Thread Pools
Most of the executor implementations in java.util.concurrent use thread pools, which consist of worker threads. This kind of thread exists separately from the Runnable and Callable tasks it executes and is often used to execute multiple tasks.
Using worker threads minimizes the overhead due to thread creation. Thread objects use a significant amount of memory, and in a large-scale application, allocating and deallocating many thread objects creates a significant memory management overhead.
One common type of thread pool is the fixed thread pool. This type of pool always has a specified number of threads running; if a thread is somehow terminated while it is still in use, it is automatically replaced with a new thread. Tasks are submitted to the pool via an internal queue, which holds extra tasks whenever there are more active tasks than threads.
An important advantage of the fixed thread pool is that applications using it degrade gracefully. To understand this, consider a web server application where each HTTP request is handled by a separate thread. If the application simply creates a new thread for every new HTTP request, and the system receives more requests than it can handle immediately, the application will suddenly stop responding to all requests when the overhead of all those threads exceed the capacity of the system. With a limit on the number of the threads that can be created, the application will not be servicing HTTP requests as quickly as they come in, but it will be servicing them as quickly as the system can sustain.
A simple way to create an executor that uses a fixed thread pool is to invoke the newFixedThreadPool factory method in java.util.concurrent.Executors This class also provides the following factory methods:
- The newCachedThreadPool method creates an executor with an expandable thread pool. This executor is suitable for applications that launch many short-lived tasks.
- The newSingleThreadExecutor method creates an executor that executes a single task at a time.
- Several factory methods are ScheduledExecutorService versions of the above executors.
If none of the executors provided by the above factory methods meet your needs, constructing instances of java.util.concurrent.ThreadPoolExecutor or java.util.concurrent.ScheduledThreadPoolExecutor will give you additional options.
Class ThreadPoolExecutor
An ExecutorService that executes each submitted task using one of possibly several pooled threads, normally configured using Executors factory methods.
Thread pools address two different problems: they usually provide improved performance when executing large numbers of asynchronous tasks, due to reduced per-task invocation overhead, and they provide a means of bounding and managing the resources, including threads, consumed when executing a collection of tasks. Each ThreadPoolExecutor also maintains some basic statistics, such as the number of completed tasks.
- If fewer than corePoolSize threads are running, the Executor always prefers adding a new thread rather than queuing.
- If corePoolSize or more threads are running, the Executor always prefers queuing a request rather than adding a new thread.
- If a request cannot be queued, a new thread is created unless this would exceed maximumPoolSize, in which case, the task will be rejected.
- Direct handoffs. A good default choice for a work queue is a SynchronousQueue that hands off tasks to threads without otherwise holding them. Here, an attempt to queue a task will fail if no threads are immediately available to run it, so a new thread will be constructed. This policy avoids lockups when handling sets of requests that might have internal dependencies. Direct handoffs generally require unbounded maximumPoolSizes to avoid rejection of new submitted tasks. This in turn admits the possibility of unbounded thread growth when commands continue to arrive on average faster than they can be processed.
- Unbounded queues. Using an unbounded queue (for example a LinkedBlockingQueue without a predefined capacity) will cause new tasks to wait in the queue when all corePoolSize threads are busy. Thus, no more than corePoolSize threads will ever be created. (And the value of the maximumPoolSize therefore doesn’t have any effect.) This may be appropriate when each task is completely independent of others, so tasks cannot affect each others execution; for example, in a web page server. While this style of queuing can be useful in smoothing out transient bursts of requests, it admits the possibility of unbounded work queue growth when commands continue to arrive on average faster than they can be processed.
- Bounded queues. A bounded queue (for example, an ArrayBlockingQueue ) helps prevent resource exhaustion when used with finite maximumPoolSizes, but can be more difficult to tune and control. Queue sizes and maximum pool sizes may be traded off for each other: Using large queues and small pools minimizes CPU usage, OS resources, and context-switching overhead, but can lead to artificially low throughput. If tasks frequently block (for example if they are I/O bound), a system may be able to schedule time for more threads than you otherwise allow. Use of small queues generally requires larger pool sizes, which keeps CPUs busier but may encounter unacceptable scheduling overhead, which also decreases throughput.
