- KnpCode
- Java Program to write to a file in HDFS
- Executing program in Hadoop environment
- Writing HDFS file using IOUtils class
- Pre-requisites
- Create a Maven Project
- Adding Maven Dependency for HDFS Libraries
- Java Program for Creating File in HDFS
- Java Program for Reading File from HDFS
- Tech Tutorials
- Thursday, June 7, 2018
- Java Program to Write File in HDFS
- Writing a file in HDFS using FSDataOutputStream
- Writing a file in HDFS using IOUtils class
- Writing A File To HDFS – Java Program
KnpCode
This post shows a Java program to write a file in HDFS using the Hadoop FileSystem API.
Steps for writing a file in HDFS using Java are as follows-
- FileSystem is an abstraction of file system of which HDFS is one implementation. So you will have to get an instance of FileSystem (HDFS in this case) using the get method.
- In the program you can see get() method takes Configuration as an argument. Configuration object has all the configuration related information read from the configuration files (i.e. core-site.xml from where it gets the file system).
- In HDFS, Path object represents the Full file path.
- Using create() method of FileSystem you can create a file, method returns FSDataOutputStream.
Java Program to write to a file in HDFS
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class HDFSFileWrite < public static void main(String[] args) < Configuration conf = new Configuration(); try < FileSystem fs = FileSystem.get(conf); // Hadoop DFS Path - Input & Output file Path inFile = new Path(args[0]); Path outFile = new Path(args[1]); // Verification if (!fs.exists(inFile)) < System.out.println("Input file not found"); throw new IOException("Input file not found"); >if (fs.exists(outFile)) < System.out.println("Output file already exists"); throw new IOException("Output file already exists"); >// open and read from file FSDataInputStream in = fs.open(inFile); // Create file to write FSDataOutputStream out = fs.create(outFile); byte buffer[] = new byte[256]; try < int bytesRead = 0; while ((bytesRead = in.read(buffer)) >0) < out.write(buffer, 0, bytesRead); >> catch (IOException e) < System.out.println("Error while copying file"); >finally < in.close(); out.close(); >> catch (IOException e) < // TODO Auto-generated catch block e.printStackTrace(); >> > In the above program both input and output files are in HDFS if your input file is in local file system then you can use BufferedInputStream to create an input stream as given here-
InputStream in = new BufferedInputStream(new FileInputStream("/local_file_path/file_name")); Executing program in Hadoop environment
To execute above Java program in Hadoop environment, you will need to add the directory containing the .class file for the Java program in Hadoop’s classpath.
export HADOOP_CLASSPATH='/huser/eclipse-workspace/knpcode/bin'
I have my HDFSFileWrite.class file in location /huser/eclipse-workspace/knpcode/bin so I have exported that path.
Then you can run the program by providing the path of the input file from which data is read and the path of the output file to which content is written.
hadoop org.knpcode.HDFSFileWrite /user/input/test/aa.txt /user/input/test/write.txt
By using the ls HDFS command you can verify that the file is created or not.
hdfs dfs -ls /user/input/test/ -rw-r--r-- 1 knpcode supergroup 10 2018-01-18 14:55 /user/input/test/write.txt
Writing HDFS file using IOUtils class
Hadoop framework provides IOUtils class that has many convenient methods related to I/O. You can use that to copy bytes from the input stream to output stream.
Java program to write HDFS file
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; public class HDFSFileWrite < public static void main(String[] args) < Configuration conf = new Configuration(); FSDataInputStream in = null; FSDataOutputStream out = null; try < FileSystem fs = FileSystem.get(conf); // Hadoop DFS Path - Input & Output file Path inFile = new Path(args[0]); Path outFile = new Path(args[1]); // Verification if (!fs.exists(inFile)) < System.out.println("Input file not found"); throw new IOException("Input file not found"); >if (fs.exists(outFile)) < System.out.println("Output file already exists"); throw new IOException("Output file already exists"); >try < // open and read from file in = fs.open(inFile); // Create file to write out = fs.create(outFile); IOUtils.copyBytes(in, out, 512, false); >finally < IOUtils.closeStream(in); IOUtils.closeStream(out); >> catch (IOException e) < // TODO Auto-generated catch block e.printStackTrace(); >> > That’s all for the topic Java Program to Write a File in HDFS. If something is missing or you have something to share about the topic please write a comment.
