Сравнение структур данных: Массивы и объекты в Javascript

Итак, вы изучили основы JavaScript и хотите перейти к изучению структур данных. Мотивация для изучения/понимания Структур данных может быть разной, поскольку мало кто из нас хочет учиться, чтобы улучшить свои навыки, мало кто хочет учиться, чтобы получить работу разработчика, а мало кто хочет учиться, потому что это кажется интересным.
Какой бы ни была мотивация, изучение и понимание структур данных может стать утомительной и разочаровывающей задачей, если не понимать, зачем и когда следует использовать структуры данных.
В этой статье речь пойдет о том, когда их использовать. В этой статье мы узнаем о массивах и объектах. Мы попытаемся понять, когда следует предпочесть одну DS другой, используя нотацию Big O.
Массивы
Одной из наиболее широко используемых структур данных являются массивы (также называемые списками в некоторых языках).
Данные внутри массива структурируются упорядоченным образом, т.е.
Первый элемент массива хранится под индексом 0, второй элемент — под индексом 1 и так далее.
JavaScript предоставляет нам некоторые встроенные структуры данных, и массив является одной из них.
В JavaScript проще всего определить массив следующим образом:
Приведенная выше строка кода создает динамический массив (неизвестной длины).
Чтобы понять суть того, как элементы массива хранятся в памяти, давайте рассмотрим пример:
let arr = ["John", "Lily", "William", "Cindy"];
В приведенном выше примере мы создаем массив, содержащий имена. Имена в памяти хранятся следующим образом:
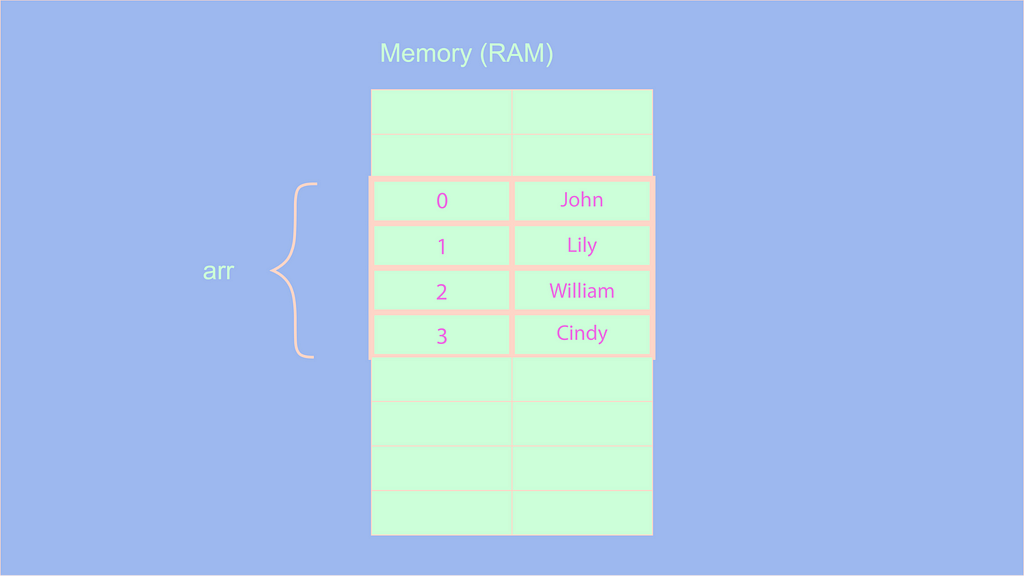
Чтобы понять, как работает массив, давайте выполним несколько операций:
Добавление элемента:
В массиве JavaScript есть различные операции для добавления элемента в конец, в начало, а также по определенному индексу.
Добавление элемента в конец:
JavaScript предоставляет свойство по умолчанию, когда мы определяем массив, это свойство length . В настоящее время свойство length имеет значение 4, так как у нас столько элементов в массиве.
Наряду со свойством length, JS также предоставляет метод push( ) . Используя этот метод, мы можем непосредственно добавить элемент в конец массива.
