- Как я html-парсер на php писал, и что из этого вышло. Вводная часть
- Введение
- Что должен делать парсер?
- Разделяй и властвуй
- Что там насчет поиска элементов?
- Поиск children элементов
- Поиск текста
- Ошибки
- Script, style и комментарии
- Заключение
- Пример парсинга html-страницы на phpQuery
- Подготовка
- Включение вывода ошибок PHP:
- Локаль:
- Мета-теги
- Заголовок страницы (title)
- Результат:
- Keywords и Description
- Результат:
- Несколько элементов
- Результат:
- Заголовок h1
- Результат:
- Хлебные крошки
- Результат:
- Артикул
- Результат:
- Цены
- Результат:
- Изображения
- Результат:
- Списки dl dd dt
- Результат:
- Списки ul
- Результат:
- Таблицы
- Результат:
- Произвольный контент
- Результат:
Как я html-парсер на php писал, и что из этого вышло. Вводная часть
Сегодня я хочу рассказать, как написать html парсер, а также с какими проблемами я столкнулся, разрабатывая подобный парсер на php. А проблем было много. И в первой части я расскажу о проектировании парсера, и о возникших проблемах, ведь html парсер отличается от парсера привычных всем языков программирования.
Введение
Я старался написать текст этой статьи максимально понятно, чтобы любой, кто даже не знаком с общим устройством парсеров мог понять то, как работает html парсер.
Здесь и далее в статье я буду называть документ, содержащий html просто «Документ».
Dom дерево, находящееся в элементе, будет называться «Подмассив».
Что должен делать парсер?
Давайте сначала определимся, что должен делать парсер, чтобы в будущем отталкиваться от этого при разработке. А именно, парсер должен:
- Проектировать dom-дерево на основе документа
- Если есть ошибки в документе, то он должен их решать
- Находить элементы в dom-дереве
- Находить children элементы
- Находить текст
Впрочем, это мелочи. Основного функционала вполне хватит, чтобы поломать голову пару ночей напролет.
Но тут есть проблема, с которой я столкнулся сразу же: Html — это не просто язык, это язык гипертекста. У такого языка свой синтаксис, и обычный парсер не подойдет.
Разделяй и властвуй
Для начала, нужно разделить работу парсера на два этапа:
Для описания первого этапа я нарисовал схему, которая наглядно показывает, как обрабатываются данные на первом этапе:
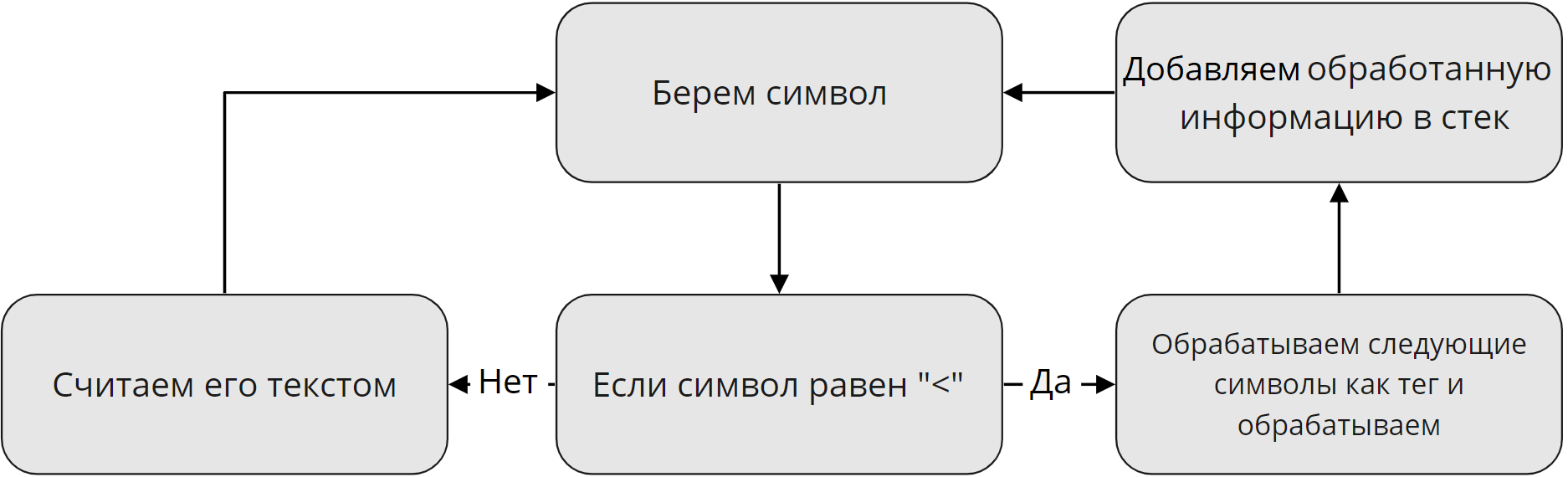
Я решил опустить все мелкие детали. Например, как отличить, что после открывающего »
Также тут стоит уточнить. Логично, что в документе помимо тегов есть еще и текст. Говоря простым языком, если парсер найдет открывающий тег и если в нем будет текст, он запишет его после открывающего тега в виде отдельного тега. Такой тег будет считаться как одиночный и не будет участвовать в дальнейшей работе парсера.
