- How to Download a File from URL in Java
- Overview
- Using Plain Java IO
- Using BufferedInputStream
- Using Files.copy()
- Using Java NIO
- Using Java HttpClient
- Using Java HttpClient Asynchronously
- Using Apache Commons IO
- Summary
- Top 5 ways to Download a File from any given URL in Java?
- There are 5 different ways you could download files from any given URL in Java.
- Create java class: CrunchifyDownloadFileFromURL.java
- Just run above program and you will result as below.
- Method-1) File Download using apache commons-io
- Method-2) File Download using Stream Operation
- Method-3) File Download using NIO Operation
- Method-4) File Download using Files.copy()
- Method-5) File Download using Apache HttpComponents()
- Suggested Articles.
How to Download a File from URL in Java
This article covers different ways to Read and Download a File from an URL in Java and store it on disk, which includes plain Java IO, NIO, HttpClient, and Apache Commons Library.
Overview
There are a number of ways, we can download a file from a URL on the internet. This article will help you understand them with the help of examples.
We will begin by using BufferedInputStream and Files.copy() methods in Plain Java. Next, we will see how to achieve the same using the Java NIO package. Also, we will see how to use HttpClient, which provides a Non-Blocking way of downloading a file. Finally, we will use the third-party library of Apache Commons IO to download a file.
Using Plain Java IO
First, we will see an example of using Java IO to download a file. The Java IO provides APIs to read bytes from InputStream and write them to a File on disk. While the Java NET package provides APIs to interact with a resource residing over the internet with the help of a URL.
In order to use Java IO and Java NET, we need to use java.io.* and java.net.* packages into our class.
Using BufferedInputStream
Next is a simple example of using Java IO and Java NET to read a file from a URL. Here, we are using BufferedInputStream to download a file.
URL url = new URL("https://www.google.com/"); try ( InputStream inputStream = url.openStream(); BufferedInputStream bufferedInputStream = new BufferedInputStream(inputStream); FileOutputStream fileOutputStream = new FileOutputStream(outputPath); ) < byte[] bucket = new byte[2048]; int numBytesRead; while ((numBytesRead = bufferedInputStream.read(bucket, 0, bucket.length)) != -1) < fileOutputStream.write(bucket, 0, numBytesRead); > >Code language: Java (java)At first, we created an URL instance by specifying the URL of the file or resource we want to download. Then, we opened an InputStream from the file using openStream method. Next, in order to be able to download large files we wrapped the input stream into a BufferedInputStream. Also, we created a FileOutputStream by providing a path on the disk where we want the file to be saved.
Next, we use a bucket of byte[] to read 2048 bytes from the input stream and write it onto the output stream iteratively. This example demonstrates how we can use our own buffer (for example 2048 bytes) so that downloading large files should not consume huge memory on our system.
Note: While dealing with Java File IO, we must close all the open streams and readers. To do that, we have used the try-with-resources block for respective stream instantiation.
Using Files.copy()
While writing the previous example, we had to take care of a lot of logic. Thankfully, Java Files class provides the copy method which handles this logic internally.
Next is an example of using Files.copy() to download a file from a URL.
URL url = new URL("https://www.google.com"); try(InputStream inputStream = url.openStream()) Code language: Java (java)
Using Java NIO
The Java NIO package offers a faster way of data transfer, which does not buffer data in memory. Hence, we can easily work with large files. In order to use Java NIO channels, we need to create two channels. One channel will connect to the source and the other to the target. Once the channels are set, we can transfer data between them.
Next is an example of using NIO Channels to read a file on the internet.
URL url = new URL("https://www.google.com"); try ( ReadableByteChannel inputChannel = Channels.newChannel(url.openStream()); FileOutputStream fileOutputStream = new FileOutputStream(outputPath); FileChannel outputChannel = fileOutputStream.getChannel(); ) < outputChannel.transferFrom(inputChannel, 0, Long.MAX_VALUE); >Code language: Java (java)Using Java HttpClient
We can also use HttpClient provided by the Java NET package. Next, is an example of using HttpClient to download a file and save it on the disk.