Имя «Jake» будет добавлено в конец:
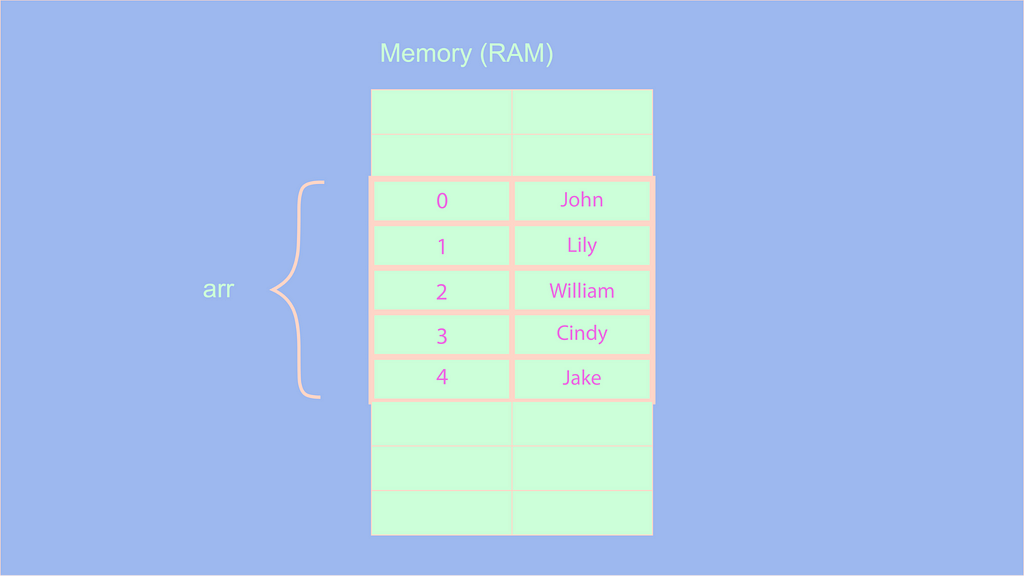
В чем же будет заключаться сложность этой команды? Мы знаем, что по умолчанию javascript предоставляет свойство length, push( ) эквивалентно использованию следующей команды:
Поскольку мы всегда имеем доступ к свойству длины массива, независимо от того, насколько большим становится массив, добавление элемента в конец всегда будет иметь сложность O(1).
Добавление элемента в начало массива:
Для этой операции javascript предоставляет метод по умолчанию под названием unshift( ). Этот метод добавляет элемент в начало массива.
let arr = ["Джон", "Лили", "Уильям", "Синди"];
arr.unshift("Роберт");
console.info(arr); // ["Роберт", "Джон", "Лили", "Уильям", "Синди"];
Теперь, хотя может показаться, что метод unshift, как и метод push( ), имеет сложность O(1) , потому что мы просто добавляем элемент вперед. Но это не так, давайте рассмотрим, что происходит, когда мы используем метод unshift:
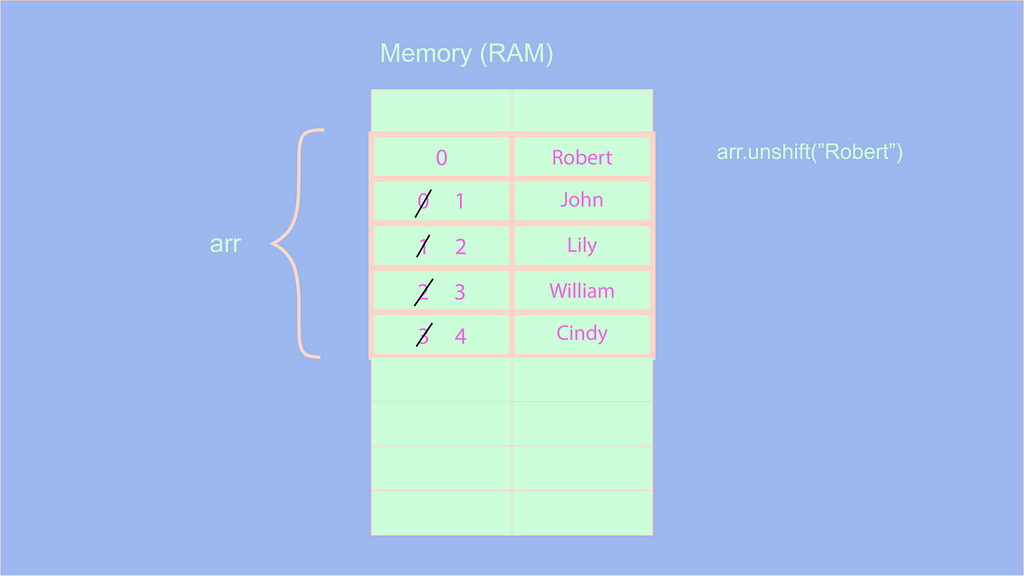
На изображении выше, когда мы используем метод unshift, индексы всех элементов должны быть увеличены или сдвинуты на 1. Мы используем массив меньшей длины. Если представить себе массив значительной длины, то использование такого метода, как unshift, приводит к задержкам, так как приходится сдвигать индексы каждого элемента массива.