Ну и второй этап. Самый сложный с точки зрения проектирования, и самый простой на первый взгляд с точки зрения понимания:
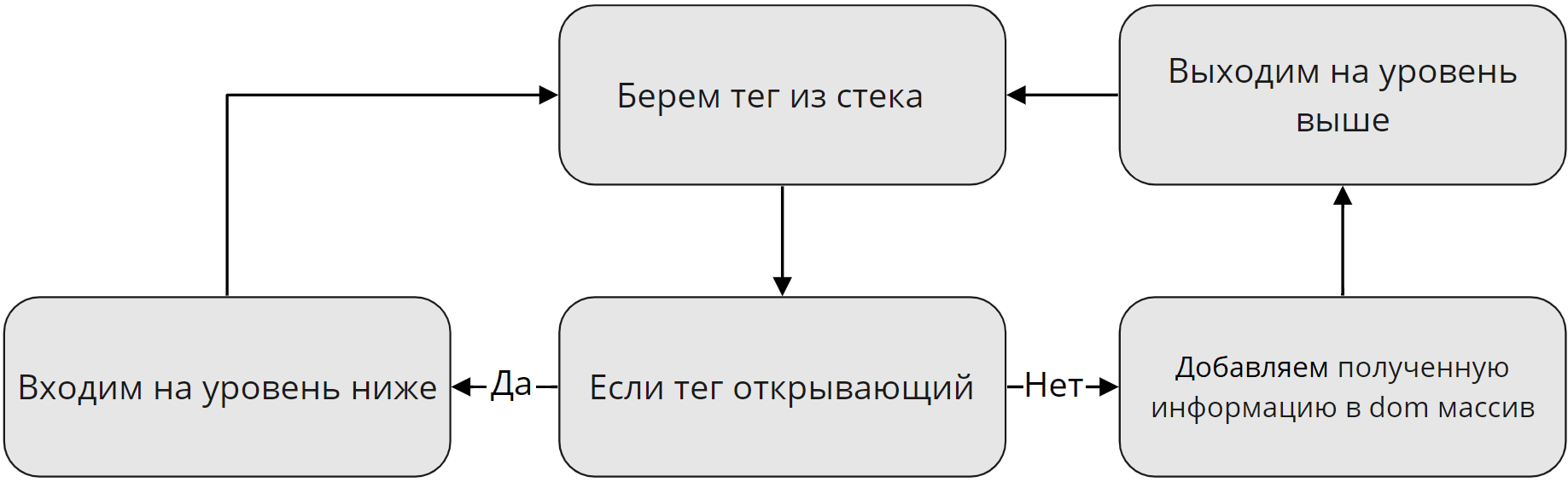
В данном случаи уровень означает уровень рекурсии. То есть если парсер нашел открывающий тег, он вызывает самого себя, «входит на уровень ниже», и так будет продолжаться до тех пор, пока не будет найден закрывающий тег. В этом случаи рекурсия выдает результат, «Выходит на уровень выше». Но, как обстоят дела с одиночными тегами? Такие теги считаются рекурсией ни как открывающие, ни как закрывающие. Они просто переходят в dom «Как есть».