HttpClient httpClient = HttpClient.newBuilder().build(); HttpRequest httpRequest = HttpRequest .newBuilder() .uri(new URI("https://www.google.com")) .GET() .build(); HttpResponse response = httpClient .send(httpRequest, responseInfo -> HttpResponse.BodySubscribers.ofInputStream()); Files.copy(response.body(), Paths.get(outputPath));Code language: Java (java)First, we simply create an instance of HttpClient using its builder. Next, we create HttpRequest by providing the URI, and HTTP GET method type. Then we invoke the request by attaching a BodyHandler, which returns a BodySubscriber of InputStream type. Finally, we use the input stream from the HttpResponse and use File#copy() method to write it to a Path on disk.
Using Java HttpClient Asynchronously
This section explains how to asynchronously download a file from a URL and save it to the disk. To do that, we can use sendAsync method of HttpClient, which will return a Future instance.
When we execute an asynchronous method, the program execution will not wait for the method to finish. Instead, it will progress further by doing other stuff. We can check on the future instance to see if the execution is finished and the response is ready.
The next block of code demonstrates using HttpClient which downloads a file asynchronously and saves it onto the disk.
HttpRequest httpRequest = HttpRequest .newBuilder() .uri(new URI("https://www.google.com")) .GET() .build(); Future futureInputStream = httpClient .sendAsync(httpRequest, HttpResponse.BodyHandlers.ofInputStream()) .thenApply(HttpResponse::body); InputStream inputStream = futureInputStream.get(); Files.copy(inputStream, Path.of(outputPath));Code language: Java (java)As it is shown in the example, we are sending an async request, which returns a Future of InputStream. the get method in the Future will be blocked until the input stream is ready. Finally, we use Files#copy method to write the file to disk.
Using Apache Commons IO
The Apache Commons IO library provides a number of useful abstractions for general-purpose File IO. In order to read a file from a URL and save it to disk, we can use copyURLToFile method provided by FileUtils class. Here is an example of using Apache Commons IO to read a file from a URL and save it.
URL url = new URL("https://www.google.com"); FileUtils.copyURLToFile(url, new File(outputPath));Code language: Java (java)This looks a lot simpler and short. The copyURLToFile method internally uses IOUtils.copy method (as explained in Using Apache Commons IO to copy InputStream to OutputStream). Thus, we do not need to manually read buffers from the input stream and write on the output stream.
Alternatively, we can use another flavour of this method which allows us to set connection timeout, and read timeout values.
public static void copyURLToFile( URL source, File destination, int connectionTimeout, int readTimeout) throws IOException Code language: Java (java)The snippet shows the signature of the method that we can use along with specific timeout values.
Summary
In this article, we understood How to Download a File from a URL and store it on the disk. We have covered different ways of doing this, which include using Plain Java IO and Java NET combination, using Java NIO package, using HTTP Client both synchronously and asynchronously, and finally using Apache Commons IO.
Refer to our GitHub Repository for the complete source code of the examples used in this tutorial.
Top 5 ways to Download a File from any given URL in Java?

In Java how to download files from any given URL? This tutorial works if you have any of below questions:
- Download a file from a URL in Java.
- How to Download a File from a URL in Java
- How to download and save a file from Internet using Java
- java download file from url Code Example
There are 5 different ways you could download files from any given URL in Java.
- File Download using apache commons-io. Single line of code.
