Анализ дампа кучи Java: разбираем на примерах

Я увлекаюсь управлением памятью в Java и в этой статье попробую объяснить, как взять и проанализировать дамп кучи – разберём на примерах. Но для начала давайте вспомним, что известно об этой предметной области. Немного освежив теорию, мы возьмем дамп кучи и проанализируем, каким он получится в простом приложении.
❯ Что такое куча?
Всякий раз, когда вы создаете объект, он хранится в области памяти, которая в приложениях для JVM называется «куча». Как вы уже догадались, объем кучи ограничен, и «кто-то» должен хранить объекты в куче. Этот инструмент называется сборщиком мусора ( Garbage Collector ). Сборщик мусора подбирает в куче неиспользуемые объекты, после чего уничтожает их в соответствии с определённым алгоритмом, так, чтобы в куче всегда имелась свободная память.
Но, как только всё свободное место в куче будет израсходовано, вы получите:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap spaceСборщик мусора подбирает только те объекты, на которые нет ссылок, но иногда это могут быть и объекты со ссылками, но такие, которые вообще не применяются в приложении. Такая практика всегда приводит к утечке памяти в приложении. Чтобы обнаружить такую проблему и понять, что происходит в куче, мы выводим дамп кучи. Давайте рассмотрим, как сделать дамп кучи для конкретного приложения.
❯ Захват дампа кучи
Если вы читали статью об анализе дампа потоков Java, то рассматриваемая в этом разделе тема с захватом дампа кучи вам уже знакома. Чтобы вы смогли самостоятельно собрать дамп кучи, приведу здесь пример. Те же команды вы можете выполнять у себя на компьютере; подобные примеры встречаются в Gradle. В этой статье я покажу 3 типа захвата дампа кучи; VisualVM, jmap и автоматический дамп кучи с опциями JVM. Давайте постепенно разберём каждый из методов, но сначала скопируйте проект с примером.
О проекте
Вышеупомянутый тренировочный проект можно скопировать здесь. Перейдя в папку heapdumpanalysis, вы найдёте следующие классы в каталоге java source.
package com.huseyin.heapdumpanalysis; import java.util.ArrayList; import java.util.List; import lombok.extern.slf4j.Slf4j; @Slf4j public class ProductCatalogService < public ListgetProducts(int limit) < Listproducts = new ArrayList<>(); for (int i = 0; i < limit; i++)< products.add(new String(new char[1024*1000])); // 1 MB string >return products; > >Этот класс предназначен для генерации списка продуктов (на самом деле это просто строки), и каждый продукт имеет размер 1 МБ. А вот второй класс:
package com.huseyin.heapdumpanalysis; import java.util.Arrays; import java.util.List; public class HeapDump < public static void main(String[] args) throws InterruptedException < int count = Integer.parseInt(args[0]); int waitTime = Integer.parseInt(args[1]); System.out.println("Loading products. "); Listproducts = new ProductCatalogService().getProducts(count); System.out.println(products.size() + " products are loaded into memory."); Thread.sleep(waitTime * 1000L); > >Он нужен для запуска приложения, чтобы сгенерировать список продуктов. Класс будет потреблять память в том количестве, которое вы зададите в аргументах команды Gradle следующим образом.
JAVA_TOOL_OPTIONS=-Xmx200m \ ./gradlew :heapdumpanalysis:run \ -PmainClass=com.huseyin.heapdumpanalysis.HeapDump \ --args="180 30"В JAVA_TOOL_OPTIONS можно указать аргументы JVM, в соответствии с которыми Gradle мог бы подобрать и использовать эти аргументы во время операции ветвления JVM. В нашем случае мы указываем -Xmx200m; что означает, что максимальная емкость кучи будет 200 МБ. Более того, если вы ссылаетесь на объекты размером > ~ 200 МБ, то получите исключение java.lang.OutOfMemoryError , и приложение завершит работу. Я использовал ~ 200 МБ, поскольку куча также содержит некоторые классы из среды выполнения Java, и то пространство в 200 МБ (JRE Classes) – вот и весь объём для объектов в вашем приложении.
—args — это список аргументов, которые мы можем прочитать из java-приложения с помощью args[0], и здесь в первом пункте указывается размер продуктов. Например, мы генерируем 180 продуктов, то есть, 180 МБ данных (1М для каждого продукта). Второй аргумент — время ожидания в секундах. 30 означает, что как только приложение сгенерирует продукты, оно будет ждать 30 секунд до завершения выполнения. Это нужно, чтобы вы могли получить дамп кучи запущенного приложения. Теперь, когда мы знаем, как выполнить приложение, давайте посмотрим, как можно снять дамп кучи с помощью Visual VM.