- In the default ThreadPoolExecutor.AbortPolicy , the handler throws a runtime RejectedExecutionException upon rejection.
- In ThreadPoolExecutor.CallerRunsPolicy , the thread that invokes execute itself runs the task. This provides a simple feedback control mechanism that will slow down the rate that new tasks are submitted.
- In ThreadPoolExecutor.DiscardPolicy , a task that cannot be executed is simply dropped. This policy is designed only for those rare cases in which task completion is never relied upon.
- In ThreadPoolExecutor.DiscardOldestPolicy , if the executor is not shut down, the task at the head of the work queue is dropped, and then execution is retried (which can fail again, causing this to be repeated.) This policy is rarely acceptable. In nearly all cases, you should also cancel the task to cause an exception in any component waiting for its completion, and/or log the failure, as illustrated in ThreadPoolExecutor.DiscardOldestPolicy documentation.
If hook, callback, or BlockingQueue methods throw exceptions, internal worker threads may in turn fail, abruptly terminate, and possibly be replaced.
Queue maintenance Method getQueue() allows access to the work queue for purposes of monitoring and debugging. Use of this method for any other purpose is strongly discouraged. Two supplied methods, remove(Runnable) and purge() are available to assist in storage reclamation when large numbers of queued tasks become cancelled. Reclamation A pool that is no longer referenced in a program AND has no remaining threads may be reclaimed (garbage collected) without being explicitly shutdown. You can configure a pool to allow all unused threads to eventually die by setting appropriate keep-alive times, using a lower bound of zero core threads and/or setting allowCoreThreadTimeOut(boolean) .
Extension example. Most extensions of this class override one or more of the protected hook methods. For example, here is a subclass that adds a simple pause/resume feature:
class PausableThreadPoolExecutor extends ThreadPoolExecutor < private boolean isPaused; private ReentrantLock pauseLock = new ReentrantLock(); private Condition unpaused = pauseLock.newCondition(); public PausableThreadPoolExecutor(. ) < super(. ); >protected void beforeExecute(Thread t, Runnable r) < super.beforeExecute(t, r); pauseLock.lock(); try < while (isPaused) unpaused.await(); >catch (InterruptedException ie) < t.interrupt(); >finally < pauseLock.unlock(); >> public void pause() < pauseLock.lock(); try < isPaused = true; >finally < pauseLock.unlock(); >> public void resume() < pauseLock.lock(); try < isPaused = false; unpaused.signalAll(); >finally < pauseLock.unlock(); >> > Как это работает в мире java. Пул потоков
Основной принцип программирования гласит: не изобретать велосипед. Но иногда, чтобы понять, что происходит и как использовать инструмент неправильно, нам нужно это сделать. Сегодня изобретаем паттерн многопоточного выполнения задач.
Представим, что у вас которая вызывает большую загрузку процессора:
public class Counter < public Double count(double a) < for (int i = 0; i < 1000000; i++) < a = a + Math.tan(a); >return a; > >Мы хотим как можно быстрее обработать ряд таких задач, попробуем*:
public class SingleThreadClient < public static void main(String[] args) < Counter counter = new Counter(); long start = System.nanoTime(); double value = 0; for (int i = 0; i < 400; i++) < value += counter.count(i); >System.out.println(format("Executed by %d s, value : %f", (System.nanoTime() - start) / (1000_000_000), value)); > >На моей тачке с 4 физическими ядрами использование ресурсов процессора top -pid :

Как вы заметили, загрузка одного процессора на один java-процесс с одним выполняемым потоком составляет 100%, но общая загрузка процессора в пользовательском пространстве составляет всего 2,5%, и у нас есть много неиспользуемых системных ресурсов.