- File Download using Stream Operation
- File Download using NIO Operation
- File Download using Files.copy()
- File Download using Apache HttpComponents()
Create java class: CrunchifyDownloadFileFromURL.java
package crunchify.com.tutorial; import org.apache.commons.io.FileUtils; import org.apache.http.HttpEntity; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import java.io.*; import java.net.URI; import java.net.URL; import java.nio.channels.Channels; import java.nio.channels.ReadableByteChannel; import java.nio.file.Files; import java.nio.file.Paths; import java.nio.file.StandardCopyOption; /** * @author Crunchify.com ** In Java How to Download file from any given URL? *
* 5 different ways: * 1. File Download using apache commons-io. Just line of code * 2. File Download using Stream Operation * 3. File Download using NIO Operation * 4. File Download using Files.copy() * 5. File Download using Apache HttpComponents() */ public class CrunchifyDownloadFileFromURL < public static void main(String[] args) < String crunchifyRobotsURL = "https://crunchify.com/robots.txt"; try < // Method-1: File Download using apache commons-io. Just line of code. crunchifyFileDownloadUsingApacheCommonsIO(crunchifyRobotsURL, "/Users/app/Download/robots_commons_io.txt"); // Method-2: File Download using Stream Operation crunchifyFileDownloadUsingStream(crunchifyRobotsURL, "/Users/app/Download/robots_stream.txt"); // Method-3: File Download using NIO Operation crunchifyFileDownloadUsingNIO(crunchifyRobotsURL, "/Users/app/Download/robots_nio.txt"); // Method-4: File Download using Files.copy() crunchifyFileDownloadUsingFilesCopy(crunchifyRobotsURL, "/Users/app/Download/robots_files_copy.txt"); // Method-5: File Download using Apache HttpComponents() crunchifyFileDownloadUsingHttpComponents(crunchifyRobotsURL, "/Users/app/Download/robots_httpcomponents.txt"); >catch (IOException crunchifyException) < crunchifyException.printStackTrace(); >> // Method-1: Using apache commons-io. Just single line of code. // FileUtils.copyURLToFile(URL, File); private static void crunchifyFileDownloadUsingApacheCommonsIO(String crunchifyURL, String crunchifyFileLocalPath) < URL crunchifyRobotsURL = null; try < crunchifyRobotsURL = new URL(crunchifyURL); FileUtils.copyURLToFile(crunchifyRobotsURL, new File(crunchifyFileLocalPath)); >catch (IOException e) < e.printStackTrace(); >printResult("File Downloaded Successfully with apache commons-io Operation \n"); > // Method-2: File Download using Stream Operation private static void crunchifyFileDownloadUsingStream(String crunchifyURL, String crunchifyFileLocalPath) throws IOException < URL crunchifyRobotsURL = new URL(crunchifyURL); // BufferedInputStream(): Creates a BufferedInputStream and saves its argument, the input stream in, for later use. An internal buffer array is created and stored in buf. BufferedInputStream crunchifyInputStream = new BufferedInputStream(crunchifyRobotsURL.openStream()); FileOutputStream crunchifyOutputStream = new FileOutputStream(crunchifyFileLocalPath); byte[] crunchifySpace = new byte[2048]; int crunchifyCounter = 0; while ((crunchifyCounter = crunchifyInputStream.read(crunchifySpace, 0, 1024)) != -1) < crunchifyOutputStream.write(crunchifySpace, 0, crunchifyCounter); >crunchifyOutputStream.close(); crunchifyInputStream.close(); printResult("File Downloaded Successfully with Java Stream Operation \n"); > // Method-3: File Download using NIO Operation private static void crunchifyFileDownloadUsingNIO(String crunchifyURL, String crunchifyFileLocalPath) throws IOException < URL crunchifyRobotsURL = new URL(crunchifyURL); // ReadableByteChannel(): A channel that can read bytes. Only one read operation upon a readable channel may be in progress at any given time. If one thread initiates a read operation upon a channel then any other thread that attempts to initiate another read operation will block until the