В итоге у нас получится что-то вроде этого:
[0] => Array ( [is_closing] => [is_singleton] => [pointer] => 215 [tag] => div [0] => Array //открывается подмассив ( [0] => Array ( [is_closing] => [is_singleton] => [pointer] => 238 [tag] => div [id] => Array ( [0] => tjojo ) [0] => Array //открывается подмассив ( [0] => Array //Текст записывается в виде отдельного тега ( [tag] => __TEXT [0] => Привет! ) [1] => Array ( [is_closing] => 1 [is_singleton] => [pointer] => 268 [tag] => div ) ) ) ) ) Что там насчет поиска элементов?
А теперь давайте поговорим про поиск элементов. Но тут не все так однозначно, как можно подумать. Сначала стоит разобраться, по каким критериям мы ищем элементы. Тут все просто, мы ищем их по тем же критериям, как это делает Javascript: теги, классы и идентификаторы. Но тут проблема. Дело в том, что тег может быть только один, а вот классов и идентификаторов у одного элемента — множество, либо вообще не быть. Поэтому, поиск элемента по тегу будет отличаться от поиска по классу или идентификатору. Я нарисовал схему поиска по тегу, но не волнуйтесь: поиск по классу или идентификатору не особо отличаются.
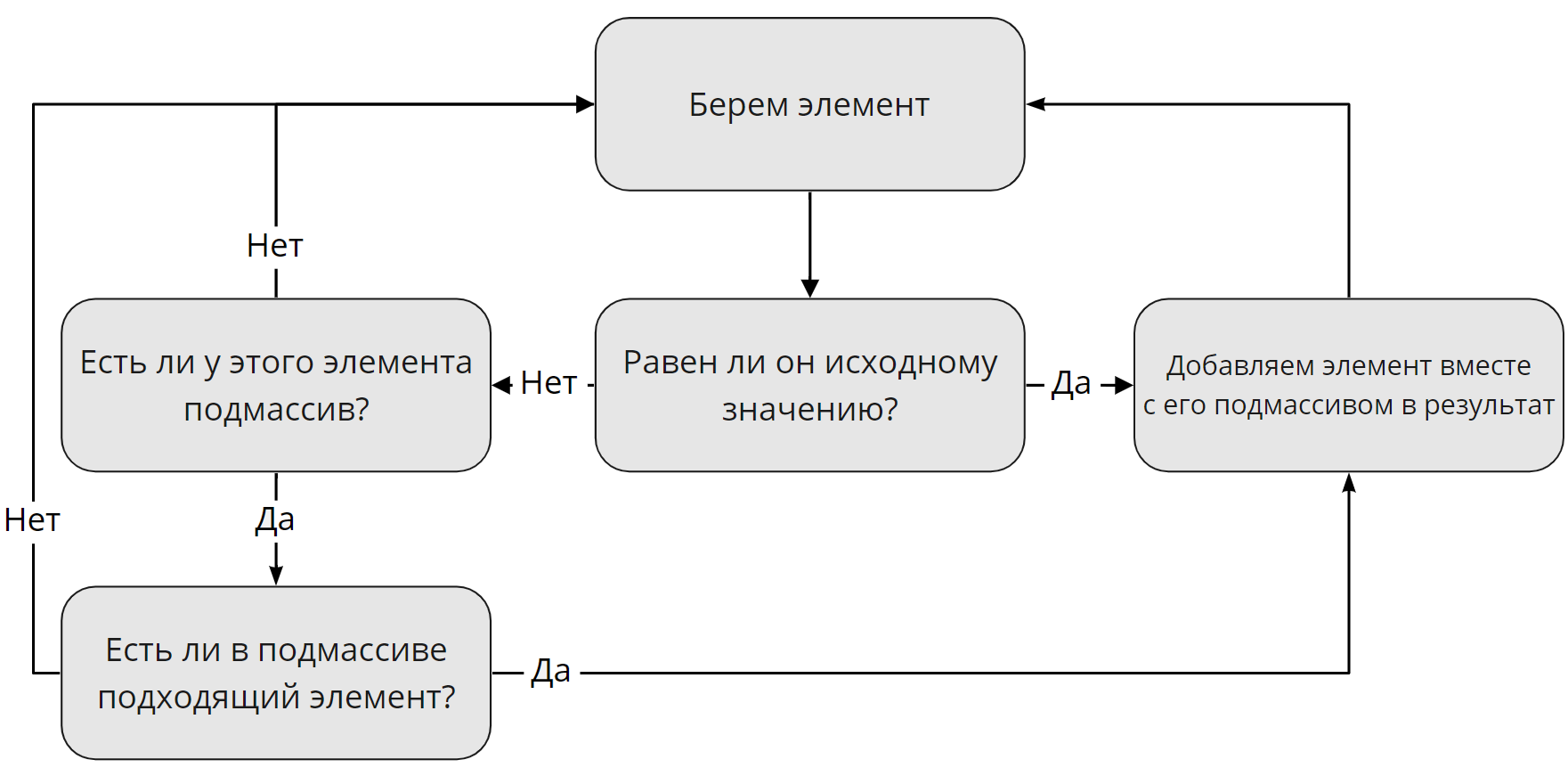
Немного уточнений. Под исходным значением я имел в виду название тега, «div» например. Также, если элемент не равен исходному значению, но у него есть подмассив с подходящим элементом, в результат запишется именно подходящий элемент с его подмассивом, если таковой существует.
