Java Regular Expressions
A regular expression is a sequence of characters that forms a search pattern. When you search for data in a text, you can use this search pattern to describe what you are searching for.
A regular expression can be a single character, or a more complicated pattern.
Regular expressions can be used to perform all types of text search and text replace operations.
Java does not have a built-in Regular Expression class, but we can import the java.util.regex package to work with regular expressions. The package includes the following classes:
- Pattern Class — Defines a pattern (to be used in a search)
- Matcher Class — Used to search for the pattern
- PatternSyntaxException Class — Indicates syntax error in a regular expression pattern
Example
Find out if there are any occurrences of the word «w3schools» in a sentence:
import java.util.regex.Matcher; import java.util.regex.Pattern; public class Main < public static void main(String[] args) < Pattern pattern = Pattern.compile("w3schools", Pattern.CASE_INSENSITIVE); Matcher matcher = pattern.matcher("Visit W3Schools!"); boolean matchFound = matcher.find(); if(matchFound) < System.out.println("Match found"); >else < System.out.println("Match not found"); >> > // Outputs Match found Example Explained
In this example, The word «w3schools» is being searched for in a sentence.
First, the pattern is created using the Pattern.compile() method. The first parameter indicates which pattern is being searched for and the second parameter has a flag to indicates that the search should be case-insensitive. The second parameter is optional.
The matcher() method is used to search for the pattern in a string. It returns a Matcher object which contains information about the search that was performed.
The find() method returns true if the pattern was found in the string and false if it was not found.
Flags
Flags in the compile() method change how the search is performed. Here are a few of them:
- Pattern.CASE_INSENSITIVE — The case of letters will be ignored when performing a search.
- Pattern.LITERAL — Special characters in the pattern will not have any special meaning and will be treated as ordinary characters when performing a search.
- Pattern.UNICODE_CASE — Use it together with the CASE_INSENSITIVE flag to also ignore the case of letters outside of the English alphabet
Regular Expression Patterns
The first parameter of the Pattern.compile() method is the pattern. It describes what is being searched for.
Brackets are used to find a range of characters:
| Expression | Description |
|---|---|
| [abc] | Find one character from the options between the brackets |
| [^abc] | Find one character NOT between the brackets |
| 2 | Find one character from the range 0 to 9 |
Metacharacters
Metacharacters are characters with a special meaning:
| Metacharacter | Description |
|---|---|
| | | Find a match for any one of the patterns separated by | as in: cat|dog|fish |
| . | Find just one instance of any character |
| ^ | Finds a match as the beginning of a string as in: ^Hello |
| $ | Finds a match at the end of the string as in: World$ |
| \d | Find a digit |
| \s | Find a whitespace character |
| \b | Find a match at the beginning of a word like this: \bWORD, or at the end of a word like this: WORD\b |
| \uxxxx | Find the Unicode character specified by the hexadecimal number xxxx |
Quantifiers
Quantifiers define quantities:
| Quantifier | Description |
|---|---|
| n+ | Matches any string that contains at least one n |
| n* | Matches any string that contains zero or more occurrences of n |
| n? | Matches any string that contains zero or one occurrences of n |
| n | Matches any string that contains a sequence of X n‘s |
| n | Matches any string that contains a sequence of X to Y n‘s |
| n | Matches any string that contains a sequence of at least X n‘s |
Matches
A match is a part of the string which matches a pattern. After using the Matcher ‘s find() method, the group() method will return the part of the string that was found.
Example
import java.util.regex.Matcher; import java.util.regex.Pattern; public class MyClass < public static void main(String[] args) < Pattern pattern = Pattern.compile("w3schools", Pattern.CASE_INSENSITIVE); Matcher matcher = pattern.matcher("Visit W3Schools!"); if(matcher.find()) < String match = matcher.group(); System.out.println(match); >> > // Outputs W3Schools Each call to find() will search for the next match in the string until no more matches are found. This can be used to find all of the matches in a string and not just the first one.
Example
Use find() and group() to list all numbers found in a sentence.
import java.util.regex.Matcher; import java.util.regex.Pattern; public class MyClass < public static void main(String[] args) < Pattern pattern = Pattern.compile("w3schools", Pattern.CASE_INSENSITIVE); Matcher matcher = pattern.matcher("Visit W3Schools!"); if(matcher.find()) < String match = matcher.group(); System.out.println(match); >> > // Outputs W3Schools Groups
In regular expressions, groups are delimited by parentheses ( ) . Groups can be used to apply quantifiers to entire patterns and can be used to select part of a matched pattern.
The Matcher object’s group() method can be used to show only the part of the match which belongs to a group.
Using 0 as a parameter in the group() method returns a match of the whole pattern, while 1, 2 and so on will return matches of the groups given by the order of their opening parentheses in the pattern.