first operation is complete. // Whether or not other kinds of I/O operations may proceed concurrently with a read operation depends upon the type of the channel. // openStream(): Opens a connection to this URL and returns an InputStream for reading from that connection. ReadableByteChannel crunchifyByteChannel = Channels.newChannel(crunchifyRobotsURL.openStream()); // FileOutputStream(): A file output stream is an output stream for writing data to a File or to a FileDescriptor. Whether or not a file is available or may be created depends upon the underlying platform. Some platforms, in particular, allow a file to be opened for writing by only one FileOutputStream (or other file-writing object) at a time. // In such situations the constructors in this class will fail if the file involved is already open. FileOutputStream crunchifyOutputStream = new FileOutputStream(crunchifyFileLocalPath); // getChannel(): Returns the unique FileChannel object associated with this file output stream. // transferFrom(): Transfers bytes into this channel's file from the given readable byte channel. // An attempt is made to read up to count bytes from the source channel and write them to this channel's file starting at the given position. An invocation of this method may or may not transfer all of the requested bytes; whether or not it does so depends upon the natures and states of the channels. // Fewer than the requested number of bytes will be transferred if the source channel has fewer than count bytes remaining, or if the source channel is non-blocking and has fewer than count bytes immediately available in its input buffer. crunchifyOutputStream.getChannel().transferFrom(crunchifyByteChannel, 0, Long.MAX_VALUE); // A constant holding the maximum value a long can have. // Closes this file output stream and releases any system resources associated with this stream. This file output stream may no longer be used for writing