- Отладка HTML
- Отладка — это не страшно
- HTML и отладка
- Толерантный код
- Активное обучение: Знакомство с толерантным кодом
- Валидация HTML
- Активное обучение: Валидируем HTML-документ
- Работа с сообщениями об ошибках
- Заключение
- В этом модуле
- Found a content problem with this page?
- Редактор HTML в вашем браузере
- Как открыть средства разработки?
- Редактирование статических HTML страниц в браузере
- Установка и пример использования:
Отладка HTML
Написать HTML — здорово, но как понять, где ошибка, когда что-то не работает? В этой статье описаны несколько инструментов, которые помогают искать и исправлять ошибки в HTML.
| Что нужно знать: | Базовые знания HTML на уровне Начало работы с HTML, Основы редактирования текста в HTML, и Создание гиперссылок. |
|---|---|
| Чему вы научитесь: | Искать проблемы в HTML с помощью инструментов отладки. |
Отладка — это не страшно
Во время написания какого-нибудь кода, обычно все идёт хорошо, пока не появляется тот момент, когда вы совершаете ошибку. Итак, ваш код не работает, или работает не так, как вы задумывали. Если вы попытаетесь скомпилировать неработающую программу на языке Rust, компилятор укажет на ошибку:
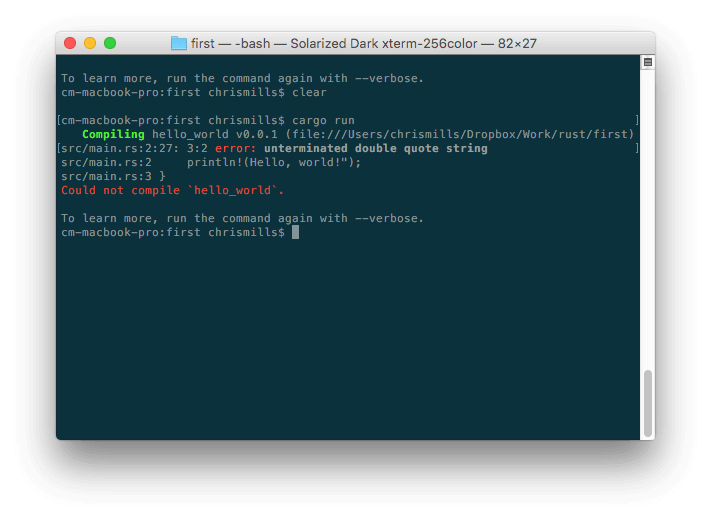
В данном случае, сообщение об ошибке понять относительно просто — «unterminated double quote string». Если вы внимательно посмотрите на println!(Hello, world!»); , то заметите, что здесь отсутствует двойная кавычка. Разумеется, сообщения об ошибках могут становиться куда более сложными для понимания по мере роста вашего кода, и даже самые простые случаи могут показаться пугающими для тех, кто ничего не знает о Rust.
Но не бойтесь отладки! Чтобы комфортно писать и отлаживать любой код, нужно понимать язык и его инструменты.
HTML и отладка
HTML не так сложен к пониманию, как Rust. HTML не компилируется в какую-либо другую форму перед тем, как браузер проанализирует это и покажет результат (он является интерпретируемым, а не компилируемым). Синтаксис HTML элементов намного понятнее, чем у «настоящих языков программирования», таких как Rust, JavaScript, или Python (en-US). Способ, которым браузеры читают HTML более толерантен, чем у языков программирования, интерпретирующих свой код строже. Это одновременно и плохо, и хорошо.
Толерантный код
Так что же означает толерантный? В общих чертах, когда вы напортачили в коде, есть два типа ошибок, с которыми вы столкнётесь:
- Синтаксические ошибки (Syntax errors): Это ошибки в правильности написания, как это было выше, в примере с Rust. Такие обычно легко исправлять, в той мере, в какой вы знакомы с синтаксисом языка и знаете, что означают сообщения об ошибках.