Стоит также сказать, что у парсера будет функция, позволяющая искать определенный элемент в документе. Это заметно ускорит производительность парсера, что позволит ему выполняться быстрее. Можно будет, например, взять только первый найденный элемент, или пятый, как вы захотите. Согласитесь, в таком случаи парсеру будет гораздо проще искать элементы.
Поиск children элементов
Хорошо, с поиском элементов разобрались, а как насчет children элементов? Тут тоже все просто: наш парсер будет брать все вложенные подмассивы найденных до этого элементов, если таковые существуют. Если таковых нет, парсер выведет пустой результат и пойдет дальше:
![]()
Поиск текста
Тут говорить особо не о чем. Парсер просто будет брать весь полученный текст из подмассива и выводить его.
Ошибки
Документ может содержать ошибки, с которыми наш скрипт должен успешно справляться, либо, если ошибка критическая, выводить ее на экран. Тут будет приведен список всех возможных ошибок, о которых, в будущем, мы будем говорить:
- Символ «>» не был найден
Такая ошибка будет возникать в том случаи, если парсер дошел до конца документа и не нашел закрывающего символа «>». - Неизвестное значение атрибута
Данная ошибка сигнализирует о том, что была проведена попытка передачи значения атрибуту когда закрывающий тег был найден.
Script, style и комментарии
В парсере теги script и style будут сразу же пропускаться, поскольку я не вижу смысл их записывать. С комментариями ситуация другая. Если вы захотите из записывать, то вы сможете включить отдельную функцию скрипта, и тогда он будет их записывать. Комментарии будут записываться точно так же как и текст, то есть как отдельный тег.
Заключение
Эту статью скорее нужно считать небольшим экскурсом в тему парсеров html. Я ее написал для тех, кто задумывается над написанием своего парсера, либо для тех, кому просто интересно. Поверьте, это действительно весело!
Данная статья является первой вводной частью. В следующих частях этого цикла уже будет участвовать непосредственно код, и будет меньше картинок с алгоритмами(что прекрасно, потому что рисовать я их не умею). Stay tuned!
Пример парсинга html-страницы на phpQuery
phpQuery – это удобный HTML парсер взявший за основу селекторы, фильтры и методы jQuery, которые позволяют манипулировать элементами HTML/XML и получать их содержимое.
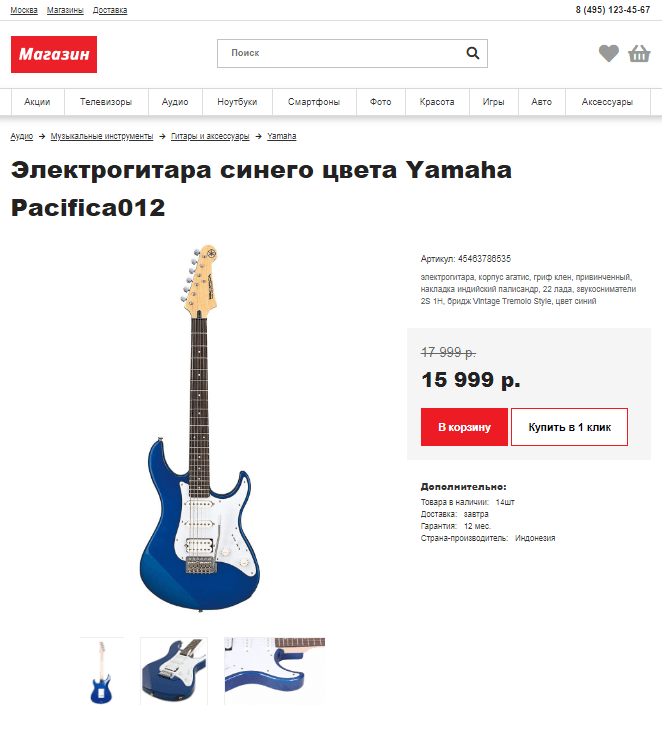
В примерах используется страница карточки товара https://snipp.ru/demo/76/index.html, все спарсенные данные помещаются в общий массив $data .
