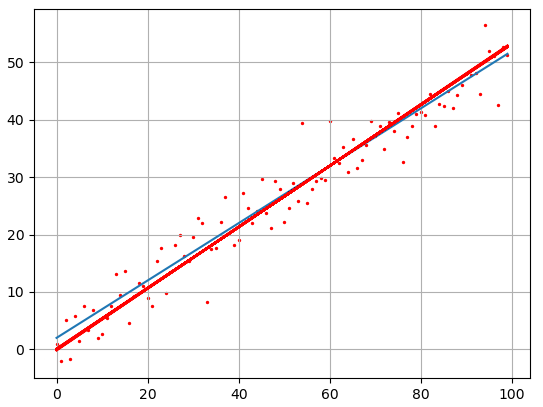
Как видите результат аппроксимации довольно близок начальному, теоретическому графику. Вот так работает метод наименьших квадратов.
Видео по теме

#1: Метод наименьших квадратов

#2: Метод градиентного спуска

#3: Метод градиентного спуска для двух параметров

#4: Марковские процессы в дискретном времени

#5: Фильтр Калмана дискретного времени

#6: Фильтр Калмана для авторегрессионого уравнения

#7: Векторный фильтр Калмана


#9: Байесовское построение оценок, метод максимального правдоподобия

#10: Байесовский классификатор, отношение правдоподобия
© 2023 Частичное или полное копирование информации с данного сайта для распространения на других ресурсах, в том числе и бумажных, строго запрещено. Все тексты и изображения являются собственностью сайта
NumPy Polyfit


Изучение
Линейная регрессия — это первый шаг к изучению науки о данных. Поэтому, даже если вы новичок в этой области, вы должны понимать эти концепции, потому что эти алгоритмы в основном используются исследователями в области науки о данных. Эти алгоритмы также легко понять, чтобы начать путешествие по машинному обучению.
В этом руководстве мы увидим модель регрессии numpy (polyfit).
Функция numpy.polyfit () находит наиболее подходящую линию, минимизируя сумму квадратов ошибок. Этот метод принимает три параметра:
Итак, приступим к пошаговому процессу использования метода polyfit.
Шаг 1. Импортируйте всю необходимую библиотеку и пакеты для запуска этой программы.

Строка 91: мы импортируем библиотеки NumPy и matplotlib. Polyfit автоматически попадает под NumPy, поэтому нет необходимости импортировать. Matplotlib используется для построения данных, а matplotlib inline используется для рисования графика внутри самого ноутбука jupyter.
import numpy as np
import matplotlib. pyplot as plt
%matplotlib inline
Шаг 2: Теперь наш следующий шаг — создать набор данных (x и y).

Строка 83: мы произвольно генерируем данные x и y.
x = [ 28 , 8 , 11 , 37 , 15 , 25 , 51 , 11 , 32 , 34 , 43 , 2 , 40 , 16 , 40 , 25 , 40 , 17 , 21 , 57 ]
y = [ 8 , 8 , 9 , 72 , 22 , 51 , 85 , 4 , 75 , 48 , 72 , 1 , 62 , 37 , 75 , 42 , 75 , 47 , 57 , 95 ]
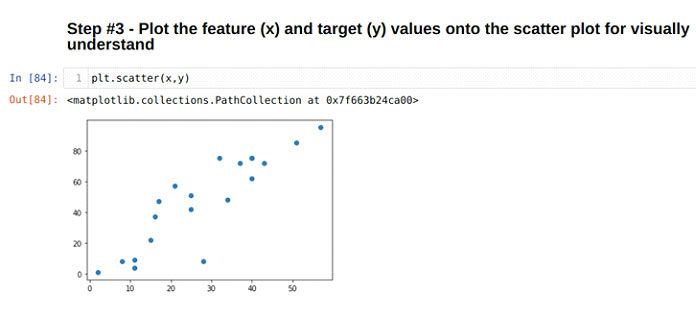
Шаг 3: Мы просто собираемся нанести объект (x) и цель (y) на график, как показано ниже:
Шаг 4: На этом шаге мы собираемся подогнать линию к данным x и y.