Pre-requisites
Here are the pre-requisites that are required before following the instructions in this tutorial:
- Apache Hadoop Cluster — If you don’t have running cluster of Apache Hadoop, please set up Apache Hadoop 2.6 cluster.
- JDK 7 or later installed on machine
- Eclipse IDE with Apache Maven Plugin
Create a Maven Project
We will be starting with creating a Maven project in Eclipse using below steps:
- Open New Project wizard in Eclipse IDE as shown below:
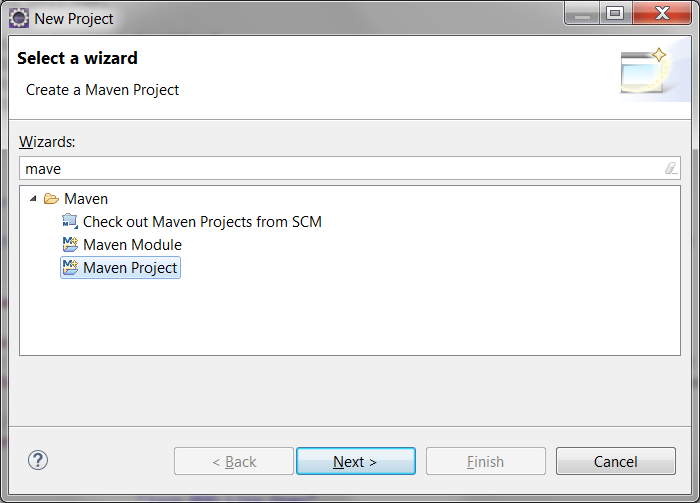
On next screen, select option Create a simple project to create quick project as below:
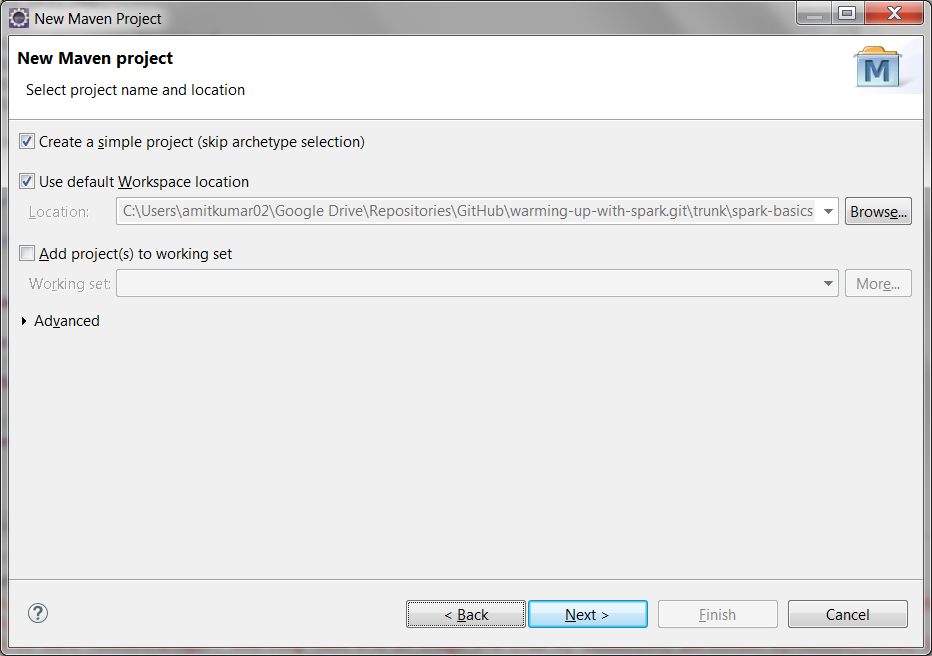
Enter Group Id and Artifiact Id on next screen and finally click on Finish to create the project as below:
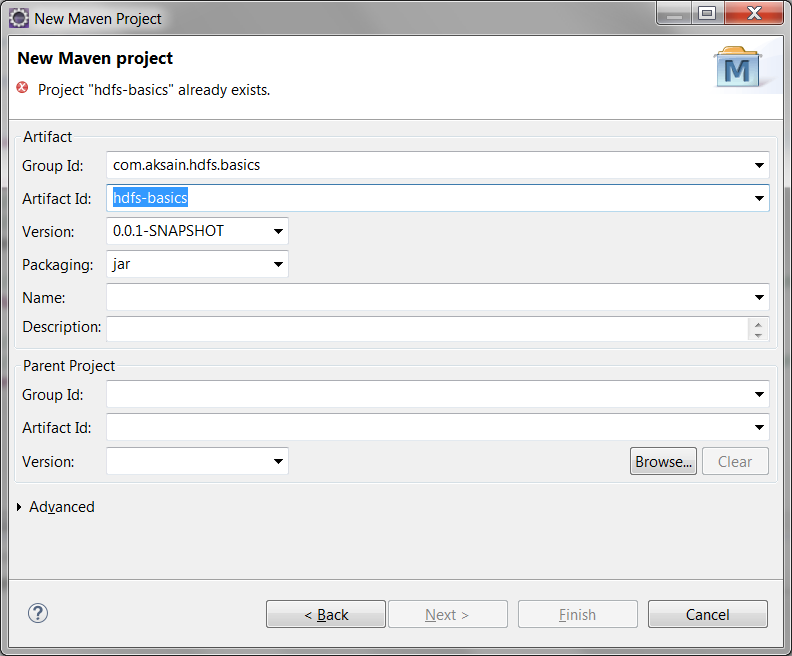
At this point, you will start seeing your new project (in my case, it is hdfs-basics) in Project Explorer.
Adding Maven Dependency for HDFS Libraries
Next step is to add Apache Hadoop libraries to our newly created project. In order to do so, we will be adding following maven dependencies to our project’s pom.xml file.
org.apache.hadoop hadoop-hdfs 2.6.2 org.apache.hadoop hadoop-common 2.6.2 For completion purpose, here is what my pom.xml looks like after adding above dependency —
4.0.0 com.aksain.hdfs.basics hdfs-basics 0.0.1-SNAPSHOT org.apache.hadoop hadoop-hdfs 2.6.2 org.apache.hadoop hadoop-common 2.6.2 After adding these dependencies, Eclipse will automatically start downloading the libraries from Maven repository. Please be patient as it may take a while for Eclipse to download the jars and build your project.
Java Program for Creating File in HDFS
Now we will create a Java program for creating a file named tutorials-links.txt in directory /allprogtutorials in Hadoop HDFS. We will then add tutorial links to this newly created file. Please replace 192.168.1.8 with your HDFS NameNode IP address / host name before running the program.
