- Как использовать noindex и nofollow
- 1. Задать правила индексации страницы и ссылок на ней
- В чем отличие директив noindex и nofollow от запрета в robots.txt
- 2. Скрыть неуникальный или повторяющийся текст от Яндекса
- Как проверить наличие и правильность употребления noindex и nofollow
- Расширение RDS Bar
- Проверка в SEO-модуле PromoPult
- Совет напоследок
- Какая разница между тегами nofollow и noindex?
- Теги и атрибуты
- Что такое noindex
- Какой контент помечается этим тегом?
- Как использовать тег?
- Что такое nofollow
- Какой контент помечается этим атрибутом?
- Как прописывать тег?
- Преимущества тега noindex и атрибута nofollow
- Итоги
Как использовать noindex и nofollow
Noindex и nofollow — разные по функционалу элементы. Их часто путают, и как только не называют: тегами, метатегами, атрибутами. Расставим все точки над «i» и расскажем, чем отличается noindex от nofollow и в каких случаях их целесообразно использовать.
1. Задать правила индексации страницы и ссылок на ней
Прежде всего, noindex и nofollow (наряду с index и follow) — это указания для поисковых роботов в метатегах секции . Их понимают все без исключения поисковики. Указания index или noindex разрешают или запрещают роботу индексировать содержимое страницы, а follow и nofollow — переходить по ссылкам на странице.
— в этом случае разрешена индексация страницы и ссылок.
— запрещена индексация содержимого страницы, но разрешен переход по ссылкам.
— разрешена индексация, но запрещен переход по ссылкам.
— запрещается и индексация, и переход по ссылкам.
От индексации следует закрывать служебные страницы (вход в административную панель, логи сервера) а также дублированный контент (страницы архивов, тегов, результаты поиска по сайту, в некоторых случаях — пагинацию).
Если вы хотите оставить указания только для какого-то конкретного робота, нужно указать его идентификатор в метатеге. Например, для бота Google:
Если не задать указания для робота, то он по умолчанию принимает значения index и follow.
Перечень метатегов, которые учитывает Яндекс, найдете в Справке Вебмастера, Google — в документации Центра Google поиска.
В чем отличие директив noindex и nofollow от запрета в robots.txt
Запретить поисковым роботам индексировать страницу можно несколькими способами. Самых популярных два:
Запретить страницу для индексации при помощи директивы Disallow в файле robots.txt:
В чем же принципиальная разница между этими двумя методами?
Для страниц, которые еще не проиндексированы роботами, особой разницы нет — можно использовать оба способа.
Страницы, которые уже есть в индексе, лучше закрывать директивами noindex и nofollow в meta robots. В этом случае поисковики быстрее исключат страницу их индекса и больше не проиндексируют ее.
Важно! Чтобы робот правильно интерпретировал директивы noindex и nofollow и не добавил страницу в индекс, нельзя одновременно закрывать доступ к ней в файле robots.txt при помощи директивы Disallow. Робот не получает доступа к странице и не видит запрещающих директив. А если на страницу стоит ссылка с другого сайта, краулер перейдет по ней и добавит страницу в индекс.
Еще один вариант полного запрета индексации страницы — настроить HTTP-ответ с заголовком X-Robots-Tag и значением noindex или none. Пример такого заголовка в коде:
HTTP/1.1 200 OK Date: Tue, 25 May 2010 21:42:43 GMT X-Robots-Tag: noindex2. Скрыть неуникальный или повторяющийся текст от Яндекса
Для того чтобы закрыть не всю страницу, а только ее часть от индексации, используется тег . Причем это «ноу-хау» Яндекса. Google тег не понимает и считает его невалидным. Синтаксис выглядит так:
Проблема в том, что при такой конструкции во время валидации кода будут ошибки. Если вы хотите сделать код валидным, используйте такой синтаксис:
текст, который следует скрыть от индексацииАльтернативный способ закрыть от индексации часть текста на странице — добавить тег . В коде это будет выглядеть так:
Тег запрещает индексацию и дополнительно скрывает содержимое от пользователя, браузер которого поддерживает JavaScript. Эта технология поддерживается всеми популярными браузерами, но может быть отключена самим пользователем.
Скрывать от индексации есть смысл:
- дословные цитаты других авторов;
- выдержки из законодательства;
- регулярно повторяющийся одинаковый текст (например, в сквозных блоках на сайте с описаниями преимуществ компании);
- служебный текст.