Example
Use find() and group() to list all numbers found in a sentence.
import java.util.regex.Matcher; import java.util.regex.Pattern; public class MyClass < public static void main(String[] args) < Pattern pattern = Pattern.compile("w3schools", Pattern.CASE_INSENSITIVE); Matcher matcher = pattern.matcher("Visit W3Schools!"); if(matcher.find()) < String match = matcher.group(); System.out.println(match); >> > // Outputs W3Schools Обработка строк в Java. Часть II: Pattern, Matcher
Что Вы знаете о обработке строк в Java? Как много этих знаний и насколько они углублены и актуальны? Давайте попробуем вместе со мной разобрать все вопросы, связанные с этой важной, фундаментальной и часто используемой частью языка. Наш маленький гайд будет разбит на две публикации:
Регулярные выражения
Регулярные выражения (regular expressions, далее РВ) — мощное и эффективное средство для обработки текста. Они впервые были использованы в текстовых редакторах операционной системы UNIX (ed и QED) и сделали прорыв в электронной обработке текстов конца XX века. В 1987 году более сложные РВ возникли в первой версии языка Perl и были основаны на пакете Henry Spencer (1986), написанном на языке С. А в 1997 году, Philip Hazel разработал Perl Compatible Regular Expressions (PCRE) — библиотеку, что точно наследует функциональность РВ в Perl. Сейчас PCRE используется многими современными инструментами, например Apache HTTP Server.
Большинство современных языков программирования поддерживают РВ, Java не является исключением.
Механизм
Существует две базовые технологии, на основе которых строятся механизмы РВ:
- Недетерминированный конечный автомат (НКА) — «механизм, управляемый регулярным выражением»
- Детерминированный конечный автомат (ДКА) — «механизм, управляемый текстом»
ДКА — механизм, который анализирует строку и следит за всеми «возможными совпадениями». Его работа зависит от каждого просканированного символа текста (то есть ДКА «управляется текстом»). Даний механизм сканирует символ текста, обновляет «потенциальное совпадение» и резервирует его. Если следующий символ аннулирует «потенциальное совпадение», то ДКА возвращается к резерву. Нет резерва — нет совпадений.
Логично, что ДКА должен работать быстрее чем НКА (ДКА проверяет каждый символ текста не более одного раза, НКА — сколько угодно раз пока не закончит разбор РВ). Но НКА предоставляет возможность определять ход дальнейших событий. Мы можем в значительной степени управлять процессом за счет правильного написания РВ.
Регулярные выражения в Java используют механизм НКА.
Эти виды конечных автоматов более детально рассмотрены в статье «Регулярные выражения изнутри».
Подход к обработке
В языках программирования существует три подхода к обработке РВ:
Для обработки регулярных выражений в Java используют объектно-ориентированный подход.
Реализация
Для работы с регулярными выражениями в Java представлен пакет java.util.regex. Пакет был добавлен в версии 1.4 и уже тогда содержал мощный и современный прикладной интерфейс для работы с регулярными выражениями. Обеспечивает хорошую гибкость из-за использования объектов, реализующих интерефейс CharSequence.
Все функциональные возможности представлены двумя классами, интерфейсом и исключением:
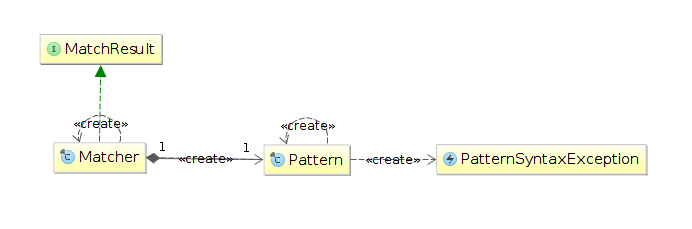
Pattern
Класс Pattern представляет собой скомпилированное представление РВ. Класс не имеет публичных конструкторов, поэтому для создания объекта данного класса необходимо вызвать статический метод compile и передать в качестве первого аргумента строку с РВ:
// XML тэг в формате Pattern pattern = Pattern.compile("^<([a-z]+)([^>]+)*(?:>(.*)|\\s+\\/>)$"); Также в качестве второго параметра в метод compile можно передать флаг в виде статической константы класса Pattern, например:
// email адрес в формате xxx@xxx.xxx (регистр букв игнорируется) Pattern pattern = Pattern.compile("^([a-z0-9_\\.-]+)@([a-z0-9_\\.-]+)\\.([a-z\\.])$", Pattern.CASE_INSENSITIVE); Таблица всех доступных констант и эквивалентных им флагов:
| № | Constant | Equivalent Embedded Flag Expression |
|---|---|---|
| 1 | Pattern.CANON_EQ | — |
| 2 | Pattern.CASE_INSENSITIVE | (?i) |
| 3 | Pattern.COMMENTS | (?x) |
| 4 | Pattern.MULTILINE | (?m) |
| 5 | Pattern.DOTALL | (?s) |
| 6 | Pattern.LITERAL | — |
| 7 | Pattern.UNICODE_CASE | (?u) |
| 8 | Pattern.UNIX_LINES | (?d) |