package com.aksain.hdfs.basics; import java.io.PrintWriter; import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hdfs.DistributedFileSystem; /** * @author Amit Kumar * * Demonstrates creating of a file in Distributed HDFS and writing content into it. * */ public class HDFSJavaAPIWriteDemo < public static void main(String[] args) throws Exception< // Impersonates user "root" to avoid performance problems. You should replace it // with user that you are running your HDFS cluster with System.setProperty("HADOOP_USER_NAME", "root"); // Path that we need to create in HDFS. Just like Unix/Linux file systems, HDFS file system starts with "/" final Path path = new Path("/allprogtutorials/tutorials-links.txt"); // Uses try with resources in order to avoid close calls on resources // Creates anonymous sub class of DistributedFileSystem to allow calling initialize as DFS will not be usable otherwise try(final DistributedFileSystem dFS = new DistributedFileSystem() < < initialize(new URI("hdfs://192.168.1.8:50050"), new Configuration()); >>; // Gets output stream for input path using DFS instance final FSDataOutputStream streamWriter = dFS.create(path); // Wraps output stream into PrintWriter to use high level and sophisticated methods final PrintWriter writer = new PrintWriter(streamWriter);) < // Writes tutorials information to file using print writer writer.println("Getting Started with Apache Spark =>http://www.allprogrammingtutorials.com/tutorials/getting-started-with-apache-spark.php"); writer.println("Developing Java Applications in Apache Spark => http://www.allprogrammingtutorials.com/tutorials/developing-java-applications-in-spark.php"); writer.println("Getting Started with RDDs in Apache Spark => http://www.allprogrammingtutorials.com/tutorials/getting-started-with-rdds-in-spark.php"); System.out.println("File Written to HDFS successfully!"); > > > You can execute this program simply by peforming these operations on our program: Right Click -> Run As -> Java Application. Here is the output that you will see if the program runs successfully.