Снятие дампа кучи с помощью VisualVM
VisualVM — это инструмент с GUI, сочетающий инструменты командной строки JDK и обеспечивающий удобное профилирование. Инструмент мет использоваться как на стадии разработки, так и в продакшене.
Главная страница Visual VM
Скачав Visual VM отсюда, вы cможете просмотреть запущенные приложения JVM. Откройте VisualVM и проверьте их следующим образом:
Стартовый экран Visual VM
Как только вы откроете приложение, запущенное после выполнения в Gradle, можно будет просмотреть его метаданные. Перейдите во вкладку Monitor, где выводится использование кучи.

Использование кучи
Синий участок на диаграмме — это используемая часть кучи, а коричневый — память кучи, доступная для вашего приложения. Если нужно вывести дамп кучи, нажмите Heap Dump в правом верхнем углу страницы Monitor. Вы увидите еще одно окно со сведениями о дампе кучи, как показано ниже.
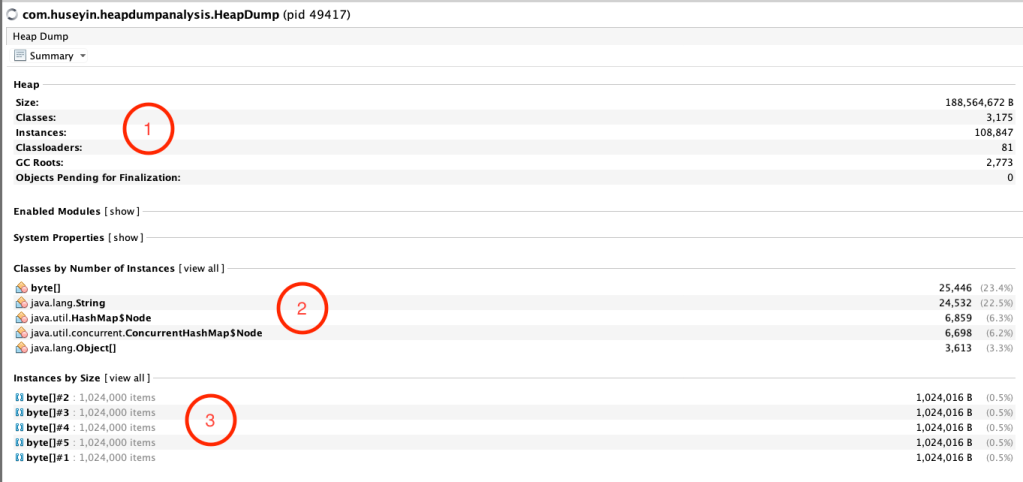
Сведения о дампе кучи – 1
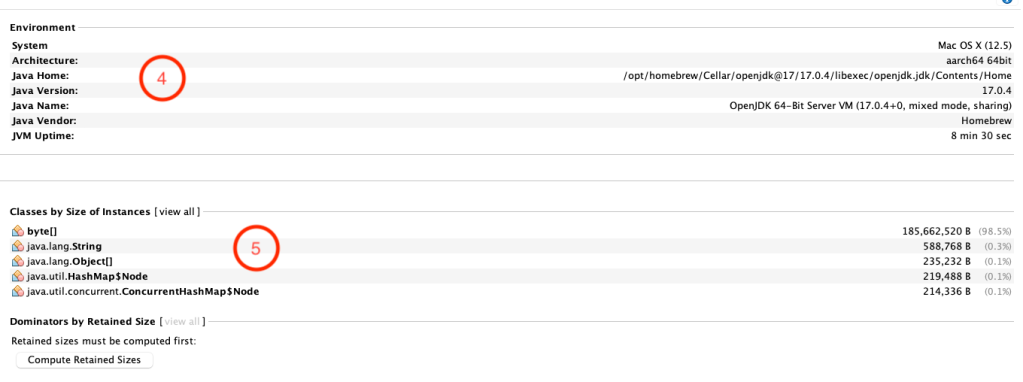
Сведения о дампе кучи – 2
- Можно просмотреть в агрегированном виде некоторые данные о размере, количестве классов, экземплярах и т. д.
- Здесь Visual VM показывает, сколько экземпляров каждого типа класса у нас имеется. Видим, что в данном приложении больше всего экземпляров у byte[].
- В этом разделе выводится каждый экземпляр и его размер. Как видите, размер каждого файла — 1024 байта, всего получается 1 МБ, это наш продукт.
- Эта часть содержит информацию о рабочем окружении вашего компьютера и о дистрибутиве java.
- Похож на раздел 2, но на этот раз с упорядочиванием по размеру экземпляров, а не по их количеству.