Подготовка
Включение вывода ошибок PHP:
error_reporting(E_ALL); ini_set('display_errors', 1);Локаль:
setlocale(LC_ALL, 'ru_RU'); date_default_timezone_set('Europe/Moscow'); header('Content-type: text/html; charset=utf-8');include_once __DIR__ . '/phpQuery.php'; $doc = phpQuery::newDocument(file_get_contents('https://snipp.ru/demo/76/index.html'));Если кодировка сайта-донора отличается от вашей, возможно в спарсенных данных кириллица будет иероглифами. В таком случаи потребуется перекодировка, например:
$html = file_get_contents('https://snipp.ru/demo/76/index.html'); $html = iconv('utf-8//IGNORE', 'windows-1251//IGNORE', $html); include_once __DIR__ . '/phpQuery.php'; $doc = phpQuery::newDocument($html);Подробнее в статье «Перекодировка текста UTF-8 и WINDOWS-1251». Ещё бывают случаи, когда file_get_contents возвращает полученный контент сжатый в GZIP, например: �mw�Ƒ0�����&IkAI��f��j4/
function getcontents($url) < $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); curl_setopt($ch, CURLOPT_ENCODING, 'gzip'); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 0); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, 0); $output = curl_exec($ch); curl_close($ch); return $output; >include_once __DIR__ . '/phpQuery.php'; $doc = phpQuery::newDocument(getcontents('https://snipp.ru/demo/76/index.html'));Мета-теги

Заголовок страницы (title)
Метод find(‘selector’) находит элементы по селектору, далее вызывается функция pq() , которая возвращает объект найденного элемента (подобно $ в jquery). К этому объекту можно применить методы, например text() – получить текстовое содержимое элемента.
$entry = $doc->find('title'); $data['title'] = pq($entry)->text(); echo $data['title'];Результат:
Пример магазина - Электрогитара синего цвета Yamaha Pacifica012Keywords и Description
$entry = $doc->find('head meta[name="keywords"]'); $data['keywords'] = pq($entry)->attr('content'); echo $data['keywords']; $entry = $doc->find('head meta[name="description"]'); $data['description'] = pq($entry)->attr('content'); echo $data['description'];Результат:
Электрогитара,Yamaha,Pacifica012 Интернет-магазин цифровой и бытовой техникиНесколько элементов
$data['css'] = array(); $entry = $doc->find('head link[rel="stylesheet"]'); foreach ($entry as $row) < $data['css'][] = pq($row)->attr('href'); > print_r($data['css']);Результат:
Array ( [0] => style.css [1] => https://snipp.ru/cdn/fontawesome/5.11.2/css/all.css )Заголовок h1

$entry = $doc->find('h1'); $data['h1'] = pq($entry)->text(); echo $data['h1'];Результат:
Электрогитара синего цвета Yamaha Pacifica012Хлебные крошки

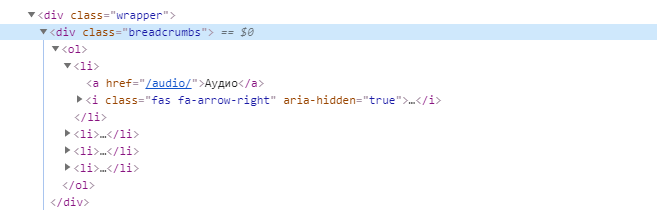
$data['breadcrumbs'] = array(); $entry = $doc->find('.breadcrumbs li a'); foreach ($entry as $row) < $ent = pq($row); $name = $ent->text(); $url = $ent->attr('href'); $data['breadcrumbs'][$name] = $url; > print_r($data['breadcrumbs']);Результат:
Array ( [Аудио] => /audio/ [Музыкальные инструменты] => /audio/instruments/ [Гитары и аксессуары] => /audio/instruments/guitar/ [Yamaha] => /audio/instruments/guitar/yamaha )Артикул


В данном случаи нужно только значение, c помощью метода remove() удаляется элемент с текстом «Артикул».