Поэтому сложность операции unshift составляет O(n). Используйте метод unshift с умом, если вы работаете с массивами большой длины.
Добавление элемента по определенному индексу:
Для выполнения этой операции мы можем использовать метод javascript под названием splice( ), который имеет следующий синтаксис:
splice(startingIndex, deleteCount, elementToBeInserted);
Поскольку мы добавляем элемент, deleteCount будет равен 0.
Давайте добавим элемент с индексом 2:
let arr = ["John", "Lily", "William", "Cindy"];
arr.splice(2,0, "Janice");
console.info(arr); // ["John", "Lily", "Janice", "William", "Cindy"];
Как вы думаете, какова будет сложность этой операции? В приведенной выше операции мы добавляем элемент по индексу 2, поэтому все последующие элементы после индекса 2 должны быть увеличены или сдвинуты на 1 (включая элемент, который ранее находился по индексу 2).
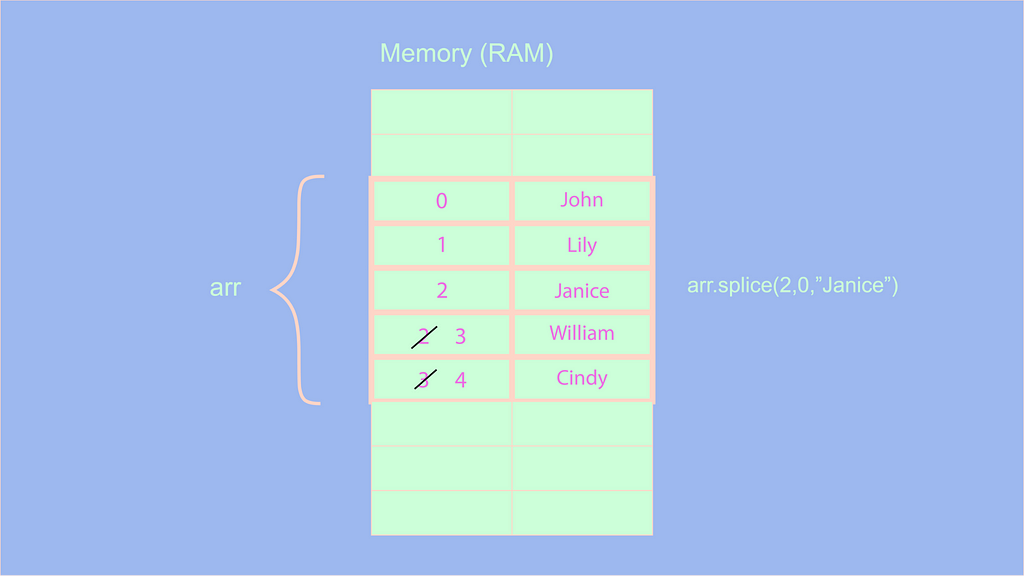
Можно заметить, что мы не сдвигаем или увеличиваем индексы всех элементов, а увеличиваем индексы элементов после индекса 2. Значит ли это, что сложность этой операции равна O(n/2)? Ответ — нет. Согласно правилам Big O, константы удаляются из сложности, а также мы должны рассматривать наихудший сценарий. Поэтому сложность этой операции равна O(n).
Удаление элемента:
Как и добавление, удаление элемента может быть выполнено в различных местах, в конце, в начале и по определенному индексу.
Удаление с конца:
Как и push( ), JS предоставляет метод по умолчанию под названием pop( ) для удаления элементов в конце массива.
let arr = ["Janice", "Gillian", "Harvey", "Tom"];
arr.pop( );
console.info(arr); // ["Janice", "Gillian", "Harvey"];
arr.pop( );
console.info(arr); // ["Janice", "Gillian"];
Эта операция имеет сложность O(1). Поскольку, каким бы большим ни был массив, удаление последнего элемента не потребует изменения индексов ни одного элемента в массиве.
