- Javascript — Importing HTML blocks, fetch
- The fetch method
- Templates
- Как подгрузить HTML-код из файла силами JavaScript на web-страницу через объект XMLHttpRequest?
- Задача
- Предпосылки. Зачем это нужно?
- Решение задачи
- Логика работы объекта XMLHttpRequest
- Результат работы
- How to append HTML using JavaScript?
- Using innerHTML attribute
- JavaScript code:
- Using AdjacentHTML method
- Conclusion
- About the author
- Shehroz Azam
Javascript — Importing HTML blocks, fetch
For relatively static HTML blocks (headers, footers…), we search an easy way to import HTML code from files.
There was an easy way, like importing CSS, JS files :
BUT, this specification has been deprecated. It does not work anymore since Chrome 73. It may still work in some browsers, its use is discouraged since it could be removed at any time.
What is the alternative ? Use the javascript fetch method.
In the example, we want to include the footer HTML data from a file called footer.inc :
The fetch method
Create a function which will load the data after the DOMContentLoaded event :
loadfooter = () => < fetch('./include/footer.inc') .then ( (r) => < return r.text(); >) .then ( (s) => < p= new DOMParser(); d = p.parseFromString(s,'text/html') ; >); >; if (document.readyState==='loading') < window.addEventListener('DOMContentLoaded', ()=>< loadfooter(); >); > else - The text() method returns the content of the file in a string variable.
- A new DOM object is built from the returned string using parseFromString() .
The DOM object structure is then the following :
#document © 2001-2021. All rights reserved. … The div block to be inserted is then extracted from the DOM object and added in the existing footer block in the document :
The element is moved from the DOM object to the document. Use clone method if we don’t want the element to be removed from the DOM object for further processing.
Templates
The fetch and parseFromString methods are very useful to import template files. The element can be indeed enriched and formatted before inserting it into the final document.
Как подгрузить HTML-код из файла силами JavaScript на web-страницу через объект XMLHttpRequest?
Файл index.html обрабатывается силами web-сервера и автоматически загружается в браузер пользователя при обращении к сайту (главной странице).
Файл index.html имеет классическую разметку документа:
DOCTYPE html> html lang="ru"> head> meta charset="UTF-8"> meta name="viewport" content="width=device-width, initial-scale=1.0"> title>Документtitle> head> body> body> html>

Это «пустая» HTML-страница со своим уникальным адресом. На странице визуально нет ничего. Просто белый лист.
Задача
Необходимо на страницу index.html подключить HTML-разметку из файла text.html , но так чтобы файл text.html содержал только HTML-элементы и . То есть мы хотим подгрузить только уникальную информацию на страницу без «лишних» мета-данных.
Также мы хотим сделать эту загрузку в фоне, без перезагрузки страницы index.html . То есть пользователь не увидит в адресной строке браузера другого адреса. Перезагрузки страницы не будет.
Файл text.html имеет разметку:

ВНИМАНИЕ! Запросы к серверу мы будем делать ТОЛЬКО через работающий локально веб-сервер. Ознакомьтесь с протоколом CORS и стандартом Fetch. Локальный запуск файла index.html в браузере не приведёт к работающему результату. Используйте бесплатный продукт «OpenServer» для своих тестов.
Предпосылки. Зачем это нужно?
Главная идея задачи — это создание шаблонов генерации документов силами JavaScript, при помощи которых можно лучше управлять визуальным содержимым сайта.
Каждая отдельная страница сайта перестаёт быть статичной (уже собранной). В результате, мы разделяем потенциальную страницу на части. Например:
- Один документ отвечает за шапку сайта
- Другой за подвал
- Третий за основное содержимое
- Четвёртый за боковые панели
- Пятый за рекламные баннеры
- Шестой за галерею фотографий
- Седьмой за контактную информацию
- и т. п..
Решение задачи
Для начала подключим на страницу index.html файл со скриптом, который будет называться gettext.js .
В файле index.html внутри элемента поместим элемент с атрибутом src и его значением gettext.js