$entry = $doc->find('.prod .prod-sku'); $entry->find('span')->remove(); $data['sku'] = trim(pq($entry)->text()); echo $data['sku'];Результат:
Цены
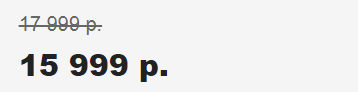

Цены выводятся с форматированием, его можно удалить регулярным выражением и привести значение к типу float или сразу применить PHP-функцию clean_price().
/* Старая цена - strike */ $entry = $doc->find('.price-price strike'); $val = pq($entry)->text(); $data['price_old'] = floatval(mb_ereg_replace('[^0-9.,]', '', $val)); var_dump($data['price_old']); /* Старая цена - span */ $entry = $doc->find('.price-price span'); $val = pq($entry)->text(); $data['price'] = floatval(mb_ereg_replace('[^0-9.,]', '', $val)); var_dump($data['price']);Результат:
Изображения
Для оптимизации скорости, фото товаров в тегах уменьшают и оборачивают их ссылками на оригинальные изображения.

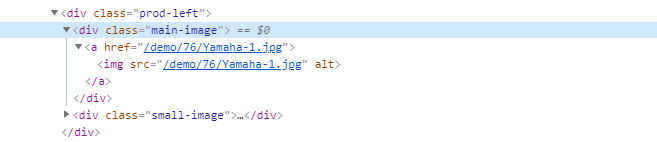
$data['images'] = array(); $entry = $doc->find('.prod-left img'); foreach ($entry as $row) < $link = pq($row)->parents('a'); $data['images'][] = pq($link)->attr('href'); > print_r($data['images']);Результат:
Array ( [0] => /demo/76/Yamaha-1.jpg [1] => /demo/76/Yamaha-2.jpg [2] => /demo/76/Yamaha-3.jpg [3] => /demo/76/Yamaha-4.jpg )Списки dl dd dt

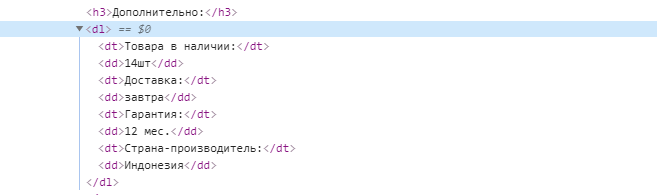
Сложность парсинга списков определений заключается в том, что у нескольких
/* dt */ $dt = array(); $entry = $doc->find('dl dt'); foreach ($entry as $row) < $dt[] = trim(pq($row)->text(), ':'); > /* dl */ $dd = array(); $entry = $doc->find('dl dd'); foreach ($entry as $row) < $dd[] = pq($row)->text(); > $data['attrs'] = array_combine($dt, $dd); print_r($data['attrs']);Результат:
Array ( [Товара в наличии] => 14шт [Доставка] => завтра [Гарантия] => 12 мес. [Страна-производитель] => Индонезия )Списки ul

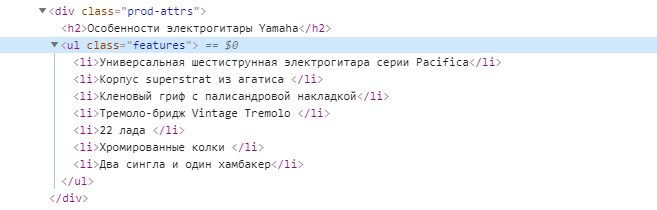
$data['list'] = array(); $entry = $doc->find('ul.features li'); foreach ($entry as $row) < $data['list'][] = pq($row)->text(); > print_r($data['list']);Результат:
Array ( [0] => Универсальная шестиструнная электрогитара серии Pacifica [1] => Корпус superstrat из агатиса [2] => Кленовый гриф с палисандровой накладкой [3] => Тремоло-бридж Vintage Tremolo [4] => 22 лада [5] => Хромированные колки [6] => Два сингла и один хамбакер )Таблицы
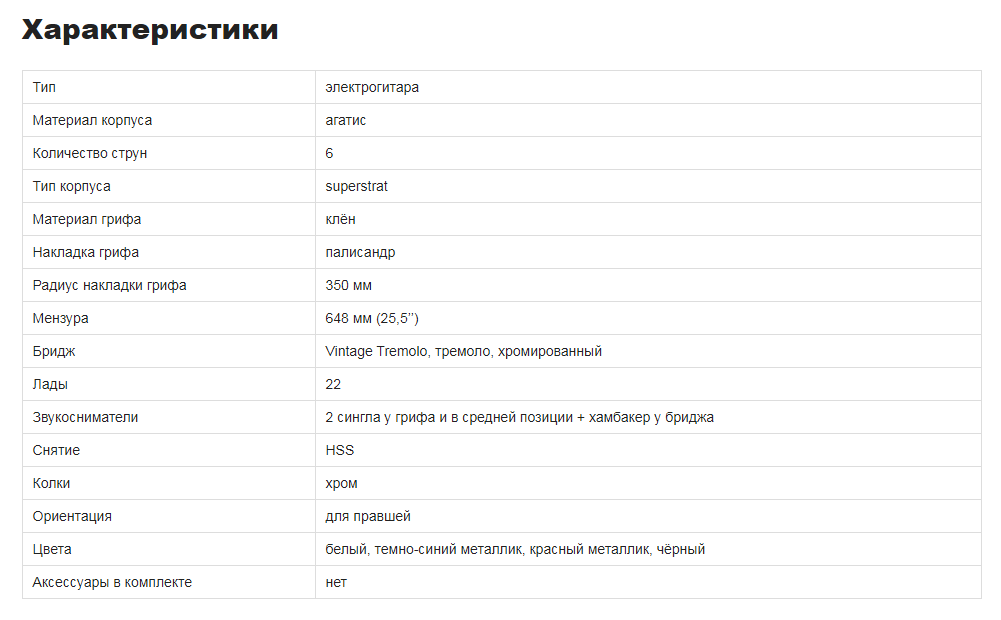
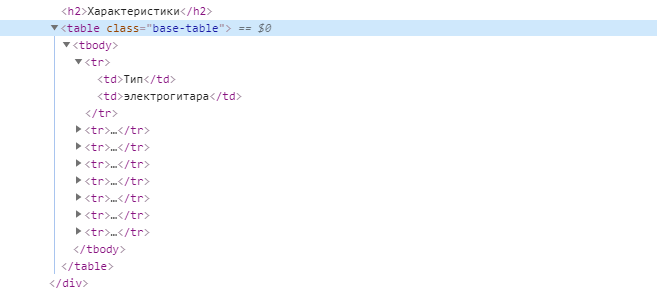
Найдем все
$data['table'] = array(); $entry = $doc->find('table.base-table tr'); foreach ($entry as $row) < $row = pq($row); $name = $row->find('td:eq(0)')->text(); $value = $row->find('td:eq(1)')->text(); $data['table'][$name] = $value; > print_r($data['table']);Результат:
Array ( [Тип] => электрогитара [Материал корпуса] => агатис [Количество струн] => 6 [Тип корпуса] => superstrat [Материал грифа] => клён [Накладка грифа] => палисандр [Радиус накладки грифа] => 350 мм [Мензура] => 648 мм (25,5’’) [Бридж] => Vintage Tremolo, тремоло, хромированный [Лады] => 22 [Звукосниматели] => 2 сингла у грифа и в средней позиции + хамбакер у бриджа [Снятие] => HSS [Колки] => хром [Ориентация] => для правшей [Цвета] => белый, темно-синий металлик, красный металлик, чёрный [Аксессуары в комплекте] => нет )Произвольный контент


Найдем
$entry = $doc->find('div.text'); $entry->find('h2')->remove(); $data['text'] = pq($entry)->html(); echo $data['text'];Результат:
Разработанная на основе модели Pacifica 112, новая, еще более доступная по цене модель 012 характеризуется аналогичными контурами корпуса, мощным хамбакером в бриджевой позиции и 2 синглами, обеспечивающими чистое звучание. Гитара оснащена удобным грифом, 5-позиционным переключателем выбора звукоснимателей и тремоло типа Vintage.
Корпус: агатис. Гриф: привинченный, клен. Накладка грифа: сонокелинг, радиус 350 мм. Лады: 22. Мензура: 648 мм. Звукосниматель: 2 сингла, 1 хамбакер. Регуляторы: 5-позиционный переключатель звукоснимателей, мастер-громкость, тембр. Бридж: тремоло типа Vintage.