Этот шаг очень прост, потому что мы собираемся использовать концепцию метода полифита. Метод polyfit напрямую поставляется с Numpy, как показано выше. Этот метод принимает три параметра:
В этой программе мы используем значение степени полинома 1, что означает, что это многочлен первой степени. Но мы также можем использовать его для полиномов второй и третьей степени.
Когда мы нажимаем Enter, полифит вычисляет модель линейной регрессии и сохраняет в правой части модель переменных.
Логика за подходящей линией
Итак, мы видим, что просто нажав клавишу ввода, мы получили модель линейной регрессии. Итак, теперь мы думаем о том, что на самом деле работает за этим методом и как они подходят к линии.
Метод, который работает позади метода полифита, называется обычным методом наименьших квадратов. Некоторые назвали это коротким названием OLS. Пользователи обычно используют его, чтобы подогнать под линию. Причина в том, что он очень прост в использовании, а также дает точность выше 90%.
Посмотрим, как работает OLS:
Во-первых, нам нужно знать об ошибке. Ошибка вычисляется через разницу между данными x и y.
Например, мы помещаем линию в регрессионную модель, которая выглядит следующим образом:
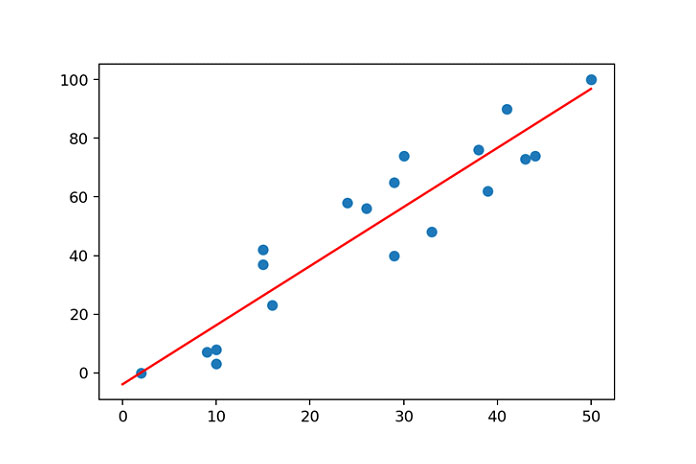
Синие точки — это точки данных, а красная линия, которую мы помещаем в точки данных, используя метод polyfit.
Предположим, что x = 24 и y = 58.
Когда мы подбираем линию, она вычисляет значение y = 44,3. Разница между фактическим и расчетным значением — это ошибка для конкретной точки данных.
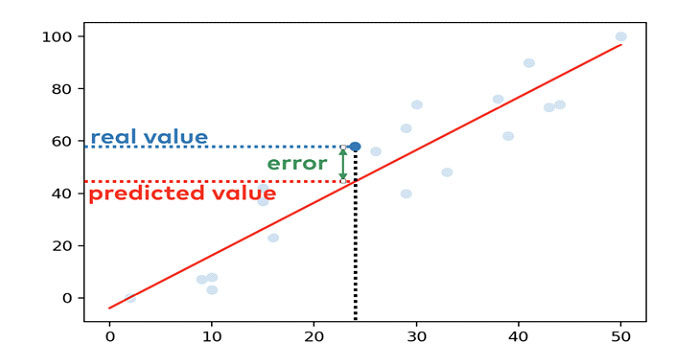
Итак, метод наименьших квадратов (OLS) вычисляет аппроксимацию, используя следующие шаги:

- Вычисляет ошибку между подобранной моделью и точками данных.
- Затем мы возводим в квадрат каждую ошибку точек данных.
- Просуммируйте все ошибки квадратных точек данных.
- Наконец, определите линию, в которой сумма квадратов ошибок минимальна.
Итак, полифит использует вышеуказанные методы для подгонки линии.
Шаг 5: Модель
Мы закончили кодирование машинного обучения. Теперь мы можем проверить значения x и y, которые хранятся в переменных модели. Чтобы проверить значения x и y, мы должны распечатать модель, как показано ниже:
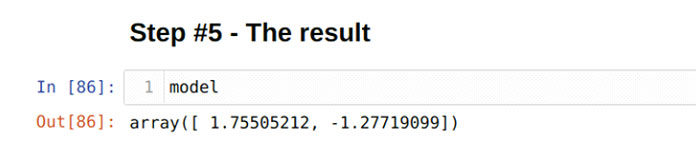
Наконец, мы получили контурное уравнение:
у = 1,75505212 * х — 1,27719099
Используя это линейное уравнение, мы можем получить значение y.
Вышеупомянутое линейное уравнение также можно решить с помощью метода ploy1d (), как показано ниже:
predict = np. poly1d ( model )
x_value = 20
predict ( x_value )

Получили результат 33.82385131766588.
Тот же результат мы получили и от ручного расчета:
у = 1,75505212 * 20 — 1,27719099
Итак, оба приведенных выше результата показывают, что наша модель правильно подходит для этой линии.
Шаг 6: точность модели
Мы также можем проверить точность модели, дает ли она правильные результаты или нет. Точность модели можно рассчитать с помощью R-квадрата (R2). Значение R-квадрата (R2) находится между 0 и 1. Результат, близкий к 1, показывает, что точность модели высока. Итак, проверим точность приведенной выше модели. Мы импортируем другую библиотеку, sklearn, как показано ниже:
from sklearn. metrics import r2_score
r2_score ( y , predict ( x ) )

Результат показывает, что он близок к 1, поэтому его точность высока.
Шаг 7: Построение модели
Построение графика — это метод визуального просмотра линии, подобранной модели, на точках данных. Это дает четкое изображение модели.

x_axis = range ( 0 , 60 )
y_axis = predict ( x_axis )
plt. scatter ( x , y )
plt. plot ( x_axis , y_axis , c = ‘g’ )
Краткое объяснение вышеуказанного метода построения графиков приведено ниже:
1 строка : это диапазон, который мы хотим отобразить на графике. В нашем коде мы используем значение диапазона от 0 до 60.
2 строка: будут вычислены все значения диапазона от 0 до 60.
3 строка: мы передаем исходные наборы данных x и y в метод разброса.
4 строка: Мы, наконец, строим наш график, и зеленая линия является подходящей линией, как показано на приведенном выше графике.
Заключение
В этой статье мы узнали о модели линейной регрессии, которая является началом пути машинного обучения. Существует ряд регрессионных моделей, которые описаны в другой статье. Здесь у нас есть чистый набор данных, потому что он был фиктивным, но в реальных проектах вы можете получить грязный набор данных, и вам нужно будет выполнить проектирование функций для этого, чтобы очистить набор данных для использования в модели. Если вы не полностью понимаете этот учебник, даже он поможет вам легко изучить другую модель регрессии.
Модель линейной регрессии — наиболее распространенный алгоритм, используемый в науке о данных. У вас должно быть представление о регрессионной модели, если вы хотите сделать карьеру в этой области.