- Join in Pandas: Merge data frames (inner, outer, right, left join) in pandas python
- Join or Merge in Pandas – Syntax:
- UNDERSTANDING THE DIFFERENT TYPES OF JOIN OR MERGE IN PANDAS:
- Lets try different Merge or join operation with an example:
- Create dataframe:
- Inner join pandas:
- Outer join in pandas:
- Left outer Join or Left join pandas:
- Right outer join or Right Join pandas:
- OTHER TYPES OF JOINS & CONCATENATION IN PANDAS PYTHON
- Join based on Index in pandas python (Row index):
- Concatenate or join on Index in pandas python and keep the same index:
- Concatenate or join on Index in pandas python and change the index:
- Concatenate or join based on column index in pandas python:
- Author
- Related Posts:
- Как сделать левое соединение в Pandas (с примером)
- Пример: как сделать левое соединение в Pandas
- Дополнительные ресурсы
- pandas.DataFrame.join#
Join in Pandas: Merge data frames (inner, outer, right, left join) in pandas python
We can Join or merge two data frames in pandas python by using the merge() function. The different arguments to merge() allow you to perform natural join, left join, right join, and full outer join in pandas. We have also seen other type join or concatenate operations like join based on index,Row index and column index.
Join or Merge in Pandas – Syntax:
left_df – Dataframe1
right_df– Dataframe2.
on− Columns (names) to join on. Must be found in both the left and right DataFrame objects.
how – type of join needs to be performed – ‘left’, ‘right’, ‘outer’, ‘inner’, Default is inner join
The data frames must have same column names on which the merging happens. Merge() Function in pandas is similar to database join operation in SQL.
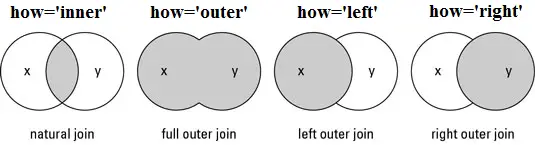
UNDERSTANDING THE DIFFERENT TYPES OF JOIN OR MERGE IN PANDAS:
- Inner Join or Natural join: To keep only rows that match from the data frames, specify the argument how= ‘inner’.
- Outer Join or Full outer join:To keep all rows from both data frames, specify how= ‘outer’.
- Left Join or Left outer join:To include all the rows of your data frame x and only those from y that match, specify how= ‘left’.
- Right Join or Right outer join:To include all the rows of your data frame y and only those from x that match, specify how= ‘right’.
Lets try different Merge or join operation with an example:
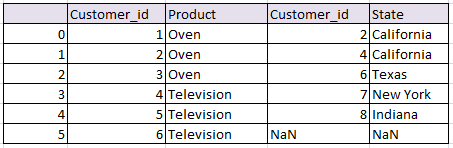
Create dataframe:
import pandas as pd import numpy as np # data frame 1 d1 = df1 = pd.DataFrame(d1) # data frame 2 d2 = df2 = pd.DataFrame(d2)
so we will get following two data frames
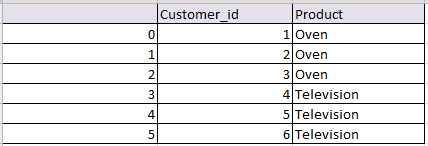
df1:
df2:

Inner join pandas:
Return only the rows in which the left table have matching keys in the right table
#inner join in python pandas inner_join_df= pd.merge(df1, df2, on='Customer_id', how='inner') inner_join_df
the resultant data frame df will be

Outer join in pandas:
Returns all rows from both tables, join records from the left which have matching keys in the right table.When there is no Matching from any table NaN will be returned
# outer join in python pandas outer_join_df=pd.merge(df1, df2, on='Customer_id', how='outer') outer_join_df
the resultant data frame df will be
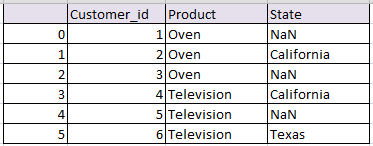
Left outer Join or Left join pandas:
Return all rows from the left table, and any rows with matching keys from the right table.When there is no Matching from right table NaN will be returned
# left join in python left_join_df= pd.merge(df1, df2, on='Customer_id', how='left') left_join_df
the resultant data frame df will be
Right outer join or Right Join pandas:
Return all rows from the right table, and any rows with matching keys from the left table.