Снятие дампа кучи с помощью jmap
Программа jmap поставляется с дистрибутивом JDK. С её помощью можете получить дамп кучи, сначала найдя идентификатор процесса JVM, а затем сняв дамп кучи следующим образом.

Список процессов JVM
Теперь для снятия дампа кучи выполним:
jmap -dump:live,file=/tmp/heapdump.hprof 49417Так удастся снять дамп кучи и сохранить результаты в /tmp/heapdump.hprof. Здесь команда jmap снимает дамп кучи, для этого мы задаём опцию –dump. Также мы собираемся взять только живой объект с помощью опции :live. Вдобавок jmap принимает параметр file для сохранения результатов в указанном месте. Наконец, принимается идентификатор процесса JVM для анализа кучи. Что же дальше? Что мы будем делать с этим файлом heapdump.hprof? Этот файл не составит труда загрузить в VisualVM следующим образом.
Загрузить
Только файлы hprof
Остальные операции точно такие же, как рассмотренные в предыдущем разделе.
В VisualVM удобно выполнять элементарные операции, но мне ещё нравится инструмент MAT (Eclipse Memory Analyzer). Он также заслуживает отдельной статьи, описывающей best practices :). С документацией по этому инструменту можно ознакомиться здесь.
Автоматический анализ дампа кучи
Во всех примерах, рассмотренных выше, собирали дамп кучи вручную. Однако на практике такой подход может оказаться нецелесообразным по следующим причинам;
- У вас могут быть десятки и сотни приложений JVM
- Возможно, уже произошёл аварийный останов приложения
-XX:+HeapDumpOnOutOfMemoryError \ -XX:HeapDumpPath=/tmp/heapdump.hprofПрименительно к нашему приложению, можно использовать следующую команду Gradle.
JAVA_TOOL_OPTIONS="-Xmx200m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof" \ ./gradlew :heapdumpanalysis:run \ -PmainClass=com.huseyin.heapdumpanalysis.HeapDump \ --args="210 30"Поскольку мы предоставляем кучу объёмом 200MB и пытаемся сгенерировать список товаров общим объемом 210MB , в результате получим OutOfMemoryError , и JVM выведет дамп имеющейся кучи, затем сохранит его в файле /tmp/heapdump.hprof
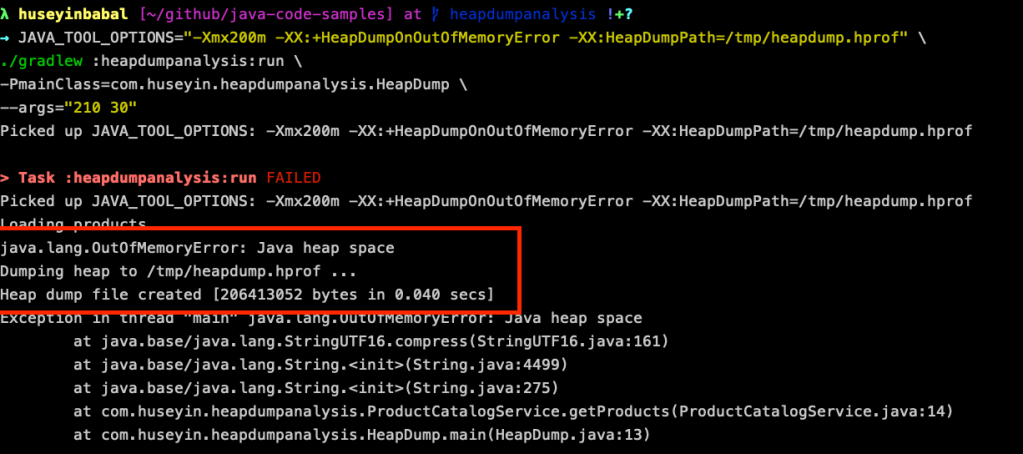
Автоматический анализ дампа кучи
Особенно при работе с облачно-нативными системами, где JVM-процесс контейнеризован (в микросервисных системах могут насчитываться десятки и сотни контейнеров), разумно было бы сконфигурировать этот параметр для автоматического создания дампа кучи. Однако необходимо смонтировать специальный каталог, прикрепив его к этим контейнерам, иначе файл с результатами дампа кучи исчезнет из контейнера после перезапуска этого контейнера.
❯ Заключение
Важно обеспечить хорошую отслеживаемость процесса JVM, чтобы понять, как он протекает в вашем приложении. Чтобы понять, как это происходит, можно обратить внимание на кучу, где находятся все java-объекты. Мы используем методы снятия дампа кучи, и можно выбрать один или несколько таких методов при работе в имеющейся экосистеме приложений JVM.
Если хотите склонировать проект, рассмотренный в этой статье – он находится здесь.