- Логические ошибки (Logic errors): Это ошибки, появляющиеся в том случае, если синтаксис корректен, но код не выполняет своего предназначения, то есть программа выполняется неверно. Такие исправлять сложнее, чем синтаксические, поскольку не выводится сообщений, указывающих место, где вы ошиблись.
HTML не страдает от синтаксических ошибок, потому что браузер читает код толерантно, в том смысле, что страницы могут отображаться даже если синтаксические ошибки присутствуют. Браузеры имеют встроенные правила по интерпретации неверно написанной разметки, и вы можете запустить что-либо, даже если вы имели в виду другое. Это может стать настоящей проблемой!
Примечание: HTML читается толерантно, потому что когда веб только появился, было решено позволить людям публиковать контент даже при условии некорректностей в коде, так как это куда более важно, чем уверенность в абсолютно верном синтаксисе. Веб не был бы сейчас так популярен, если бы относился к новичкам строго.
Активное обучение: Знакомство с толерантным кодом
Время изучить природу толерантного кода в HTML.
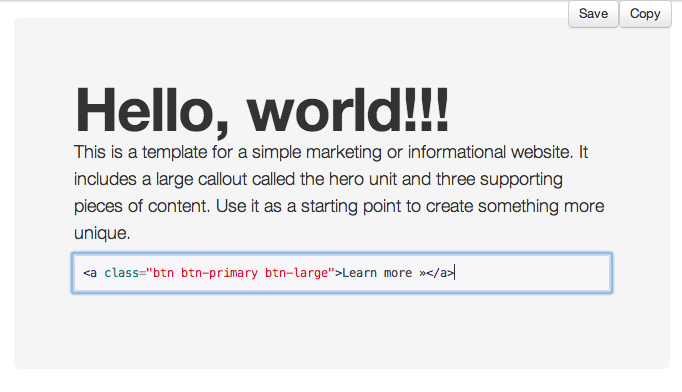
- Для начала, скачайте наш пример отладки и сохраните локально. Эта демонстрация намеренно написана с ошибками, которые нам предстоит обнаружить.
- Далее, откройте её в браузере. Вы увидите нечто вроде этого :
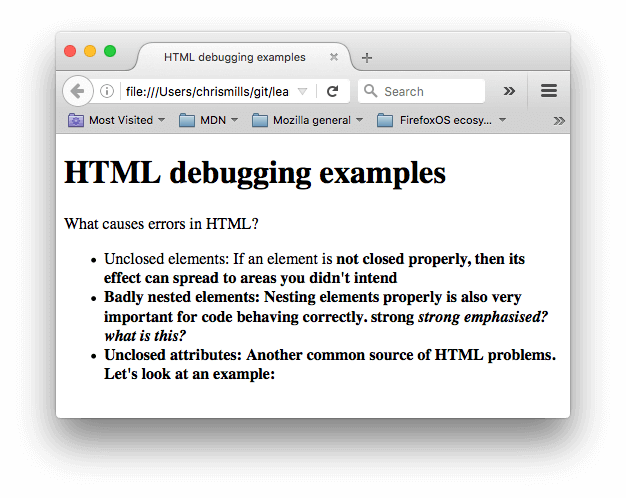
- Сейчас документ выглядит не особо хорошо; Давайте посмотрим в код и выясним почему (Показано только тело документа):
h1>HTML debugging examplesh1> p>What causes errors in HTML? ul> li>Unclosed elements: If an element is strong>not closed properly, then its effect can spread to areas you didn't intend li>Badly nested elements: Nesting elements properly is also very important for code behaving correctly. strong>strong em>strong emphasised?strong> what is this?em> li>Unclosed attributes: Another common source of HTML problems. Let's look at an example: a> ul>
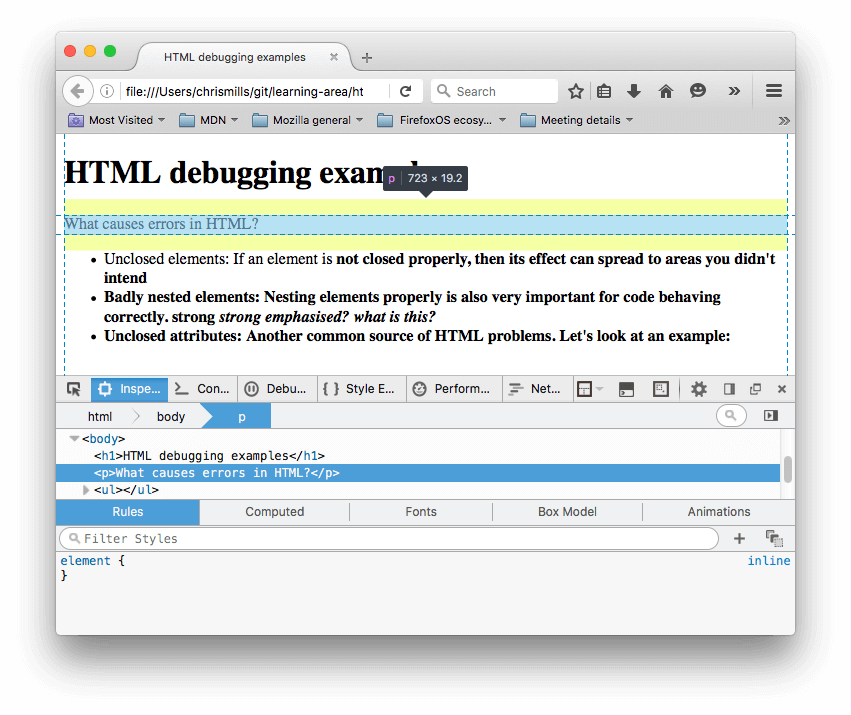