По поводу тега есть заблуждение. Считается, что текст, помещенный в него, Яндекс вообще не учитывает. Это не так. Яндекс читает его и принимает во внимание при определении релевантности страницы и ее уникальности, просто он не добавляет его в индексную базу.
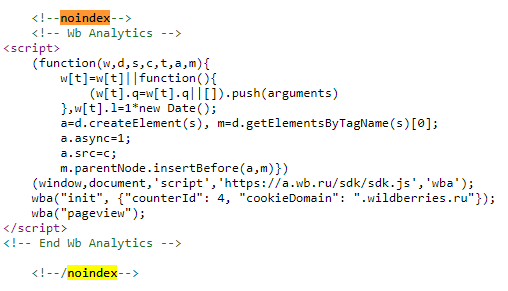
Как проверить наличие и правильность употребления noindex и nofollow
Конечно, можно найти эти элементы в режиме просмотра кода, если требуется информация для одной страницы. Но ручная проверка даже небольшого многостраничного ресурса неэффективна.
Расскажем о двух способах найти noindex и nofollow на сайте.
Расширение RDS Bar
Какие атрибуты и теги использованы на страницах сайта, наглядно покажет бесплатное расширение для браузера RDS Bar. Оно доступно для Chrome, Opera и Firefox.
После установки активируйте расширение, кликнув на значок:

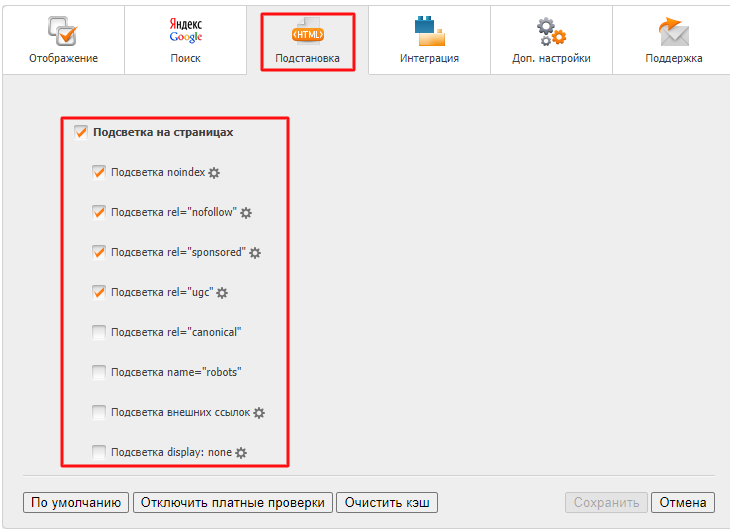
В настройках в разделе «Подстановка» можно отметить, какие именно элементы следует подсвечивать на странице:
После этого ссылки с rel=»nofollow» будут отображаться как перечеркнутые:

А контент, не подлежащий индексированию, будет выделяться другим цветом:

Проверка в SEO-модуле PromoPult
Не только узнать, есть ли noindex и nofollow на сайте, но и проверить, правильно ли они использованы, можно в SEO-модуле PromoPult. На шаге создания проекта «Целевые страницы» можно провести быстрый анализ технической оптимизации страниц. Проверка происходит бесплатно и занимает несколько секунд.
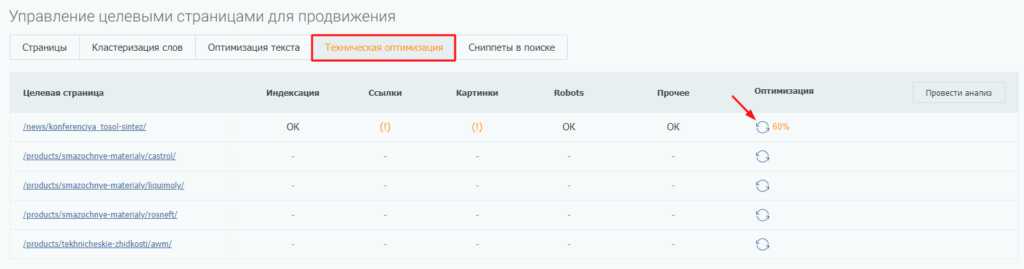
Восклицательные знаки в таблице обозначают проблему. Если нажать на знак, раскроется подробное описание параметров страницы:
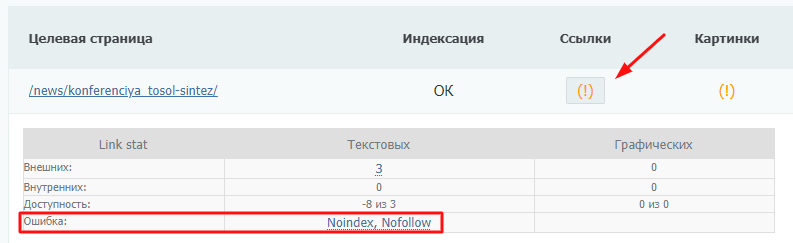
Наличие запретов в robots можно посмотреть в колонке «Прочее»:
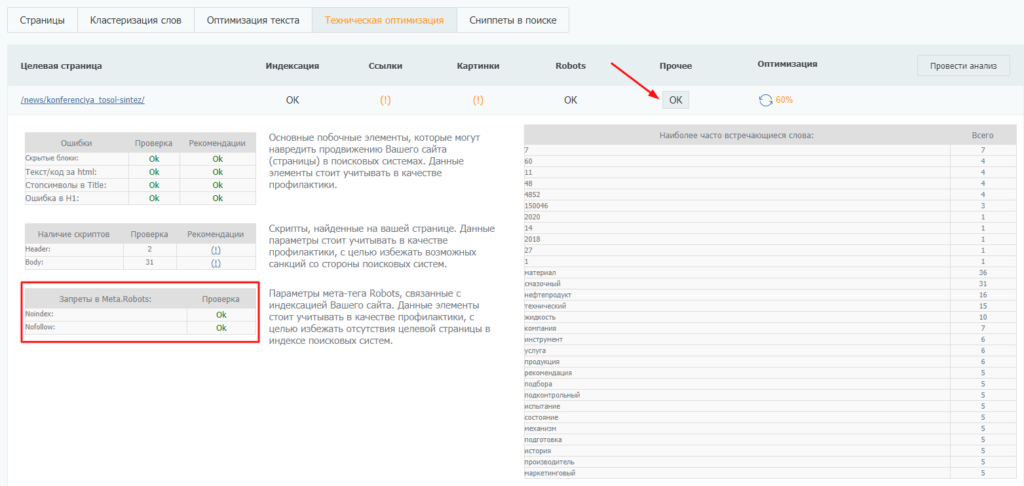
После проверки можете самостоятельно исправить ошибки и запустить повторную проверку, а можете доверить оптимизацию специалистам PromoPult.
Совет напоследок