File Written to HDFS successfully!You can go to your HDFS user interface to browse the file system in order to verify whether file has been written successfully by visiting the link — http://192.168.1.8:50070/explorer.html#/allprogtutorials. Obviously you need to replace 192.168.1.8 with the ip address/host of your NameNode machine.
Java Program for Reading File from HDFS
Now we will create a Java program for reading a file named tutorials-links.txt in directory /allprogtutorials in Hadoop HDFS. We will then print the contents of the file on console.Please replace 192.168.1.8 with your HDFS NameNode IP address / host name before running the program.
package com.aksain.hdfs.basics; import java.net.URI; import java.util.Scanner; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hdfs.DistributedFileSystem; /** * @author Amit Kumar * * Demonstrates reading of a file from Distributed HDFS. * */ public class HDFSJavaAPIReadDemo < public static void main(String[] args) throws Exception< // Impersonates user "root" to avoid performance problems. You should replace it // with user that you are running your HDFS cluster with System.setProperty("HADOOP_USER_NAME", "root"); // Path that we need to create in HDFS. Just like Unix/Linux file systems, HDFS file system starts with "/" final Path path = new Path("/allprogtutorials/tutorials-links.txt"); // Uses try with resources in order to avoid close calls on resources // Creates anonymous sub class of DistributedFileSystem to allow calling initialize as DFS will not be usable otherwise try(final DistributedFileSystem dFS = new DistributedFileSystem() < < initialize(new URI("hdfs://192.168.1.8:50050"), new Configuration()); >>; // Gets input stream for input path using DFS instance final FSDataInputStream streamReader = dFS.open(path); // Wraps input stream into Scanner to use high level and sophisticated methods final Scanner scanner = new Scanner(streamReader);) < System.out.println("File Contents: "); // Reads tutorials information from file using Scanner while(scanner.hasNextLine()) < System.out.println(scanner.nextLine()); >> > > You can execute this program simply by peforming these operations on our program: Right Click -> Run As -> Java Application. Here is the output that you will see if the program runs successfully.
File Contents: Getting Started with Apache Spark => http://www.allprogrammingtutorials.com/tutorials/getting-started-with-apache-spark.php Developing Java Applications in Apache Spark => http://www.allprogrammingtutorials.com/tutorials/developing-java-applications-in-spark.php Getting Started with RDDs in Apache Spark => http://www.allprogrammingtutorials.com/tutorials/getting-started-with-rdds-in-spark.php Thank you for reading through the tutorial. In case of any feedback/questions/concerns, you can communicate same to us through your comments and we shall get back to you as soon as possible.
Tech Tutorials
Tutorials and posts about Java, Spring, Hadoop and many more. Java code examples and interview questions. Spring code examples.
Thursday, June 7, 2018
Java Program to Write File in HDFS
In this post we’ll see a Java program to write a file in HDFS. You can write a file in HDFS in two ways-
- Create an object of FSDataOutputStream and use that object to write data to file. See example.
- You can use IOUtils class provided by Hadoop framework. See example.