Удаление первого элемента:
Для этой операции у нас есть метод по умолчанию под названием shift( ). Этот метод удаляет первый элемент массива.
let arr = ["Джон", "Лили", "Уильям", "Синди"];
arr.shift( );
console.info(arr); // ["Лили", "Уильям", "Синди"]
arr.shift( );
console.info(arr); // ["Уильям", "Синди"].
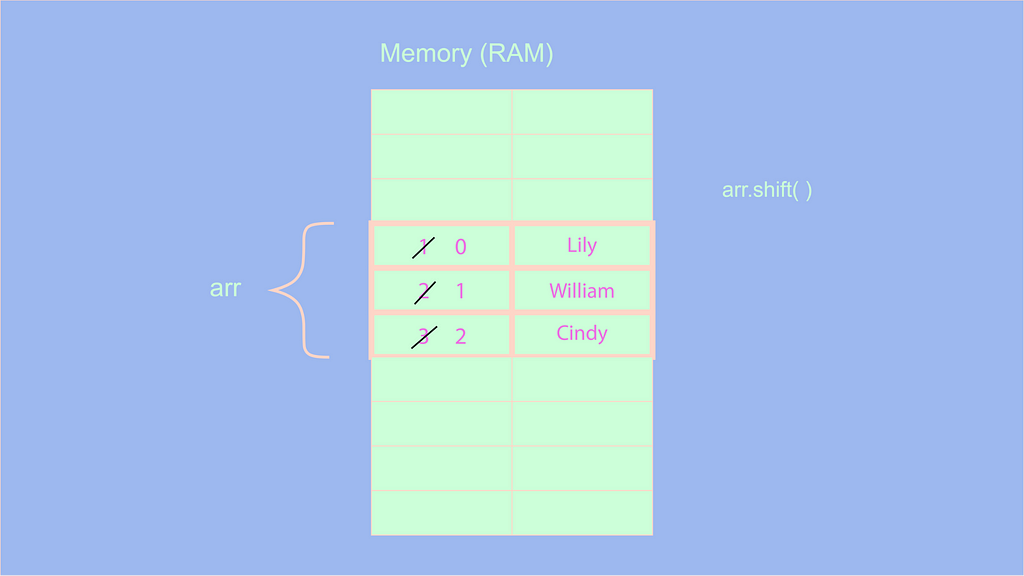
Поскольку мы уже рассмотрели метод unshift, думаю, вполне очевидно, что сложность операции shift( ) будет O(n), так как после удаления первого элемента нам нужно сдвинуть или уменьшить индексы всех элементов на 1.
Удаление по определенному индексу:
Для этой операции мы снова обратимся к методу splice( ), но на этот раз будем использовать только первые два параметра, поскольку не собираемся добавлять новый элемент по этому индексу.
let arr = ["Apple", "Orange", "Pear", "Banana", "Watermelon"];
arr.splice(2,1);
console.info(arr); // ["Apple", "Orange", "Banana", "Watermelon"].
Аналогично операции splice, которая выполнялась для добавления элементов, в этой операции мы уменьшаем или сдвигаем индексы элементов после индекса 2. Таким образом, сложность этой операции составляет O(n).
Поиск — это не что иное, как доступ к элементу массива. Мы можем получить доступ к элементам массива, используя обозначение квадратных скобок (например, arr[4]).