- У параграфа и элемента списка не закрыты теги. На изображении выше видно, что разметка не пострадала, так как браузеру легко сделать вывод о том, где заканчивается один элемент и начинается другой.
- Первый элемент также не имеет закрывающего тега. Это уже более проблематично, так как сложно сказать, где элемент должен заканчиваться. На деле, весь оставшийся текст был выделен жирным.
- Следующая часть нарушает правила вложенности: strong strong emphasised? what is this? . В этом случае код тоже сложно проинтерпретировать по причине, описанной выше.
- В атрибуте href отсутствует закрывающая двойная кавычка. Это послужило причиной крупной проблемы — ссылка не воспроизвелась вовсе.
- Параграфы и элементы списка получены с закрывающими тегами.
- Было неочевидно, где элемент должен был закрыться, так что браузер обернул каждый отдельный блок текста своими собственными тегами strong, причём до самого низа документа!
- Некорректная вложенность была исправлена браузером следующим образом:
strong>strong em>strong emphasised?em> strong> em> what is this?em>
li> strong>Unclosed attributes: Another common source of HTML problems. Let's look at an example: strong> li>
Валидация HTML
Из примера выше ясно, что стоит проверять валидность HTML. В простом примере сверху можно просто просмотреть весь код и найти ошибки, но как быть с огромными, сложными страницами?
Лучше всего проверить страницу в сервисе валидации разметки. Его создал и поддерживает W3C — организация, которая занимается спецификациями HTML, CSS и других веб-технологий. Сервис проверит ваш HTML и составит отчёт по ошибкам в нем.

HTML можно проверить по адресу, загрузив файл или напрямую ввести код HTML.
Активное обучение: Валидируем HTML-документ
- Откройте сервис валидации разметки в браузере.
- Перейдите в режим Validate by Direct Input.
- Скопируйте весь код документа (не только body) и вставьте в место для ввода.
- Нажмите на Check (проверить).
Вы увидите список ошибок и другую информацию.

