- Введение в работу с библиотекой Requests в Python
- Как установить библиотеку Requests в Python
- Первые запросы
- HTTP-запросы
- GET
- POST
- OPTIONS
- HEAD
- PUT
- PATCH
- DELETE
- Объект Response
- Заключение
- Работа с библиотекой requests Python
- Установка библиотеки requests
- Установить requests через cmd
- Установить requests через терминал Pycharm
- Установить requests через меню Pycharm
- Работа с библиотекой requests Python – post запросы
- Получаем данные – работа с библиотекой requests python
Введение в работу с библиотекой Requests в Python
Requests — это одна из библиотек, которая поможет вам подружить ваш локальный скрипт с веб-ресурсами и глобальной сетью. Requests предоставляет разработчику обширный пул функций для работы со всеми видами HTTP-запросов. Благодаря этой библиотеке вы сможете получить прогноз погоду, перевести текст, скачать фильм или фото без использования браузера внутри скрипта.
В этом материале вы найдете вводную информацию по этой библиотеке, которой будет достаточно для её использования в ваших скриптах.
Как установить библиотеку Requests в Python
В рамках всего материала речь будет идти про работу в IDE Pycharm.
Библиотека Requests в Python является сторонней, поэтому перед началом работы её необходимо установить. Создаем проект и открываем терминал. В Python установка библиотеки Requests осуществляется следующей командой:
Если вы используете виртуальную среду Pipenv, то установка библиотеки Requests в Python 3 производится другой командой:
После исполнения этих команд начнется загрузка модуля. С помощью команды pip freeze можем узнать, какие модули были установлены:
PS C:\Users\Timeweb\PycharmProjects\RequestTimeweb> pip3 freeze
certifi==2022.9.24
charset-normalizer==2.1.1
idna==3.4
requests==2.28.1
urllib3==1.26.12Расскажем, какие функции выполняют эти модули:
- certifi — пакет сертификатов для обеспечения безопасного соединения;
- charset-normalizer — библиотека, которая автоматически распознает тексты неизвестной кодировки. Полезный модуль, поскольку не все сайты и сервисы работают на распространенной UTF-8;
- idna — библиотека для поддержки интернационализированных доменных имен в приложениях;
- requests — собственно, сам модуль request;
- urllib3 — модуль, включающий в себя функции и классы для работы с URL-адресами;
Первые запросы
В этой части статьи мы напишем код для получения информации с ресурсов и узнаем основные составляющие библиотеки Request. В дальнейшем мы более детально разберем все аспекты.
Работа с библиотекой Requests в Python начинается с импорта:
Обратимся к сайту google.com:
import requests as rq
response = rq.get('https://google.com')
print(response)Здесь мы используем HTTP-запрос GET. Его работа аналогична переходу на сайт по URL в браузере. Далее мы подробнее разберем его.
В ответ мы получили объект Response. У него огромное количество различных свойств, которые мы также разберем дальше. При выводе этого объекта мы получаем код 200 — он означает, что запрос выполнен успешно. Если мы обратимся к несуществующему разделу на сайте google.com, то получим ответ об его отсутствии:
import requests as rq
response = rq.get('https://google.com/timeweb')
print(response)Теперь разберем, какие вообще существуют запросы и как с ними работать.
HTTP-запросы
Основным запросом к сервисам и сайтам является GET. Он позволяет просматривать содержимое ресурса без его изменения. Однако для полноценной работы с ресурсами в сети может понадобится ряд других запросов. Некоторые из них могут не поддерживаться со стороны того или иного сервера. Вот 7 запросов, которые поддерживает библиотека Request:
Для тестирования библиотеки создатели спроектировали сайт https://httpbin.org , с помощью которого вы можете попрактиковаться.
GET
GET передает информацию сайту прямо в заголовке. Поэтому его стоит использовать в случаях, когда передаваемая информация не является чем-то ценным: например, поиск некоторой страницы в интернет-магазине. Его не стоит использовать для передачи паролей, банковский карт и подобных данных.
Для передачи данных серверу к его URL-адресу добавляется знак ?, затем идут сами данные. Выглядит это следующим образом:
https://serverurl.ru/get?param1=value1¶m2=value2- https://serverurl.ru/get — это URL;
- param1=value1¶m2=value2 — параметры. Если параметров несколько, то они отделяются амперсандом «&».
В Request GET имеет следующий синтаксис:
request.get( 'URL-адрес', , различные аргументы)- URL-адрес — адрес ресурса;
- — параметры. Метод самостоятельно включит их в запрос. Необязательный аргумент метода;
- Различные аргументы — необязательные аргументы. Например, время таймаута.
import requests as rq
GetParams =
response = rq.get('https://google.com', GetParams)
print(response.url)https://www.google.com/?param1=value1¶m2=value2POST
POST используется для отправки данных на сайт в теле запроса. Тело запроса — это данные, передающиеся при совершении запроса к ресурсу. Эта информация не размещается в заголовке и подходят для передачи конфиденциальных данных.