Как вы думаете, в чем сложность этой операции? Давайте поймем это на примере:
let fruits = ["Apple", "Orange", "Pear"];
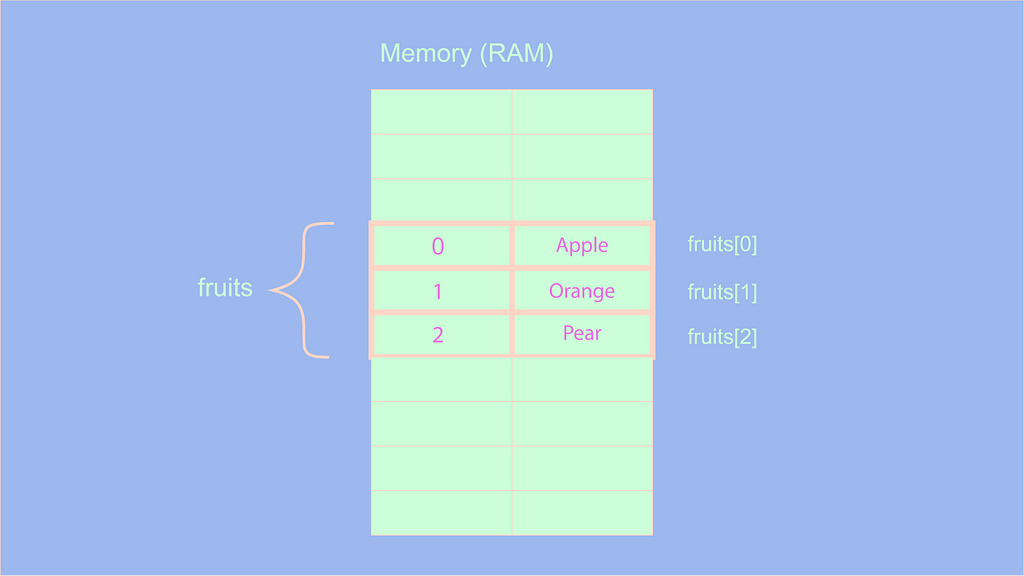
Ранее мы видели, что все элементы массива хранятся в последовательном порядке и всегда группируются вместе. Поэтому, если мы выполняем операцию fruits[1], мы говорим компьютеру найти массив с именем fruits и взять второй элемент (массивы начинаются с индекса 0). Поскольку они хранятся последовательно, компьютеру не нужно осматривать весь слот памяти, чтобы найти элемент, он может напрямую заглянуть в массив fruits, поскольку все элементы будут сгруппированы по порядку.
Поэтому операция поиска в массиве имеет сложность O(1).
Теперь, когда мы выполнили основные операции над массивом, давайте сделаем вывод, когда можно использовать массивы:
Массивы подходят для выполнения таких операций, как push( ) (добавление элемента в конец) и pop( ) (удаление элемента из конца), поскольку эти операции имеют сложность O(1).
Кроме того, операции поиска в массивах могут выполняться очень быстро.
Выполнение таких операций, как добавление/удаление элементов по определенному индексу или по фронту, может быть довольно медленным при использовании массивов, поскольку их сложность O(n).
Объекты
Как и массивы, объекты также являются одной из наиболее часто используемых структур данных. Объекты — это разновидность хэш-таблицы, которая позволяет нам хранить пары ключ-значение вместо того, чтобы хранить значения по пронумерованным индексам, как мы видели в массивах.
Проще всего определить объект следующим образом:
let student = имя: "Вивек",
возраст: 13,
класс: 8>
Давайте разберемся, как вышеупомянутый объект хранится в памяти,
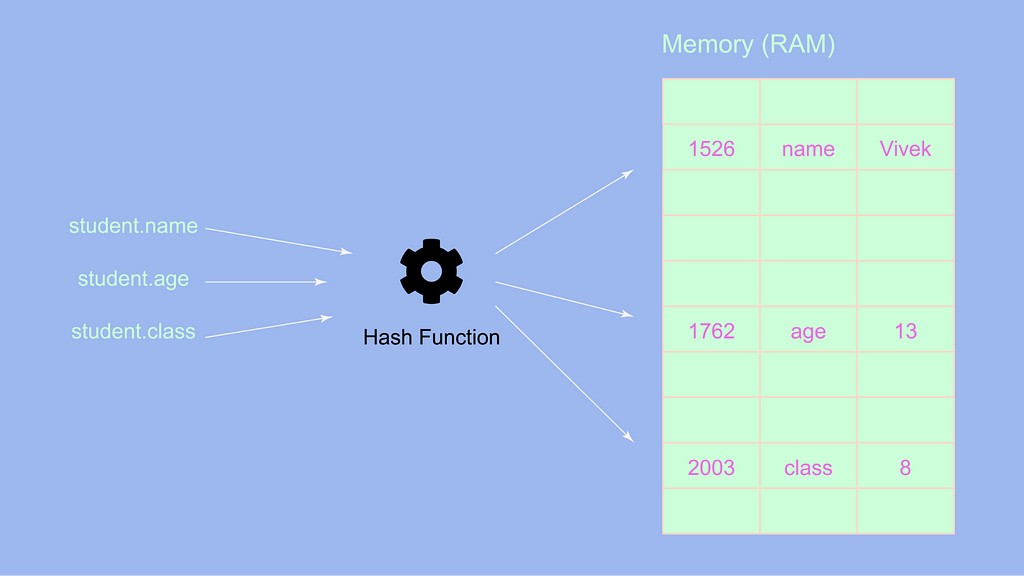
Можно заметить, что пары ключ-значение объекта хранятся случайным образом, в отличие от массивов, где все элементы хранятся вместе. Это главное отличие при сравнении массивов с объектами: в объектах пары ключ-значение хранятся в памяти случайным образом.