Работа с сообщениями об ошибках
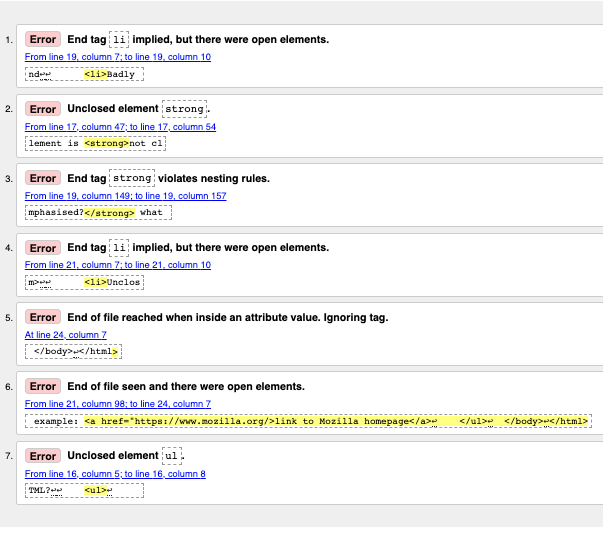
Обычно сразу ясно, что значат сообщения, но иногда приходится постараться, чтобы понять, в чем дело. Сейчас мы пройдёмся по всем ошибкам и разберём, что они значат. Обратите внимание, что в сообщениях указаны строка и столбец кода, чтобы ошибки было проще искать.
Если некоторые ошибки кажутся вам странными, начните исправление с остальных и проверьте документ ещё раз. Иногда одна ошибка ломает большую часть документа.
Когда вы увидите эту надпись, в вашем документе больше нет ошибок:

Заключение
Теперь вы умеете отлаживать HTML. С новыми знаниями вам будет проще разобраться и в отладке более сложных языков — например, CSS и JavaScript. На этом мы заканчиваем вводный модуль курса HTML — время попробовать свои силы в упражнениях.
В этом модуле
Found a content problem with this page?
This page was last modified on 21 июн. 2023 г. by MDN contributors.
Your blueprint for a better internet.
Редактор HTML в вашем браузере
В большинстве браузеров есть инструменты разработчика. Простейший из которых — это редактор HTML кода. Попробуем найти, где он находится и отредактировать HTML код на задаче. Допустим, что мы разрабатываем сайт и хотим чуть-чуть изменить дизайн. Для этого можно постоянно менять HTML файл страницы и перезагружать её, но в таком случае разработка будет длиться довольно долго. Нам же надо изменить буквально несколько HTML тегов на странице. Для этого мы используем HTML редактор, который встроен в средства разработки.
Как открыть средства разработки?
Если вы работаете через браузер FireFox или Chrome, то откройте страницу сайта, которую хотите отредактировать, и кликните на клавишу F12 на клавиатуре. Откроется панель разработчика.
В большинстве браузеров средства разработки называются более-менее одинаково и имеют очень схожий функционал. Далее в статье будет рассматриваться браузер FireFox.
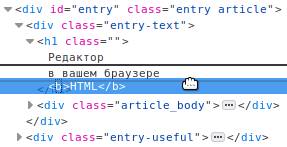
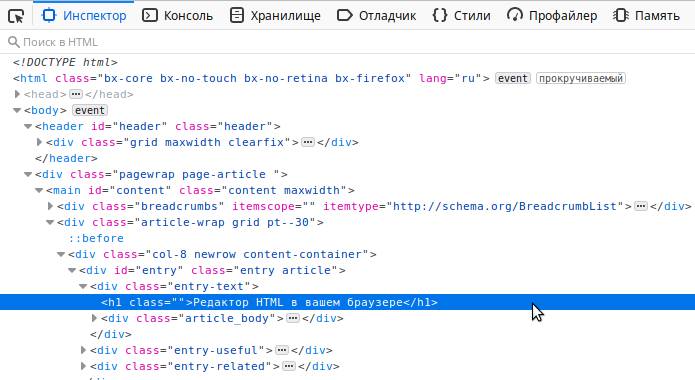
Теперь необходимо выбрать HTML тег, который хотим изменить. Выбор можно сделать с помощью курсора мыши в появившемся окне, в закладке «Инспектор»:
В инспекторе нужно найти интересующий тег и кликнуть по нему, чтобы выделить. Но искать так долго, поэтому для упрощения поиска можно воспользоваться функцией выбора элемента прямо из дизайна сайта. Для этого найдите с левом верхнем углу иконку выбора элемента курсором: или нажмите комбинацию клавиш Ctrl + Shift + C . Теперь можно выбрать курсором любой элемент на странице сайта и кликнуть на него: Тогда в окне инспектора будет автоматически найден этот элемент, а в окне «Инспектора» строчка с его HTML кодом будет подсвечена. Кликните на эту строчку правой кнопкой мыши, чтобы выбрать пункт «Править как HTML»: В открывшемся текстовом поле вы сможете увидеть HTML код элемента и исправить его. Можно использовать HTML теги. Давайте попробуем выделить жирным фразу HTML, для этого обрамим её тегом : После окончания ввода кликните на любой другой тег в инспекторе, вне текстового поля, в котором проходило редактирование. Тогда поле для редактирования закроется и можно будет увидеть изменения в HTML коде страницы: При клике правой кнопкой мыши на тег в инспекторе можно заметить и другие опции. К примеру, «Удалить узел» удаляет тег с его содержимым и дочерними тегами, а «Дублировать узел» делает полную копию и вставляет после того, на который кликнули.В редакторе есть функция перетаскивания тегов. Наведите курсором мыши на тег и перенесите в любое место в документе, зажав левой кнопкой мыши:
Все перечисленные инструменты упрощают разработку сайтов. Но обратите внимание, что изменения никак не сохраняются ни на сервере, ни в локальных файлах. Это означает, что все сделанные изменения пропадут после того, как страница перезагрузился. Поэтому обязательно сохраняйте изменения в файлах, а редактор HTML используйте только для того, чтобы оценить последствия изменений на сайте.
Редактирование статических HTML страниц в браузере
В процессе создания очередного статического сайта-заглушки появилась потребность оптимизировать процесс. Что из этого получилось?
Итак цель — создание удобного редактора статических HTML страниц в браузере. Редактор имеет два режима. Редактирование текста и редактирование HTML.
Редактирование текста активируется кликом на нужном элементе. Для редактирования HTML делаем двойным клик.
В режиме редактирования HTML подсветка кода на основе google-code-prettify (известный по использованию в документации twitter bootstrap) и jsbeautifier для форматирования кода.
Для сохранения изменений используется простой node.js сервер позволяющий сохранять изменения и создавать копию текущей страницы.Как это работает:
$(document).click(function (event)
$(document).dblclick(function (event) < //форматируем код библиотекой jsbeautifier var str = style_html( $(current).html() ); //html - text str = str.replace(/\&(?!(\w+;))/g, '&').replace(/' + str + ''); //запускаем prettify парсер prettyPrint(); >);
После окончания редактирования элемента
$(current).html( $( current ).text() );var content = “”; $('.prettyprint').children().each(function(i) < var nodeHtml = $(this).html(); content += nodeHtml; >); //возвращаем текс в хтмл content = content.split('<').join('<'); content = content.split('>').join('>'); $(current).html( content );Установка и пример использования:
Для тестирования
необходимустановленный node.js (если его нет начать можно здесь habrahabr.ru/post/95960 или здесь nodejs.org/download)
Update: добавлена поддержка PHPВоспользуемся bootstrap шаблоном от initializr
git clone https://github.com/verekia/initializr-bootstrap.git cd initializr-bootstrapgit clone https://github.com/xreader/inplaceeditor.git cp -r inplaceeditor/* .PHP
Node.js
Открываем http://localhost:3000 и начинаем редактировать.
Легенда:
- Клик на элементе для редактирования текста страницы
- Двойной клик для активации режима редактирования HTML
- Справа вверху кнопка Save сохраняет изменения. Кнопка Copy рядом делает копию текущей страницы и делает переход на неё
- Для завершения редактирования можно использовать клик на не редактируемом элементе или ESC
Перед загрузкой на сервер не забываем удалять вызов редактора!