В Request POST имеет следующий синтаксис:
request.post('URL-адрес', , различные аргументы>- URL-адрес — адрес ресурса;
- — параметры. Метод самостоятельно включит их в тело запроса. Необязательный аргумент метода;
- Различные аргументы — необязательные аргументы. Например, время таймаута.
Если не указать параметры, то GET и POST запросы вернут одинаковый результат для одного URL. Посмотрим, как работает это на практике:
import requests as rq
PostParams =
response = rq.post('https://httpbin.org/post', PostParams, timeout=2)
print(response.json()['form'])С помощью метода json() мы получили тело запроса из response. К слову, если бы мы совершили аналогичный запрос к google.com, то получили бы ошибку:
import requests as rq
PostParams =
response = rq.post('https://google.com', PostParams, timeout=2)
print(response)Ошибка 405 (Method Not Allowed) означает, что ресурс не поддерживает такой запрос.
Для того, чтобы узнать какие запросы поддерживает ресурс необходимо использовать OPTIONS.
OPTIONS
С помощью OPTIONS мы можем узнать, какие запросы не будут заблокированы ресурсом.
request.option('URL-адрес', необязательные аргументы)Отправим OPTIONS-запрос к google.com и узнаем, какие запросы он поддерживает:
import requests as rq
response = rq.options('https://google.com', timeout=2)
print(response.headers['Allow'])HEAD
В ответ на HEAD сервер вернет HTTP заголовки. Этот запрос выполняется, когда нужно получить не содержимое файла, а другие данные. Также HEAD может выполнять тестовые функции.
request.head('URL-адрес', различные аргументы)- URL-адрес — адрес ресурса;
- Различные аргументы — необязательные аргументы. Например, время таймаута.
import requests as rq
response = rq.head('https://google.com', timeout=2)
print(response.headers)В выводе мы получили большое количество заголовков.
PUT
PUT создает новый объект или заменяет существующий. Он похож на метод POST, но отличается идемпотентностью. Это означает, что при повторных выполнениях PUT с аналогичными данными результат не изменится.
Для лучшего понимания представим базу данных с паролями и логинами. Допустим пользователь хочет поменять пароль. При использовании метода POST он добавит новую запись со своим идентификатором, в данном случае логином (при отсутствии других программных проверок). При использовании PUT он обновит текущий.
request.put('URL-адрес', , различные аргументы)- URL-адрес — адрес ресурса;
- — параметры. Метод самостоятельно включит их в тело запроса.
- Различные аргументы — необязательные аргументы. Например, время таймаута.
import requests as rq
PutParams =
response = rq.put('https://httpbin.org/put', data=PutParams, timeout=2)
print(response.status_code)PATCH
С помощью PATCH осуществляется частичное обновление данных на ресурсе (например, смена токена). Синтаксис следующий:
request.patch ('URL-адрес', , различные аргументы)- URL-адрес — адрес ресурса;
- — параметры. Метод самостоятельно включит их в тело запроса.
- Различные аргументы — необязательные аргументы. Например, время таймаута.
import requests as rq
PatchParams =
response = rq.patch('https://httpbin.org/patch', data=PatchParams, timeout=2)
print(response.status_code)DELETE
Используется для удаления некого объекта на ресурсе. Синтаксис:
- URL-адрес — адрес ресурса;
- — параметры (данные, которые необходимо удалить). Метод самостоятельно включит их в тело запроса.
import requests as rq
DelParams =
response = rq.delete('https://httpbin.org/delete', data=DelParams, timeout=2)
print(response.status_code)Объект Response
Как было показано в примерах, объект Response обладает большим количеством методов и свойств. Ниже вы найдете их с кратким описанием:
- apparent_encoding — кодировка, распознанная charset-normalizer;
- close() — закрывает соединение с сервером;
- content — вывод полученных данных в байтах;
- cookies — вывод куки;
- elapsed — вывод времени;
- encoding — выбор кодировки для декодирования;
- headers — вывод заголовков ресурса;
- history — вывод переадресации;
- is_permanent_redirect — определение постоянных редиректов;
- is_redirect — определение наличия редиректа;
- iter_content() — возврат данных по частям;
- iter_lines() — возврат данных построчно;
- json() — возврат данных в формате JSON;
- links — возврат ссылок в заголовках ответа;
- next — возврат PreparedRequest;
- ok — True при удачном соединении, False при неудачном;
- raise_for_status() — вызов исключения HTTPError;
- reason — вывод текстового представления объекта;
- request — возврат результат PreparedRequest;
- status_code — код ответа;
- text — вывод ответа в юникоде;
- url — вывод URL.