Мы видим, что существует хэш-функция. Что же делает эта хэш-функция?
Хэш-функция берет каждый ключ из объекта и генерирует хэшированное значение, затем это хэшированное значение преобразуется в адресное пространство, где мы храним пару ключ-значение.
Например, если мы добавим следующую пару ключ-значение к объекту student:
Ключ rollNumber проходит через хэш-функцию и преобразуется в адресное пространство, где хранятся и ключ, и значение.
Теперь, когда мы получили базовое представление о том, как объекты хранятся в памяти, давайте выполним несколько операций.
Для объектов у нас нет отдельных методов для добавления элементов спереди или сзади, поскольку все пары ключ-значение хранятся произвольно. Существует только одна операция — добавление новой пары ключ-значение к объекту.
student.parentName="Narendra Singh Bisht";
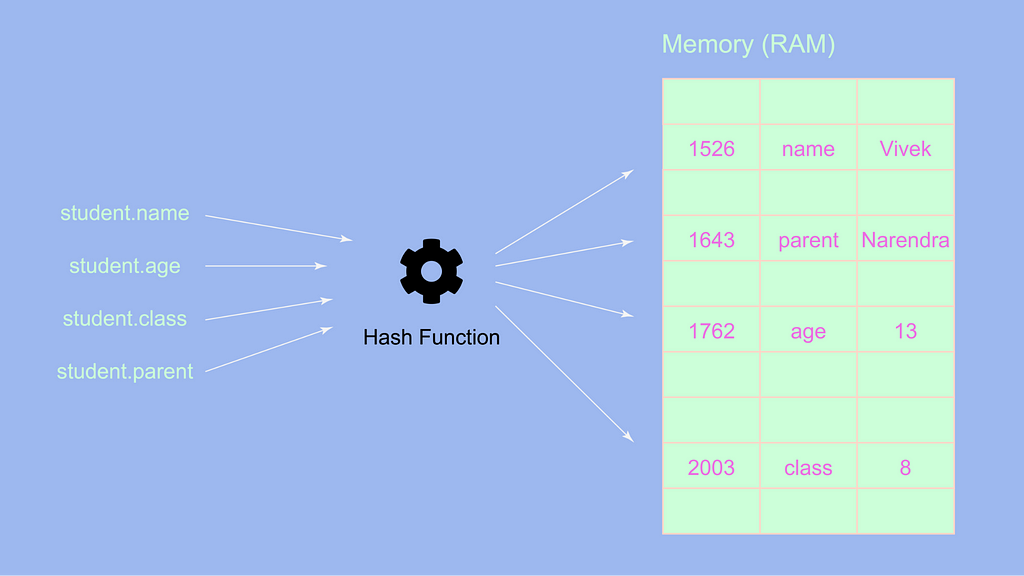
Из приведенного выше изображения можно сделать вывод, что сложность этой операции всегда будет O(1), поскольку нам не нужно менять индексы или манипулировать самим объектом, мы можем напрямую добавить пару ключ-значение, и она будет храниться в случайном адресном пространстве.
Как и добавление элемента, операция удаления объектов очень проста и имеет сложность O(1). Поскольку при удалении нам не нужно изменять или манипулировать объектами.
delete student.parentName
Теперь будет совершенно очевидно, что поиск также будет иметь сложность O(1), поскольку и здесь мы просто получаем доступ к значению с помощью ключей.
Один из способов доступа к значению в объектах:
Ого! Добавление, удаление и поиск в объектах имеют сложность O(1)? Так можно ли сделать вывод, что мы должны использовать объекты каждый раз вместо массивов? Ответ — нет. Хотя объекты — это здорово, есть небольшое условие, которое необходимо учитывать при использовании объектов.