Writing a file in HDFS using FSDataOutputStream
package org.netjs; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class HDFSFileWrite < public static void main(String[] args) < Configuration conf = new Configuration(); FSDataInputStream in = null; FSDataOutputStream out = null; try < FileSystem fs = FileSystem.get(conf); // Input & Output file paths Path inFile = new Path(args[0]); Path outFile = new Path(args[1]); // check if file exists if (!fs.exists(inFile)) < System.out.println("Input file not found"); throw new IOException("Input file not found"); >if (fs.exists(outFile)) < System.out.println("Output file already exists"); throw new IOException("Output file already exists"); >in = fs.open(inFile); out = fs.create(outFile); byte buffer[] = new byte[256]; int bytesRead = 0; while ((bytesRead = in.read(buffer)) > 0) < out.write(buffer, 0, bytesRead); >> catch (IOException e) < // TODO Auto-generated catch block e.printStackTrace(); >finally < try < if(in != null) < in.close(); >if(out != null) < out.close(); >> catch (IOException e) < // TODO Auto-generated catch block e.printStackTrace(); >> > > To run program— hadoop org.netjs.HDFSFileWrite /user/process/display.txt /user/process/writeFile.txt
Writing a file in HDFS using IOUtils class
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; public class HDFSFileWrite < public static void main(String[] args) < Configuration conf = new Configuration(); FSDataInputStream in = null; FSDataOutputStream out = null; try < FileSystem fs = FileSystem.get(conf); // Input & Output file paths Path inFile = new Path(args[0]); Path outFile = new Path(args[1]); // check if file exists if (!fs.exists(inFile)) < System.out.println("Input file not found"); throw new IOException("Input file not found"); >if (fs.exists(outFile)) < System.out.println("Output file already exists"); throw new IOException("Output file already exists"); >in = fs.open(inFile); out = fs.create(outFile); IOUtils.copyBytes(in, out, 512, false); > catch (IOException e) < // TODO Auto-generated catch block e.printStackTrace(); >finally < IOUtils.closeStream(in); IOUtils.closeStream(out); >> > That’s all for this topic Java Program to Write File in HDFS. If you have any doubt or any suggestions to make please drop a comment. Thanks!
Writing A File To HDFS – Java Program

Writing a file to HDFS is very easy, we can simply execute hadoop fs -copyFromLocal command to copy a file from local filesystem to HDFS. In this post we will write our own Java program to write the file from local file system to HDFS.
Here is the program – FileWriteToHDFS.java
public class FileWriteToHDFS < public static void main(String[] args) throws Exception < //Source file in the local file system String localSrc = args[0]; //Destination file in HDFS String dst = args[1]; //Input stream for the file in local file system to be written to HDFS InputStream in = new BufferedInputStream(new FileInputStream(localSrc)); //Get configuration of Hadoop system Configuration conf = new Configuration(); System.out.println("Connecting to -- "+conf.get("fs.defaultFS")); //Destination file in HDFS FileSystem fs = FileSystem.get(URI.create(dst), conf); OutputStream out = fs.create(new Path(dst)); //Copy file from local to HDFS IOUtils.copyBytes(in, out, 4096, true); System.out.println(dst + " copied to HDFS"); >> The program takes in 2 parameters. The first paramter is the file and its location in the local file system that will be copied to the location mentioned in the second parameter in HDFS.
//Source file in the local file system String localSrc = args[0]; //Destination file in HDFS String dst = args[1];
We will create a InputStream using the BufferedInputStream object by using the first parameter which is the location of the file in the local file system. The input stream objects are regular java.io stream objects and not hadoop libraries because we are still referencing a file from the local file system and not HDFS.
//Input stream for the file in local file system to be written to HDFS InputStream in = new BufferedInputStream(new FileInputStream(localSrc));
Now we need to create an output stream to the file location in HDFS where we can write the contents of the file from the local file system. The very first thing we need to know is few key information about the cluster, like the name node details etc. The details are already specified in the configuration files during cluster setup.
The easiest way to get the configuration of the cluster is by instantiating the Configuration object and this will read the configuration files from the classpath and read and load all the information that is needed by the program.
//Get configuration of Hadoop system Configuration conf = new Configuration(); System.out.println("Connecting to -- "+conf.get("fs.defaultFS")); //Destination file in HDFS FileSystem fs = FileSystem.get(URI.create(dst), conf); OutputStream out = fs.create(new Path(dst)); In the next line we will get the File System object using the URL that we passed as the program’s input and the configuration that we just created. The file system that will be returned is the DistributedFileSystem object. Once we have the file system object the next thing we need is the outputstream to the file that we would like to write the contents of the file from the local file system.
We will then call the create method on the file system object using the location of the file in HDFS which we passed to the program as the second parameter.
//Copy file from local to HDFS IOUtils.copyBytes(in, out, 4096, true);
Finally we will use copyBytes method from hadoop’s IOUtils class and we will supply the input and output stream object. We will then read 4096 bytes at a time from the input stream and write it to the output stream which will copy the entire file from the local file system to HDFS.