Заключение
В рамках этого материала мы рассмотрели основные элементы библиотеки Requests. Если вы хотите узнать о ней больше, то официальная документация библиотеки Requests Python даст вам необходимые ответы. А для тестирования своих скриптов можно использовать облачные серверы от timeweb.cloud.
Работа с библиотекой requests Python
Если быстро и в двух словах, то в большинстве случаев работа с библиотекой requests Python это и есть работа с сайтами. С помощью этой библиотеки мы создаем различные запросы и получаем ответы.
Установка библиотеки requests
Здесь просто, устанавливается она без особых проблем, либо через командную строку, либо через терминал PyCharm, либо через пункты меню в Pycharm.
Установить requests через cmd
Открываем дирректорию в которой находится наш проект, и прописываем команду:
Установить requests через терминал Pycharm
Здесь тоже все очень просто: открываем терминал в Pycharm, и тоже прописываем
P.S. Если вам необходимо обновить pip, хотя работа с библиотекой requests Python возможна и без обновления pip, необходимо как и сомандной строке Windows, так и в терминале прописать одну и ту же команду:
python -m pip install --upgrade pip
Установить requests через меню Pycharm
File – Settings – Project: (имя проекта) – Python Interpreter – “+” (Install) – в поиске пишем requests – Нажимаем кнопку “Install Package”.
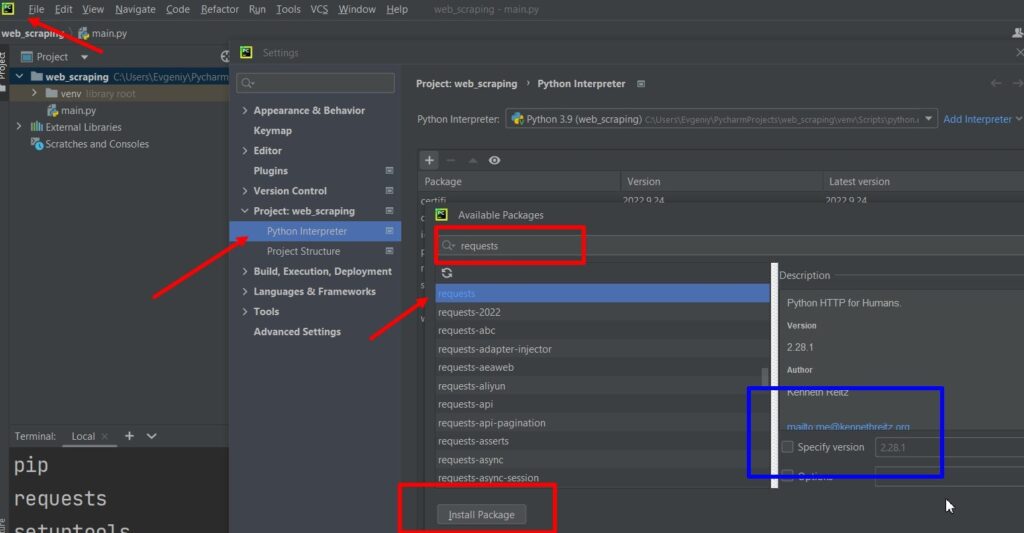
P.S. Если вам нужна какая-то конкретная версия библиотеки requests, то укажите ее – выделил синим квадратом это поле.
Итак, думаю с этим проблем не должно возникнуть, если будут вопросы, пишите в комментариях. Документация по библиотеке requests находится здесь а также здесь.
Работа с библиотекой requests Python – post запросы
Для того, что бы отправить запрос и получить ответ, нам нужен сайт, с которым мы и будем работать! В качестве “подопытного кролика” будем использовать Google.
Я люблю записывать доменное имя в переменную, хотя это не обязательно делать, после чего вызываем модуль requests и его метод get():
import requests url = 'https://google.com' response = requests.get(url) print(response)
И после запуска программы, если наша “жертва” работает нормально, сервер нам даст ответ:
Здесь нас интересует цифра [200] – значит сервер работает и отвечает.
А если применить к нашему объекту response еще и метод status_code, то в консоле и вовсе выведется просто число – ответ сервера, в нашем случае – 200
import requests url = 'https://google.com' response = requests.get(url) print(response.status_code) # 200
Получаем данные – работа с библиотекой requests python
Для того, что бы получить нашу страничку в побитовом виде, возможно вам так и нужно ее видеть, используется метод content.
print(response.content) # 200
На много чаще нам необходимо получать нашу страничку в формате html, для этого используется метод text:
Если нам необходимо получить все заголовки, мы используем метод headers
import requests url = 'https://google.com' response = requests.get(url) print(response.headers)
Если необходимо установить заголовки в HTTP запросе, передайте словарь с ними в параметр headers. Значения заголовка должны быть типа string, bytestring или unicode. Имена заголовков не чувствительны к регистру символов.
В следующем примере мы устанавливаем информацию об используемом браузере:
response = requests.get(url, headers=) print(response.request.headers)