Это условие называется Hash Collisions. Это условие не является чем-то, что нужно постоянно учитывать при использовании объектов, но понимание этого условия поможет нам лучше понять объекты.
Что же такое коллизии хэшей?
Когда мы определяем объект, наш компьютер выделяет для него место в памяти. Мы должны помнить, что пространство в нашей памяти ограничено, поэтому есть вероятность, что две или более пар ключ-значение могут иметь одинаковое адресное пространство. Это состояние называется хэш-коллизией. Чтобы лучше понять это, давайте рассмотрим пример:
Представим, что для следующего объекта выделено 5 блоков пространства:
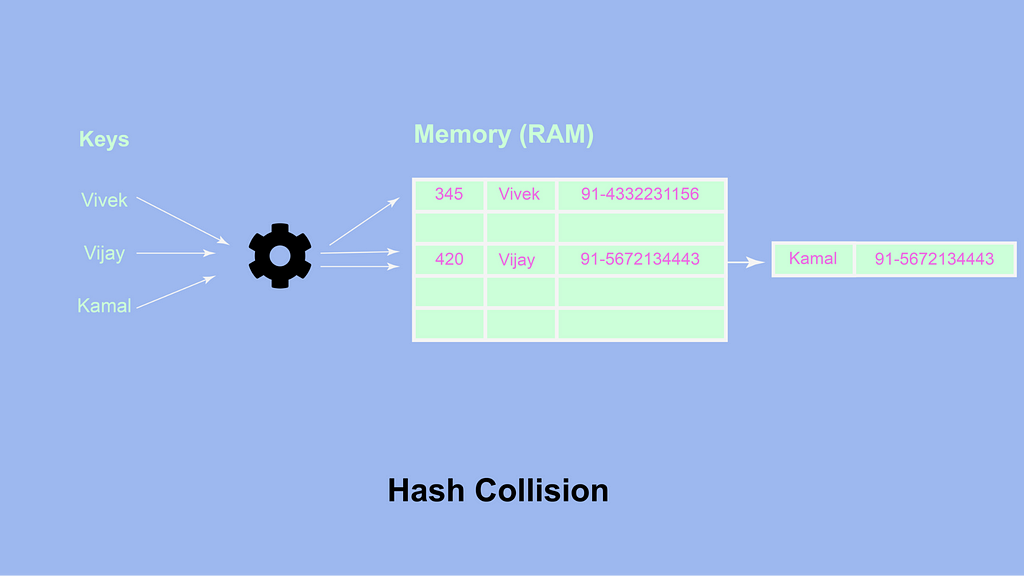
Мы видим, что две пары ключ-значение хранятся в одном и том же адресном пространстве. Как это может произойти? Это происходит, когда хэш-функция возвращает хэш-значение, которое преобразуется в одно и то же адресное пространство для нескольких ключей. Из-за этого несколько ключей отображаются в одно и то же адресное пространство. Из-за хэш-коллизий добавление и доступ к значениям могут иметь сложность O(n), поскольку для доступа к определенному значению нам, возможно, придется перебрать несколько пар ключ-значение.
Коллизии хэша — это не то, с чем нам нужно бороться каждый раз, когда мы используем объекты. Это условие, которое помогает нам понять, что объекты не являются совершенной структурой данных.
Кроме коллизий хэша, есть еще одно условие, с которым мы должны быть осторожны при использовании объектов. JavaScript предоставляет нам встроенный метод для перебора ключей объектов, который называется метод keys( ). Мы можем применить этот метод к любому объекту следующим образом: object1.keys( ). Метод keys( ) выполняет итерацию по объекту и возвращает все ключи. Хотя этот метод кажется простым, мы должны понимать, что пары ключ-значение в объектах хранятся в памяти случайным образом, поэтому итерация по объекту становится более медленной задачей, в отличие от итерации по массивам, где они сгруппированы по порядку.
Итак, давайте сделаем вывод об объектах. Мы можем использовать объекты, когда хотим выполнить такие действия, как добавление, удаление и доступ к элементу, но при использовании объектов мы должны быть осторожны с итерацией по объекту, поскольку это может занять много времени. Наряду с итерацией, мы также должны понимать, что иногда существует вероятность того, что операции добавления и доступа могут иметь сложность O(n) из-за коллизий хэша.