Чего не хватает?
Портировать node.js на phpДобавить возможность аутентификации для редактирования непосредственно на сервере
Update: попробовать можно здесь: xreader.github.com/inplaceeditor/demo.html
Без возможности сохранения и копированияUpdate 2: Добавлена возможность аутентификации пользователя для защиты от редактирования
Имя/пароль прописаны в server.js admin:secretUpdate 3: Добавленa поддержка PHP
В inplaceeditor.js нужно поменять
 В инспекторе нужно найти интересующий тег и кликнуть по нему, чтобы выделить. Но искать так долго, поэтому для упрощения поиска можно воспользоваться функцией выбора элемента прямо из дизайна сайта. Для этого найдите с левом верхнем углу иконку выбора элемента курсором:
В инспекторе нужно найти интересующий тег и кликнуть по нему, чтобы выделить. Но искать так долго, поэтому для упрощения поиска можно воспользоваться функцией выбора элемента прямо из дизайна сайта. Для этого найдите с левом верхнем углу иконку выбора элемента курсором: 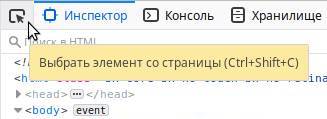 или нажмите комбинацию клавиш Ctrl + Shift + C . Теперь можно выбрать курсором любой элемент на странице сайта и кликнуть на него:
или нажмите комбинацию клавиш Ctrl + Shift + C . Теперь можно выбрать курсором любой элемент на странице сайта и кликнуть на него: 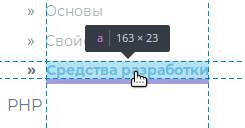 Тогда в окне инспектора будет автоматически найден этот элемент, а в окне «Инспектора» строчка с его HTML кодом будет подсвечена. Кликните на эту строчку правой кнопкой мыши, чтобы выбрать пункт «Править как HTML»:
Тогда в окне инспектора будет автоматически найден этот элемент, а в окне «Инспектора» строчка с его HTML кодом будет подсвечена. Кликните на эту строчку правой кнопкой мыши, чтобы выбрать пункт «Править как HTML»: 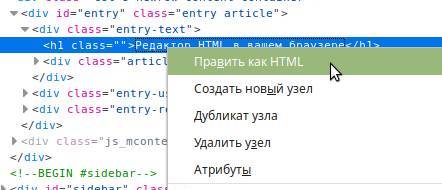 В открывшемся текстовом поле вы сможете увидеть HTML код элемента и исправить его. Можно использовать HTML теги. Давайте попробуем выделить жирным фразу HTML, для этого обрамим её тегом :
В открывшемся текстовом поле вы сможете увидеть HTML код элемента и исправить его. Можно использовать HTML теги. Давайте попробуем выделить жирным фразу HTML, для этого обрамим её тегом :  После окончания ввода кликните на любой другой тег в инспекторе, вне текстового поля, в котором проходило редактирование. Тогда поле для редактирования закроется и можно будет увидеть изменения в HTML коде страницы:
После окончания ввода кликните на любой другой тег в инспекторе, вне текстового поля, в котором проходило редактирование. Тогда поле для редактирования закроется и можно будет увидеть изменения в HTML коде страницы: 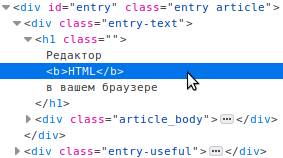 При клике правой кнопкой мыши на тег в инспекторе можно заметить и другие опции. К примеру, «Удалить узел» удаляет тег с его содержимым и дочерними тегами, а «Дублировать узел» делает полную копию и вставляет после того, на который кликнули.
При клике правой кнопкой мыши на тег в инспекторе можно заметить и другие опции. К примеру, «Удалить узел» удаляет тег с его содержимым и дочерними тегами, а «Дублировать узел» делает полную копию и вставляет после того, на который кликнули.