Давайте попробуем использовать больше, добавив больше рабочих потоков:
public class MultithreadClient < public static void main(String[] args) throws ExecutionException, InterruptedException < ExecutorService threadPool = Executors.newFixedThreadPool(8); Counter counter = new Counter(); long start = System.nanoTime(); List> futures = new ArrayList<>(); for (int i = 0; i < 400; i++) < final int j = i; futures.add( CompletableFuture.supplyAsync( () ->counter.count(j), threadPool )); > double value = 0; for (Future future : futures) < value += future.get(); >System.out.println(format("Executed by %d s, value : %f", (System.nanoTime() - start) / (1000_000_000), value)); threadPool.shutdown(); > >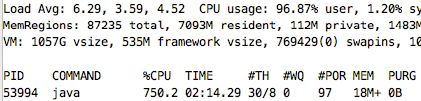
ThreadPoolExecutor
Для ускорения мы использовали ThreadPool — в java его роль играет ThreadPoolExecutor, который может быть реализован непосредственно или из одного из методов в классе Utilities. Если мы заглянем внутрь ThreadPoolExecutor, мы можем найти очередь:
private final BlockingQueue workQueue;в которой задачи собираются, если запущено больше потоков чем размер начального пула. Если запущено меньше потоков начального размера пула, пул попробует стартовать новый поток:
public void execute(Runnable command) < . if (workerCountOf(c) < corePoolSize) < if (addWorker(command, true)) return; . if (isRunning(c) && workQueue.offer(command)) < . addWorker(null, false); . >>Каждый addWorker запускает новый поток с задачей Runnable, которая опрашивает workQueue на наличие новых задач и выполняет их.
final void runWorker(Worker w)
ThreadPoolExecutor имеет очень понятный javadoc, поэтому нет смысла его перефразировать. Вместо этого, давайте попробуем сделать наш собственный:
public class ThreadPool implements Executor < private final QueueworkQueue = new ConcurrentLinkedQueue<>(); private volatile boolean isRunning = true; public ThreadPool(int nThreads) < for (int i = 0; i < nThreads; i++) < new Thread(new TaskWorker()).start(); >> @Override public void execute(Runnable command) < if (isRunning) < workQueue.offer(command); >> public void shutdown() < isRunning = false; >private final class TaskWorker implements Runnable < @Override public void run() < while (isRunning) < Runnable nextTask = workQueue.poll(); if (nextTask != null) < nextTask.run(); >> > > >Теперь давайте выполним ту же задачу, что и выше, с нашим пулом.
Меняем строку в MultithreadClient:
// ExecutorService threadPool = Executors.newFixedThreadPool (8); ThreadPool threadPool = new ThreadPool (8);Время выполнения практически одинаковое — 15 секунд.
Размер пула потоков
Попробуем еще больше увеличить количество запущенных потоков в пуле — до 100.
ThreadPool threadPool = new ThreadPool(100);Мы можем видеть, что время выполнения увеличилось до 28 секунд — почему это произошло?
Существует несколько независимых причин, по которым производительность могла упасть, например, из-за постоянных переключений контекста процессора, когда он приостанавливает работу над одной задачей и должен переключаться на другую, переключение включает сохранение состояния и восстановление состояния. Пока процессор занято переключением состояний, оно не делает никакой полезной работы над какой-либо задачей.
Количество переключений контекста процесса можно увидеть, посмотрев на csw параметр при выводе команды top.
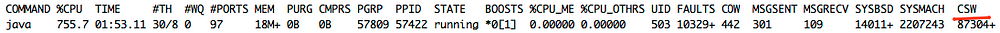
На 8 потоках:
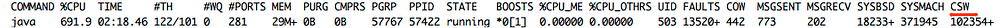
На 100 потоках:
Размер зависит от типа выполняемых задач. Разумеется, размер пула потоков редко должен быть захардокожен, скорее он должен быть настраиваемый а оптимальный размер выводится из мониторинга пропускной способности исполняемых задач.
Предполагая, что потоки не блокируют друг друга, нет циклов ожидания I/O, и время обработки задач одинаково, оптимальный пул потоков = Runtime.getRuntime().availableProcessors() + 1.
Если потоки в основном ожидают I/O, то оптимальный размер пула должен быть увеличен на отношение между временем ожидания процесса и временем вычисления. Например. У нас есть процесс, который тратит 50% времени в iowait, тогда размер пула может быть 2 * Runtime.getRuntime().availableProcessors() + 1.
Другие виды пулов
- Пул потоков с ограничением по памяти, который блокирует отправку задачи, когда в очереди слишком много задач MemoryAwareThreadPoolExecutor
- Пул потоков, который регистрирует JMX-компонент для контроля и настройки размера пула в runtime.
JMXEnabledThreadPoolExecutor