bytes. crunchifyOutputStream.close(); // Closes this channel. After a channel is closed, any further attempt to invoke I/O operations upon it will cause a ClosedChannelException to be thrown. crunchifyByteChannel.close(); printResult("File Downloaded Successfully with Java NIO ReadableByteChannel Operation \n"); >// Method-4: File Download using Files.copy() private static void crunchifyFileDownloadUsingFilesCopy(String crunchifyURL, String crunchifyFileLocalPath) < // URI Creates a URI by parsing the given string. // This convenience factory method works as if by invoking the URI(String) constructor; // any URISyntaxException thrown by the constructor is caught and wrapped in a new IllegalArgumentException object, which is then thrown. try (InputStream crunchifyInputStream = URI.create(crunchifyURL).toURL().openStream()) < // Files: This class consists exclusively of static methods that operate on files, directories, or other types of files. // copy() Copies all bytes from an input stream to a file. On return, the input stream will be at end of stream. // Paths: This class consists exclusively of static methods that return a Path by converting a path string or URI. // Paths.get() Converts a path string, or a sequence of strings that when joined form a path string, to a Path. Files.copy(crunchifyInputStream, Paths.get(crunchifyFileLocalPath), StandardCopyOption.REPLACE_EXISTING); >catch (IOException e) < // printStackTrace: Prints this throwable and its backtrace to the standard error stream. e.printStackTrace(); >printResult("File Downloaded Successfully with Files.copy() Operation \n"); > // Method-5: File Download using Apache HttpComponents() private static void crunchifyFileDownloadUsingHttpComponents(String crunchifyURL, String crunchifyFileLocalPath) < CloseableHttpClient crunchifyHTTPClient = HttpClients.createDefault(); HttpGet crunchifyHTTPGet = new HttpGet(crunchifyURL); CloseableHttpResponse crunchifyHTTPResponse = null; try < crunchifyHTTPResponse = crunchifyHTTPClient.execute(crunchifyHTTPGet); HttpEntity crunchifyHttpEntity = crunchifyHTTPResponse.getEntity(); if (crunchifyHttpEntity != null) < FileUtils.copyInputStreamToFile(crunchifyHttpEntity.getContent(), new File(crunchifyFileLocalPath)); >> catch (IOException e) < // IOException: Signals that an I/O exception of some sort has occurred. // This class is the general class of exceptions produced by failed or interrupted I/O operations. e.printStackTrace(); >printResult("File Downloaded Successfully with Apache HttpComponents() Operation \n"); > // Simple Crunchify Print Utility private static void printResult(String crunchifyResult) < System.out.println(crunchifyResult); >>
Just run above program and you will result as below.
File Downloaded Successfully with apache commons-io Operation File Downloaded Successfully with Java Stream Operation File Downloaded Successfully with Java NIO ReadableByteChannel Operation File Downloaded Successfully with Files.copy() Operation File Downloaded Successfully with Apache HttpComponents() Operation Process finished with exit code 0
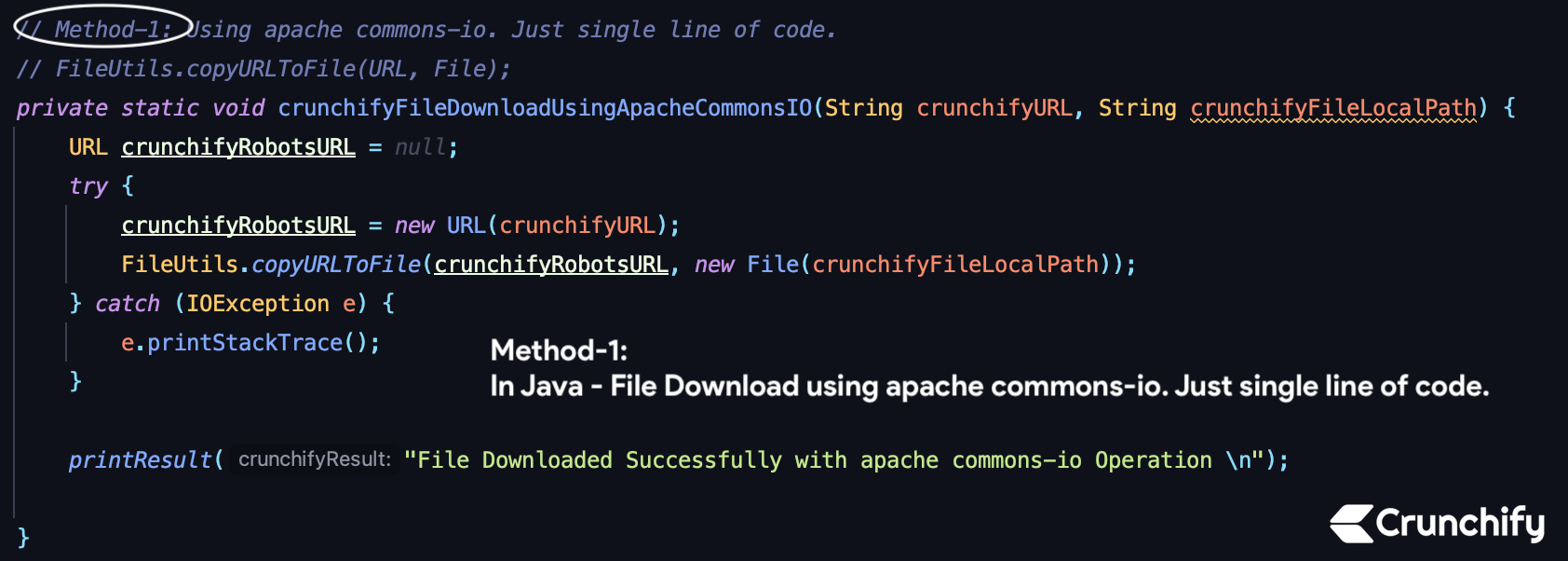
Method-1) File Download using apache commons-io
Please make sure to add below maven dependency into your pom.xml file.
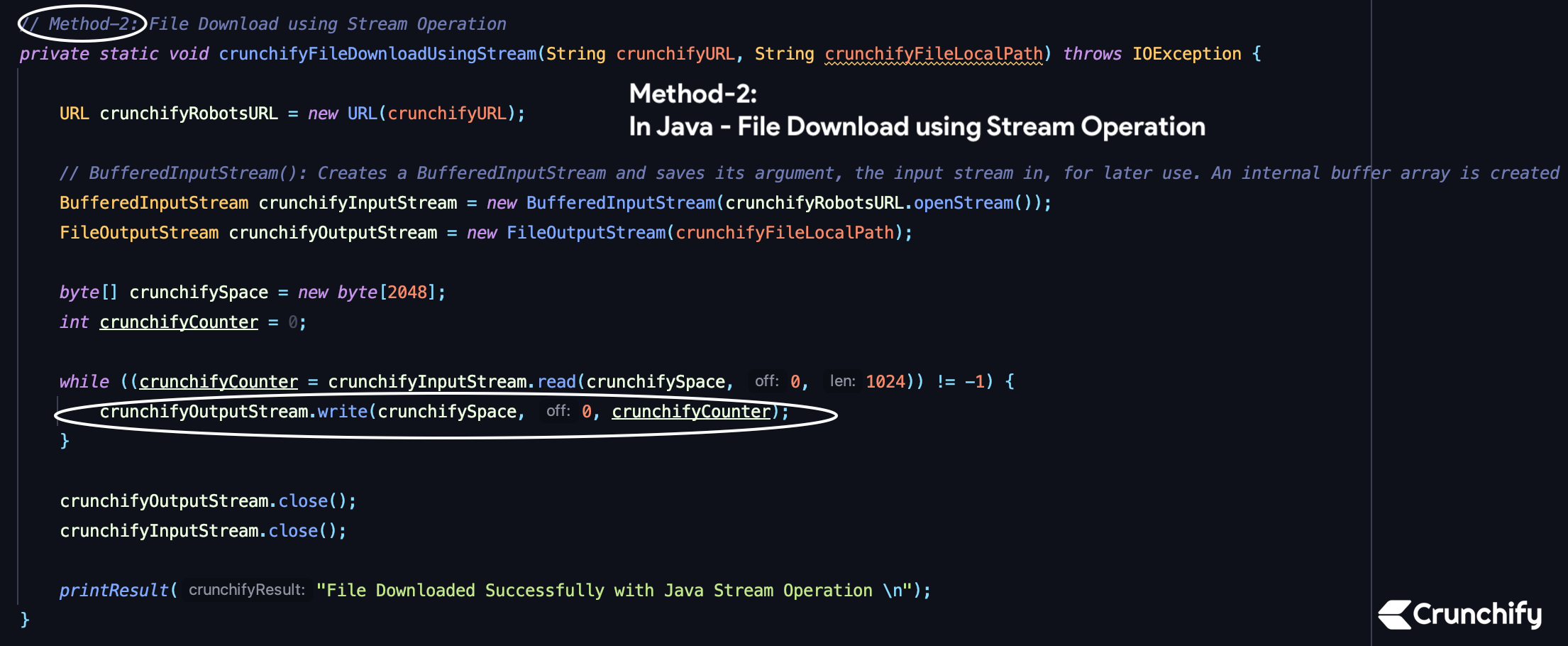
Method-2) File Download using Stream Operation
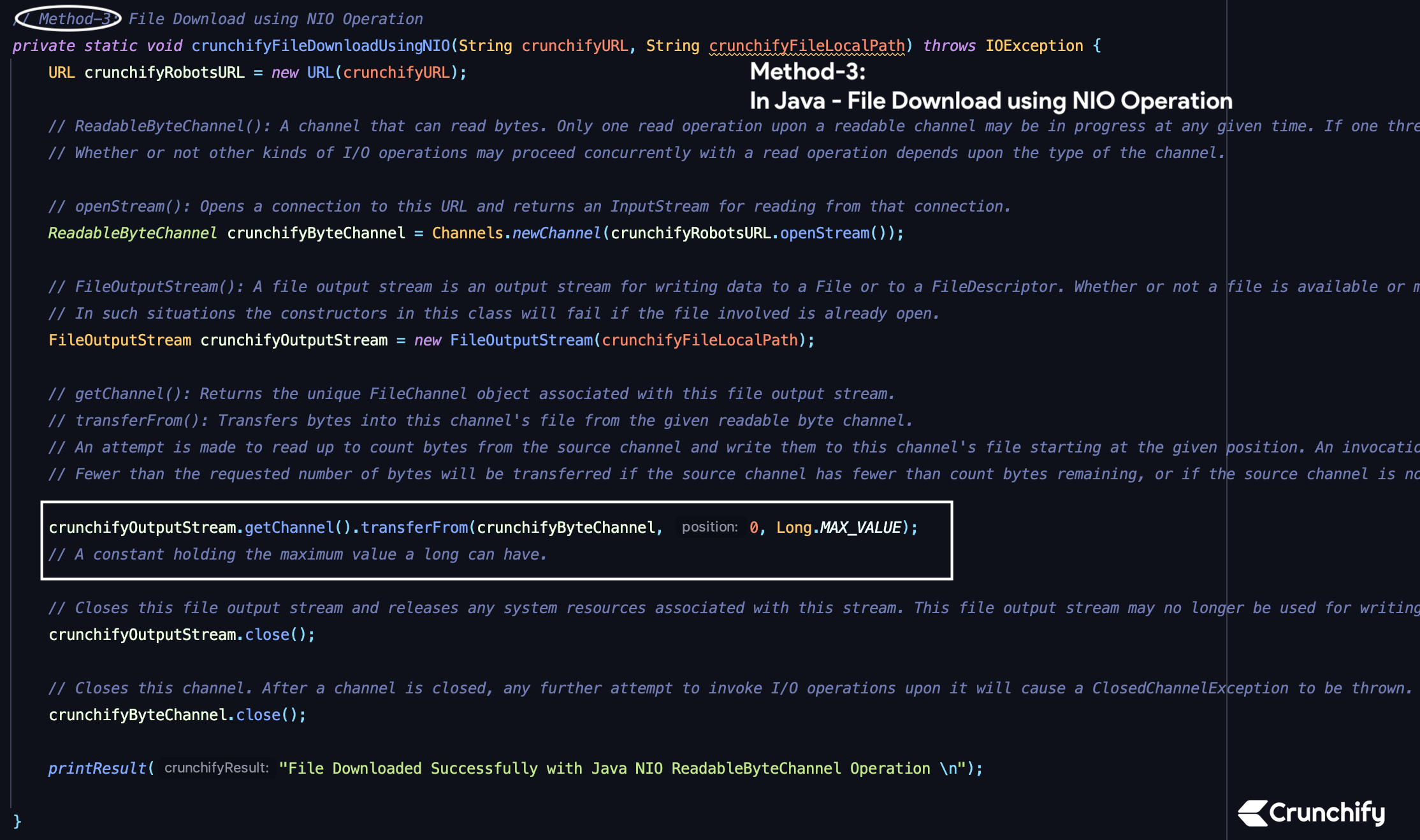
Method-3) File Download using NIO Operation
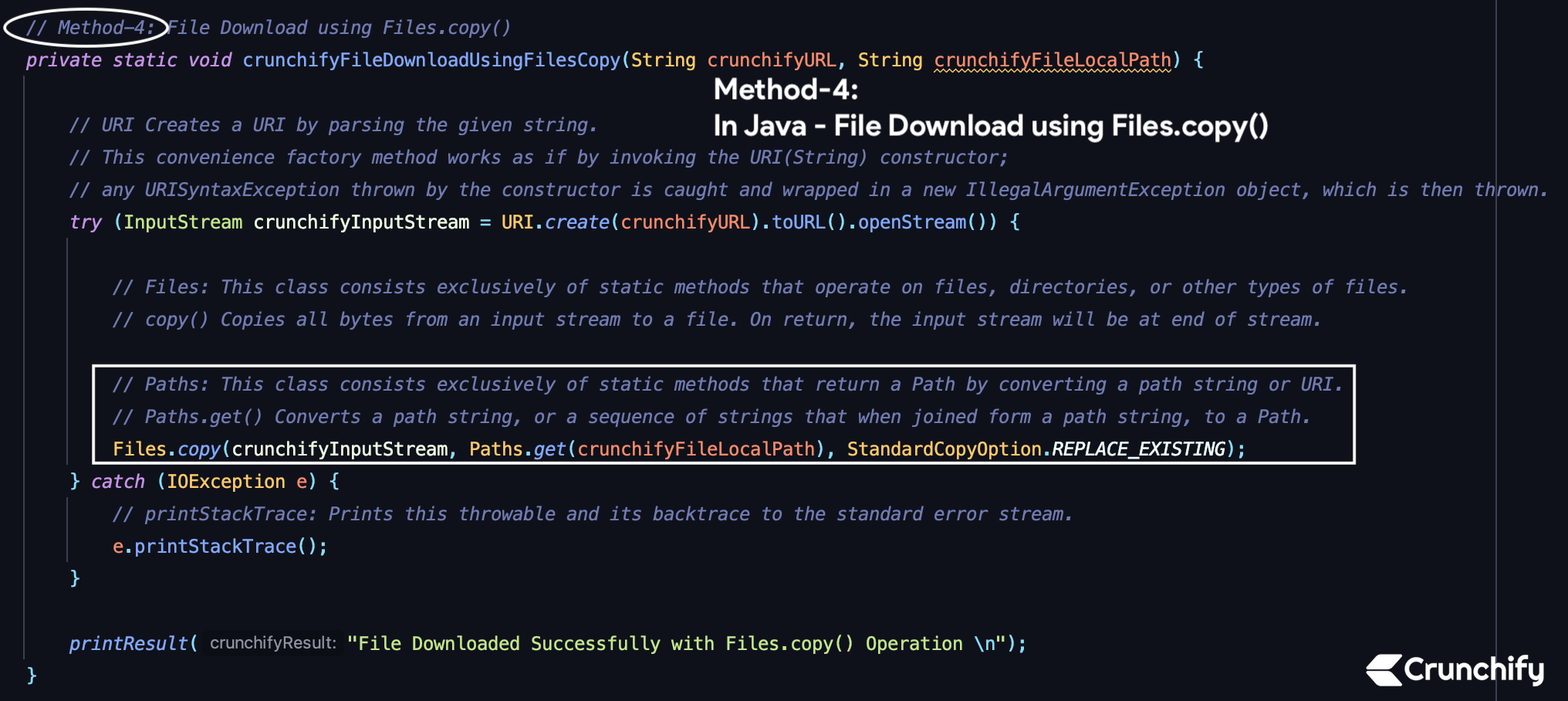
Method-4) File Download using Files.copy()
Method-5) File Download using Apache HttpComponents()
Please make sure to add below maven dependency into your pom.xml file.
org.apache.httpcomponents com.springsource.org.apache.httpcomponents.httpclient 4.2.1

Let me know if you face any issue or exception running above Java Program.
If you liked this article, then please share it on social media. Have a question or suggestion? Please leave a comment to start the discussion.