Для решения задачи мы будем использовать объект XMLHttpRequest. Стандарт XMLHttpRequest определяет API-интерфейс, который предоставляет клиенту функциональные возможности по сценарию для передачи данных между клиентом и сервером .
- Посылаем запрос на сервер.
- Дожидаемся ответа. Ловим содержимое файла.
- Вносим нужные изменения в документ.
Отредактируем файл gettext.js
var inBody = function()< // Создаём анонимную функцию. Помещаем её в переменную "inBody" var xhr = new XMLHttpRequest() // Создаём локальную переменную XHR, которая будет объектом XMLHttpRequest xhr.open('GET', 'text.html') // Задаём метод запроса и URL запроса xhr.onload = function()< // Используем обработчик событий onload, чтобы поймать ответ сервера XMLHttpRequest console.log(xhr.response) // Выводим в консоль содержимое ответа сервера. Это строка! document.body.innerHTML = xhr.response // Содержимое ответа, помещаем внутрь элемент "body" > xhr.send() // Инициирует запрос. Посылаем запрос на сервер. > inBody() // Запускаем выполнение функции получения содержимого файла

Логика работы объекта XMLHttpRequest
В первой строке мы создаём анонимную функцию и помещаем её в переменную «inBody«. Название переменной описывает решаемую задачу — дословно «вТело«. То есть результатом выполнения этой функции будет интеграция содержимого файла text.html внутрь элемента загруженной странице index.html на клиенте (в браузере)
Со второй строки начинается тело функции. С помощью конструктора объектов мы создаём новый объект XMLHttpRequest и помещаем его в локальную переменную «xhr«. Название переменной означает сокращённую запись от первых трёх букв — X ML H ttp R equest ( XHR ). Т.к. область видимости ограничена родительской функцией, то можно использовать подобное название без опасений. В рабочих проектах не рекомендую использовать глобальные переменные с именем XHR , т. к. на практике такое имя применяется в основном к объектам XMLHttpRequest.
Третья строка запускает метод open() объекта XMLHttpRequest. В этом методе задаётся HTTP-метод запроса и URL-адрес запроса. В нашем случае мы хотим получить содержимое файла по адресу «text.html», который находится в той же директории, что и загруженный в браузер index.html. Получать содержимое мы будем методом «GET» протокола HTTP.
Четвёртая строка описывает логику работы обработчика события onload. Пользовательский агент ДОЛЖЕН отправить событие load, когда реализация DOM завершит загрузку ресурса (такого как документ) и любых зависимых ресурсов (таких как изображения, таблицы стилей или сценарии). То есть обработчиком события onload мы ловим срабатывание типа события load и полученные ресурсы мы достаём при помощи атрибута ответа response объекта XMLHttpRequest.
Пятой строкой мы выводим в консоль результат ответа сервера. Она необходима для разработки. Она не обязательна. ВНИМАНИЕ! Содержимое ответа по-умолчанию имеет тип данных — string (строка). Это стандарт клиент-серверного взаимодействия. Все данные передаются по сети в виде «строковых данных». Так всегда происходит — это норма. Если вы точно знаете каким образом строка будет оформлена, тогда вы можете воспользоваться атрибутом ответа responseType и в этом случае содержимое ответа будет одним из:
- пустая строка (по умолчанию),
- arraybuffer
- blob
- document
- json
- text
В шестой строке мы присваиваем элементу внутренне содержимое пришедшее из файла на сервере. Это содержимое будет заключено между открывающим и закрывающим . XMLHttpRequest имеет связанный ответ response.
Восьмая строка инициирует запрос на сервер методом send() и отправляет его.
На десятой строке мы вызываем функцию «inBody»
Результат работы

Мы видим итоговую страницу с нужным нам содержимым. На favicon не обращаем внимания т. к. браузер Chrome вдруг решил его поискать.
Вкладка имеет название «Документ», которое пришло из элемента .


Главная страница нашего «воображаемого» сайта http://getinnerofpage/ содержит информацию, пришедшую из другого файла.

Разметка итогового документа после выполнения запроса к серверу. Браузер «переварил» строковые данные и преобразовал их в HTML-разметку.

В инструментах разработчика на вкладке Network мы видим последовательность загрузки данных для главной страницы сайта

Сперва браузер запросил HTML-документ главной страницы сайта. Статус 200 — ОК. Потом после разбора разметки браузер загрузил файл со скриптом. Статус 200 — ОК. После этого браузер начал синхронно обрабатывать выполнение инструкций файла скрипта. На восьмой строчке выполнения файла gettext.js мы видим обращение к файлу text.html

Статус 200 — ОК означает успешную подачу запроса — запрашиваемые ресурсы имеются на сервере.