Некоторые оптимизаторы в погоне за сохранением драгоценного веса закрывают с помощью noindex и nofollow все, что только можно, не оставляя ни одной внешней ссылки. Это ошибка. Дело в том, что ссылки на авторитетные ресурсы поднимают рейтинг вашего сайта в глазах поисковиков. Не бойтесь ссылаться — это вполне нормально, если вы указываете источники данных и полезные ресурсы.
Какая разница между тегами nofollow и noindex?

Выясняем, как работают тег noindex и атрибут nofollow. Подробно рассмотрим сценарии использования и узнаем, как прописывать теги для роботов в зависимости от поставленных задач.
Теги и атрибуты
Их еще называют дескрипторами. Это элементы разметки, с помощью которых объектам в текстовом документе придаются определенные свойства. Эти свойства зависят от языка разметки и поставленных задач. Сделать шрифт жирным, превратить кусок текста в гиперссылку или задать ей специфичные визуальные характеристики.
Но есть теги, которые выполняют несколько иные функции. В их числе nofollow и noindex. В любых своих проявлениях они никак внешне не влияют на текст и ссылки. Посетитель сайта не заметит, если часть страницы обведут в тег или пометят атрибутом nofollow. Текст будет выглядеть без изменений.
Изменения произойдут на технической стороне. Отличия заметит поисковой робот, анализирующий и индексирующий веб-страницы.
Что такое noindex
«Ноиндекс» – тег и атрибут HTML-страницы. Можно пометить им страницу целиком, придав ей определенные свойства, либо выбрать отдельный участок кода и применить атрибут к нему.
Функция noindex заключается в «сокрытии» контента от поисковых роботов, машин, анализирующих и индексирующих веб-сайты. Они собирают базу данных для поисковых служб и предоставляют пользователям релевантные результаты поиска.
Если какая-то часть контента на странице помечена тегом noindex, то робот ее проигнорирует и в поиске она учтена не будет, что прямо повлияет на SEO-продвижение ресурса, на котором были произведены соответствующие изменения.
На самом деле, робот, конечно же, посмотрит все, что есть на сайте. Просто не будет заносить это в индексную базу.
Какой контент помечается этим тегом?
Любой. В зависимости от помеченной информации и поискового робота тег будет восприниматься по-разному.