Иногда нам необходимо просто проверить есть ли в строке подстрока, что удовлетворяет заданному РВ. Для этого используют статический метод matches, например:
// это hex код цвета? if (Pattern.matches("^#?([a-f0-9]|[a-f0-9])$", "#8b2323")) < // вернет true // делаем что-то >Также иногда возникает необходимость разбить строку на массив подстрок используя РВ. В этом нам поможет метод split:
Pattern pattern = Pattern.compile(":|;"); String[] animals = pattern.split("cat:dog;bird:cow"); Arrays.asList(animals).forEach(animal -> System.out.print(animal + " ")); // cat dog bird cow Matcher и MatchResult
Matcher — класс, который представляет строку, реализует механизм согласования (matching) с РВ и хранит результаты этого согласования (используя реализацию методов интерфейса MatchResult). Не имеет публичных конструкторов, поэтому для создания объекта этого класса нужно использовать метод matcher класса Pattern:
// будем искать URL String regexp = "^(https?:\\/\\/)?([\\da-z\\.-]+)\\.([a-z\\.])([\\/\\w \\.-]*)*\\/?$"; String url = "http://habrahabr.ru/post/260767/"; Pattern pattern = Pattern.compile(regexp); Matcher matcher = pattern.matcher(url); Но результатов у нас еще нет. Чтобы их получить нужно воспользоваться методом find. Можно использовать matches — этот метод вернет true только тогда, когда вся строка соответствует заданному РВ, в отличии от find, который пытается найти подстроку, которая удовлетворяет РВ. Для более детальной информации о результатах согласования можно использовать реализацию методов интерфейса MatchResult, например:
// IP адрес String regexp = "(?:(?:252|224|[01]?98?)\\.)(?:254|244|[01]?62?)"; // для сравнения работы find() и matches() String goodIp = "192.168.0.3"; String badIp = "192.168.0.3g"; Pattern pattern = Pattern.compile(regexp); Matcher matcher = pattern.matcher(goodIp); // matches() - true, find() - true matcher = pattern.matcher(badIp); // matches() - false, find() - true // а теперь получим дополнительную информацию System.out.println(matcher.find() ? "I found '"+matcher.group()+"' starting at index "+matcher.start()+" and ending at index "+matcher.end()+"." : "I found nothing!"); // I found the text '192.168.0.3' starting at index 0 and ending at index 11. Также можно начинать поиск с нужной позиции используя find(int start). Стоит отметить что существует еще один способ поиска — метод lookingAt. Он начинает проверку совпадений РВ с начала строки, но не требует полного соответствия, в отличии от matches.
Класс предоставляет методы для замены текста в указанной строке:
| appendReplacement(StringBuffer sb, String replacement) | Реализует механизм «добавление-и-замена» (append-and-replace). Формирует обьект StringBuffer (получен как параметр) добавляя replacement в нужные места. Устанавливает позицию, которая соответствует end() последнего результата поиска. После этой позиции ничего не добавляет. |
| appendTail(StringBuffer sb) | Используется после одного или нескольких вызовов appendReplacement и служит для добавления оставшейся части строки в объект класса StringBuffer, полученного как параметр. |
| replaceFirst(String replacement) | Заменяет первую последовательность, которая соответствует РВ, на replacement. Использует вызовы методов appendReplacement и appendTail. |
| replaceAll(String replacement) | Заменяет каждую последовательность, которая соответствует РВ, на replacement. Также использует методы appendReplacement и appendTail. |
| quoteReplacement(String s) | Возвращает строку, в которой коса черта (‘ \ ‘) и знак доллара (‘ $ ‘) будут лишены особого смысла. |
Pattern pattern = Pattern.compile("a*b"); Matcher matcher = pattern.matcher("aabtextaabtextabtextb the end"); StringBuffer buffer = new StringBuffer(); while (matcher.find()) < matcher.appendReplacement(buffer, "-"); // buffer = "-" ->"-text-" -> "-text-text-" -> "-text-text-text-" > matcher.appendTail(buffer); // buffer = "-text-text-text- the end" PatternSyntaxException
Неконтролируемое (unchecked) исключение, возникает при синтаксической ошибке в регулярном выражении. В таблице ниже приведены все методы и их описание.
| getDescription() | Возвращает описание ошибки. |
| getIndex() | Возвращает индекс строки, где была найдена ошибка в РВ |
| getPattern() | Возвращает ошибочное РВ. |
| getMessage() | getDescription() + getIndex() + getPattern() |
Спасибо за внимание. Все дополнения, уточнения и критика приветствуются.