# right join in python pandas right_join_df= pd.merge(df1, df2, on='Customer_id', how='right') right_join_df
the resultant data frame df will be
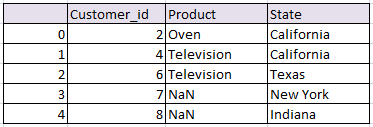
OTHER TYPES OF JOINS & CONCATENATION IN PANDAS PYTHON
Join based on Index in pandas python (Row index):
Simply concatenated both the tables based on their index.
# join based on index python pandas df_index = pd.merge(df1, df2, right_index=True, left_index=True) df_index
the resultant data frame will be
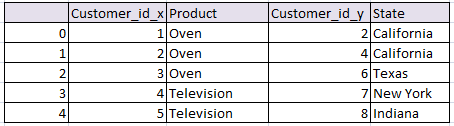
Concatenate or join on Index in pandas python and keep the same index:
Concatenates two tables and keeps the old index .
# Concatenate and keep the old index python pandas df_row = pd.concat([df1, df2]) df_row
the resultant data frame will be
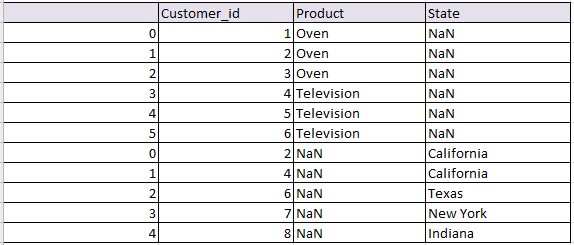
Concatenate or join on Index in pandas python and change the index:
Concatenates two tables and change the index by reindexing.
# Concatenate and change the index python pandas df_row_reindex = pd.concat([df1, df2], ignore_index=True) df_row_reindex
the resultant data frame will be
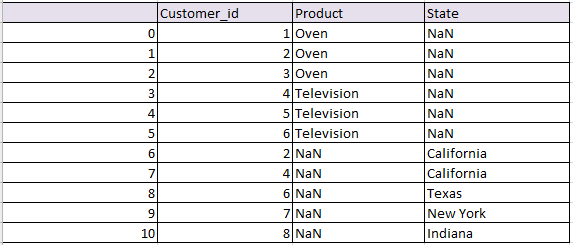
Concatenate or join based on column index in pandas python:
Simply concatenated both the tables based on their column index. Axis =1 indicates concatenation has to be done based on column index
# join based on index python pandas df_col = pd.concat([df1,df2], axis=1) df_col
the resultant data frame will be
Author
With close to 10 years on Experience in data science and machine learning Have extensively worked on programming languages like R, Python (Pandas), SAS, Pyspark. View all posts
Related Posts:
Как сделать левое соединение в Pandas (с примером)
Вы можете использовать следующий базовый синтаксис для выполнения левого соединения в pandas:
import pandas as pd df1.merge(df2, on='column_name', how='left') В следующем примере показано, как использовать этот синтаксис на практике.
Пример: как сделать левое соединение в Pandas
Предположим, у нас есть следующие два кадра данных pandas, которые содержат информацию о различных баскетбольных командах:
import pandas as pd #create DataFrame df1 = pd.DataFrame() df2 = pd.DataFrame() #view DataFrames print(df1) team points 0 A 18 1 B 22 2 C 19 3 D 14 4 E 14 5 F 11 6 G 20 7 H 28 print(df2) team assists 0 A 4 1 B 9 2 C 14 3 D 13 4 G 10 5 H 8 Мы можем использовать следующий код для выполнения левого соединения, сохраняя все строки из первого фрейма данных и добавляя любые столбцы, которые совпадают на основе столбца команды во втором фрейме данных:
#perform left join df1.merge(df2, on='team', how='left') team points assists 0 A 18 4.0 1 B 22 9.0 2 C 19 14.0 3 D 14 13.0 4 E 14 NaN 5 F 11 NaN 6 G 20 10.0 7 H 28 8.0 Каждая команда из левого кадра данных ( df1 ) возвращается в объединенный кадр данных, и возвращаются только строки в правом кадре данных ( df2 ), которые соответствуют имени команды в левом кадре данных.
Обратите внимание, что две команды в df2 (команды E и F), которые не соответствуют имени команды в df1, просто возвращают значение NaN в столбце Assets объединенного DataFrame.