Обычно в noindex заворачивают четыре типа текстового контента:
- Информацию с низкой уникальностью, чтобы избежать проблем с антиплагиатом.
- Коды счетчиков (типа метрики и других аналитических систем), ненужные поисковику.
- Контактные данные, номера и ссылки, которые не стоило бы показывать в поисковой выдаче.
- Постоянно меняющийся текст, индексация которого не принесет никакой пользы.
Как использовать тег?
Тег можно вставить в страницы как мету (атрибутом), увеличив область его действия на всю страницу.
С таким кодом индексация страницы разрешается:
А с таким индексация запрещается:
Такое правило можно указать для конкретного робота. Например, поискового бота Google:
Еще один способ — встраивание тегов в текст и оборачивание в него ссылок.
Правда, такая разметка может нагородить ошибок из-за того, что многие поисковики не понимают тег и считают его наличие в тексте ошибкой. Поэтому приходится исползать его вариацию . В таком виде роботы, понимающие тег, считывают его без проблем и задают нужные свойства, а непонимающие попросту игнорируют.
Независимо от типа скрываемого контента, принцип остается тем же. Поэтому, если нужно скрыть от индексации код счетчика, ничего специфичного делать не придется. Так же оборачиваем его в и все.
Что такое nofollow
Атрибут, вставляющийся перед ссылками и запрещающий по ним переходить.
Вес страницы — это своего рода уровень авторитетности сайтов, один из факторов, учитываемых при ранжировании страниц в поисковых запросах. Чтобы не передавать вес страницы другим сайтам по размещенным на них ссылкам, данные ссылки оборачивают в тег nofollow.
Какой контент помечается этим атрибутом?
Ссылки. Но не все ссылки, а те, что могут как-то негативно повлиять на вес ресурса. Это касается автоматических ссылок, появляющихся в тех или иных участках сайта. Атрибут nofollow стоило бы приписывать любым внешним ссылкам, за которые вы не можете ручаться. Добавленные на ресурс другими пользователями через секцию комментариев или в графу профиля БИО.
Как прописывать тег?
С таким тегом индексирование страницы разрешается, но запрещается переход по всем ссылкам:
Как и в случае с , правило можно задать для конкретного поискового робота:
Если мы говорим о конкретных ссылках, то переход на них можно запретить прямо внутри разметки.
Преимущества тега noindex и атрибута nofollow
Некоторые полезные свойства тегов мы уже обсудили выше, но на эту тему можно сказать больше.
- Теги помогают сделать информацию на сайте более релевантной за счет вычленения из нее неуникального и разного рода утилитарного контента, который никак не связан с данными для посетителей. Не только пропадает текст, понижающий общую уникальность, но и увеличивается плотность вхождения ключевых слов.
- Тегами можно спрятать информацию из сквозных блоков, которые часто воспринимаются роботами как дубликаты данных.
- Я уже упомянул выше, что за тегом частенько прячут контактную информацию, но не пояснил зачем. Дело в поисковых сниппетах Яндекса и Google, в которые ненароком могут попасть номера телефонов и адреса, указанные на другом сайте или закрепленные за другой компанией в Яндекс.Справочнике.
- Атрибут nofollow может прятать платные ссылки. Рекламные статьи, заметки и обзоры, размещенные на странице. Поисковикам запрещают переход по ним, чтобы избежать санкций со стороны Google или Яндекса.
- Еще nofollow нужен для распределения приоритетов сканирования. Чтобы в него не попадали всякие формы регистрации и прочие технические страницы. Сканирование этой информации никакой пользы не принесет.
Выше мы использовали и nofollow в качестве мета-атрибутов, чтобы задать свойства всей странице целиком. Посмотрим, как разрешить для роботов весь контент и все ссылки:
А это полный запрет на контент и ссылки:
Данный тег спрячет от ботов страницу целиком, но то же самое можно сделать, указав соответствующую ссылку в графе Disallow файла robots.txt, который отвечает за «исключение» страниц из индексации.
Но способы отличаются тем, что мета-тег разрешает поисковикам заходить на сайт и анализировать его содержимое. А вот если ссылка указана в robots.txt, то бот не сможет на нее зайти и провести индексирование.
Во избежание неадекватного поведения ботов, на уже проиндексированных страницах лучше использовать мета-теги, а в robots.txt заносите новые ссылки, неизвестные для Google и Яндекс.
Итоги
Теперь вы знаете, какие задачи выполняют теги noindex и nofollow. С помощью них можно строго задать поведение поисковых ботов Google и Яндекс в отношении вашего сайта и тем самым улучшить показатели SEO.