В ответе сервера браузер уже понимает пришедшие данные и подсвечивает HTML-синтаксис, указывая на элементы и . То есть браузер уже сам разобрал пришедший тип данных string и подсветил разработчику открывающиеся и закрывающиеся элементы.
Важно обратить внимание, что на подгрузку данных «в фоне» потребовалось некоторое время. В реальных проектах нужно учитывать эту особенность и правильно распределять зависимости последовательностей отдачи содержимого пользователю.
Может оказаться так, что при формировании финансового графика часть данных не успеет прийти вовремя — это исказит трактование данных из отчёта и навредит бизнесу из-за ошибки вычислений. Будьте внимательны! В таких случаях уместно использовать объект Promise .
How to append HTML using JavaScript?
![]()
Writing HTML code is easy, but when it comes to dynamic changes over the pages like appending HTML, you need to use unusual strategies. JavaScript is a powerful language to get such kinds of jobs done. You can easily use JavaScript to put the HTML code inside the template. We will discuss this in this write-up.
Through JavaScript, there are two ways to attach HTML code to a div tag.
- Using innerHTML property
- Inserting adjacent HTML using the insertAdjacentHTML() function
Using innerHTML attribute
To use the innerHTML property to attach code to an element (div), first pick the element (div) where you wish to append the code. Then, using the += operator on innerHTML, add the code wrapped as strings.
Here’s the syntax of the attribute.
Let’s take an example of this. First, we are going to be referring to the HTML element by using the property :
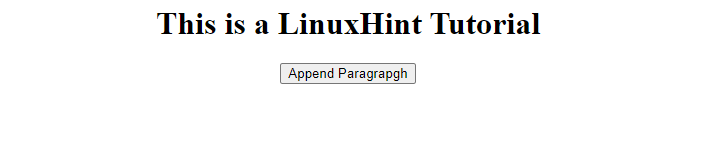
Therefore, let’s create a div> and put a h1> tag and a button> inside it.
< h1 >This is a LinuxHint Tutorial
As you can see, we have given an id of “test” to the div tag and placed the text that says “Append Paragraph” inside the button. With these, we have the following result on the screen
JavaScript code:
We have a button linked to a function named “buttonPressed()” in the script. But, we have not defined this function, and this button does not do anything. So, let’s create this function in the script that would add a paragraph in this div and count how many times we have added this paragraph. Take a look at the following code.
document. getElementById ( «test» ) . innerHTML +=
«
Yoo have append this paragraph » + i + » times» ;
Note: We have created a counter variable “i”. This will be used to keep a check on how many times have we append this paragraph inside the div tag.
Now, if we run the code and press the button we get:
Note: This technique essentially removes all of the div’s content and replaces it with new stuff. Any listeners linked to the child nodes of that div will be lost as a result. That is why we always concatenate it.
Using AdjacentHTML method
The insertAdjacentHTML() function can also be used to attach HTML code to a div. This method is comes in handy when it comes to appending HTML at some specific place. So it takes two parameters in this method:
- The location (in the document) where the code should be inserted (‘afterbegin’, ‘beforebegin’, ‘afterend’, ‘beforeend’).
- afterbegin – right after the HTML element mentioned but inside the tag.
- beforebegin – before the HTML element mentioned
- afterend – after the closing tag of the HTML element
- beforeend – inside the HTML element but before the closing tag
This is the general syntax of the method
HTMLelement.insertAdjacentHTML(‘LOCATION‘, ‘HTML CODE’);
Let’s use the previous example. The same HTML code. However, this time the script would be slight different as:
Note: Since we are using the previous example, the HTML code is exactly the same.
JavaScript Code:
i = 1 ;
function buttonPressed ( ) {
document. getElementById ( «test» ) . insertAdjacentHTML ( «beforebegin» ,
«Appended » + i + » times Before Div
» ) ;
i ++;
}Note: We are using the “beforebegin” property to append the tag before the start of the div.
That’s it, you have learned how can we append some HTML code through JavaScript.
Conclusion
There are two methods that you can use to append the HTML code into a webpage. The first method is by using innerHTML while the second method is by using the AdjacentHTML method. In this article, we have taken examples of both the innerHTML and AdjacentHTML methods to append the HTML code into a webpage.
About the author
Shehroz Azam
A Javascript Developer & Linux enthusiast with 4 years of industrial experience and proven know-how to combine creative and usability viewpoints resulting in world-class web applications. I have experience working with Vue, React & Node.js & currently working on article writing and video creation.