Обратите внимание, что вы также можете использовать pd.merge() со следующим синтаксисом, чтобы вернуть точно такой же результат:
#perform left join pd.merge(df1, df2, on='team', how='left') team points assists 0 A 18 4.0 1 B 22 9.0 2 C 19 14.0 3 D 14 13.0 4 E 14 NaN 5 F 11 NaN 6 G 20 10.0 7 H 28 8.0 Обратите внимание, что этот объединенный DataFrame совпадает с кадром из предыдущего примера.
Примечание.Полную документацию по функции слияния можно найти здесь .
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в pandas:
pandas.DataFrame.join#
Join columns with other DataFrame either on index or on a key column. Efficiently join multiple DataFrame objects by index at once by passing a list.
Parameters other DataFrame, Series, or a list containing any combination of them
Index should be similar to one of the columns in this one. If a Series is passed, its name attribute must be set, and that will be used as the column name in the resulting joined DataFrame.
on str, list of str, or array-like, optional
Column or index level name(s) in the caller to join on the index in other , otherwise joins index-on-index. If multiple values given, the other DataFrame must have a MultiIndex. Can pass an array as the join key if it is not already contained in the calling DataFrame. Like an Excel VLOOKUP operation.
How to handle the operation of the two objects.
- left: use calling frame’s index (or column if on is specified)
- right: use other ’s index.
- outer: form union of calling frame’s index (or column if on is specified) with other ’s index, and sort it. lexicographically.
- inner: form intersection of calling frame’s index (or column if on is specified) with other ’s index, preserving the order of the calling’s one.
- cross: creates the cartesian product from both frames, preserves the order of the left keys.
Suffix to use from left frame’s overlapping columns.
rsuffix str, default ‘’
Suffix to use from right frame’s overlapping columns.
sort bool, default False
Order result DataFrame lexicographically by the join key. If False, the order of the join key depends on the join type (how keyword).
validate str, optional
If specified, checks if join is of specified type. * “one_to_one” or “1:1”: check if join keys are unique in both left and right datasets. * “one_to_many” or “1:m”: check if join keys are unique in left dataset. * “many_to_one” or “m:1”: check if join keys are unique in right dataset. * “many_to_many” or “m:m”: allowed, but does not result in checks. .. versionadded:: 1.5.0
A dataframe containing columns from both the caller and other .
For column(s)-on-column(s) operations.
Parameters on , lsuffix , and rsuffix are not supported when passing a list of DataFrame objects.
Support for specifying index levels as the on parameter was added in version 0.23.0.
>>> df = pd.DataFrame('key': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'], . 'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']>)
>>> df key A 0 K0 A0 1 K1 A1 2 K2 A2 3 K3 A3 4 K4 A4 5 K5 A5
>>> other = pd.DataFrame('key': ['K0', 'K1', 'K2'], . 'B': ['B0', 'B1', 'B2']>)
>>> other key B 0 K0 B0 1 K1 B1 2 K2 B2
Join DataFrames using their indexes.
>>> df.join(other, lsuffix='_caller', rsuffix='_other') key_caller A key_other B 0 K0 A0 K0 B0 1 K1 A1 K1 B1 2 K2 A2 K2 B2 3 K3 A3 NaN NaN 4 K4 A4 NaN NaN 5 K5 A5 NaN NaN
If we want to join using the key columns, we need to set key to be the index in both df and other . The joined DataFrame will have key as its index.
>>> df.set_index('key').join(other.set_index('key')) A B key K0 A0 B0 K1 A1 B1 K2 A2 B2 K3 A3 NaN K4 A4 NaN K5 A5 NaN
Another option to join using the key columns is to use the on parameter. DataFrame.join always uses other ’s index but we can use any column in df . This method preserves the original DataFrame’s index in the result.
>>> df.join(other.set_index('key'), on='key') key A B 0 K0 A0 B0 1 K1 A1 B1 2 K2 A2 B2 3 K3 A3 NaN 4 K4 A4 NaN 5 K5 A5 NaN
Using non-unique key values shows how they are matched.
>>> df = pd.DataFrame('key': ['K0', 'K1', 'K1', 'K3', 'K0', 'K1'], . 'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']>)
>>> df key A 0 K0 A0 1 K1 A1 2 K1 A2 3 K3 A3 4 K0 A4 5 K1 A5
>>> df.join(other.set_index('key'), on='key', validate='m:1') key A B 0 K0 A0 B0 1 K1 A1 B1 2 K1 A2 B1 3 K3 A3 NaN 4 K0 A4 B0 5 K1 A5 B1