- Apache POI Word — Overview
- What is Apache POI?
- Components of Apache POI
- Apache POI Word — Installation
- System Requirements
- Как заменить текст (тег) HTML в docx, используя Apache POI?
- 1 ответ
- Apache poi html to docx
- Field Summary
- Fields inherited from class org.apache.poi.hwpf.converter.AbstractWordConverter
- Constructor Summary
- Method Summary
- Methods inherited from class org.apache.poi.hwpf.converter.AbstractWordConverter
- Methods inherited from class java.lang.Object
- Constructor Detail
- WordToHtmlConverter
- WordToHtmlConverter
- Method Detail
- main
- afterProcess
- getDocument
- outputCharacters
- processBookmarks
- processDocumentInformation
- processDocumentPart
- processDropDownList
- processDrawnObject
- processEndnoteAutonumbered
- processFootnoteAutonumbered
- processHyperlink
- processImage
- processImageWithoutPicturesManager
- processLineBreak
- processNoteAutonumbered
- processPageBreak
- processPageref
- processParagraph
- processSection
- processSingleSection
- processTable
Apache POI Word — Overview
Many a time, a software application is required to generate reference documents in Microsoft Word file format. Sometimes, an application is even expected to receive Word files as input data.
Any Java programmer who wants to produce MS-Office files as output must use a predefined and read-only API to do so.
What is Apache POI?
Apache POI is a popular API that allows programmers to create, modify, and display MS-Office files using Java programs. It is an open source library developed and distributed by Apache Software Foundation to design or modify MS-Office files using Java program. It contains classes and methods to decode the user input data or a file into MS-Office documents.
Components of Apache POI
Apache POI contains classes and methods to work on all OLE2 Compound documents of MS-Office. The list of components of this API is given below −
- POIFS (Poor Obfuscation Implementation File System) − This component is the basic factor of all other POI elements. It is used to read different files explicitly.
- HSSF (Horrible SpreadSheet Format) − It is used to read and write .xls format of MS-Excel files.
- XSSF (XML SpreadSheet Format) − It is used for .xlsx file format of MS-Excel.
- HPSF (Horrible Property Set Format) − It is used to extract property sets of the MS-Office files.
- HWPF (Horrible Word Processor Format) − It is used to read and write .doc extension files of MS-Word.
- XWPF (XML Word Processor Format) − It is used to read and write .docx extension files of MS-Word.
- HSLF (Horrible Slide Layout Format) − It is used to read, create, and edit PowerPoint presentations.
- HDGF (Horrible DiaGram Format) − It contains classes and methods for MS-Visio binary files.
- HPBF (Horrible PuBlisher Format) − It is used to read and write MS-Publisher files.
This tutorial guides you through the process of working on MS-Word files using Java. Therefore the discussion is confined to HWPF and XWPF components.
Note − OLDER VERSIONS OF POI SUPPORT BINARY FILE FORMATS SUCH AS DOC, XLS, PPT, ETC. VERSION 3.5 ONWARDS, POI SUPPORTS OOXML FILE FORMATS OF MS-OFFICE SUCH AS DOCX, XLSX, PPTX, ETC.
Apache POI Word — Installation
This chapter takes you through the process of setting up Apache POI on Windows and Linux based systems. Apache POI can be easily installed and integrated with your current Java environment following a few simple steps without any complex setup procedures. User administration is required while installation.
System Requirements
| JDK | Java SE 2 JDK 1.5 or above |
|---|---|
| Memory | 1 GB RAM (recommended) |
| Disk Space | No minimum requirement |
| Operating System Version | Windows XP or above, Linux |
Let us now proceed with the steps to install Apache POI.
Step 1: Verify your Java Installation
First of all, you need to have Java Software Development Kit (SDK) installed on your system. To verify this, execute any of the two commands depending on the platform you are working on.
If the Java installation has been done properly, then it will display the current version and specification of your Java installation. A sample output is given in the following table.
Open command console and type −
java version «11.0.11» 2021-04-20 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.11+9-LTS-194)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.11+9-LTS-194, mixed mode)
Open command terminal and type −
java version «11.0.11» 2021-04-20 LTS
Open JDK Runtime Environment 18.9 (build 11.0.11+9-LTS-194)
Open JDK 64-Bit Server VM (build 11.0.11+9-LTS-194, mixed mode)
- We assume the readers of this tutorial have Java SDK version 11.0.11 installed on their system.
- In case you do not have Java SDK, download its current version from www.oracle.com/technetwork/java/javase/downloads/index.html and have it installed.
Step 2: Set your Java Environment
Set the environment variable JAVA_HOME to point to the base directory location where Java is installed on your machine. For example,
Set JAVA_HOME to C:\ProgramFiles\java\jdk11.0.11
Export JAVA_HOME = /usr/local/java-current
Append the full path of Java compiler location to the System Path.
Append the String «C:\Program Files\Java\jdk11.0.11\bin» to the end of the system variable PATH.
Export PATH = $PATH:$JAVA_HOME/bin/
Execute the command java -version from the command prompt as explained above.
Step 3: Install Apache POI Library
Download the latest version of Apache POI from https://poi.apache.org/download.html and unzip its contents to a folder from where the required libraries can be linked to your Java program. Let us assume the files are collected in a folder on C drive.
Add the complete path of the required jars as shown below to the CLASSPATH.
Append the following strings to the end of the user variable
Как заменить текст (тег) HTML в docx, используя Apache POI?
У нас будет шаблонный файл docx, в котором будут некоторые теги, такие как $. Мне нужно заменить эти теги HTML.
Для этого я хочу использовать элемент altChunk в XWPFDocument. Следуя ответу в разделе Как добавить элемент altChunk в XWPFDocument с помощью Apache POI, я мог бы поместить altChunk в конец документа.
Как я могу заменить свой тег на него? Или я мог бы использовать любые другие библиотеки, может быть, docx4j?
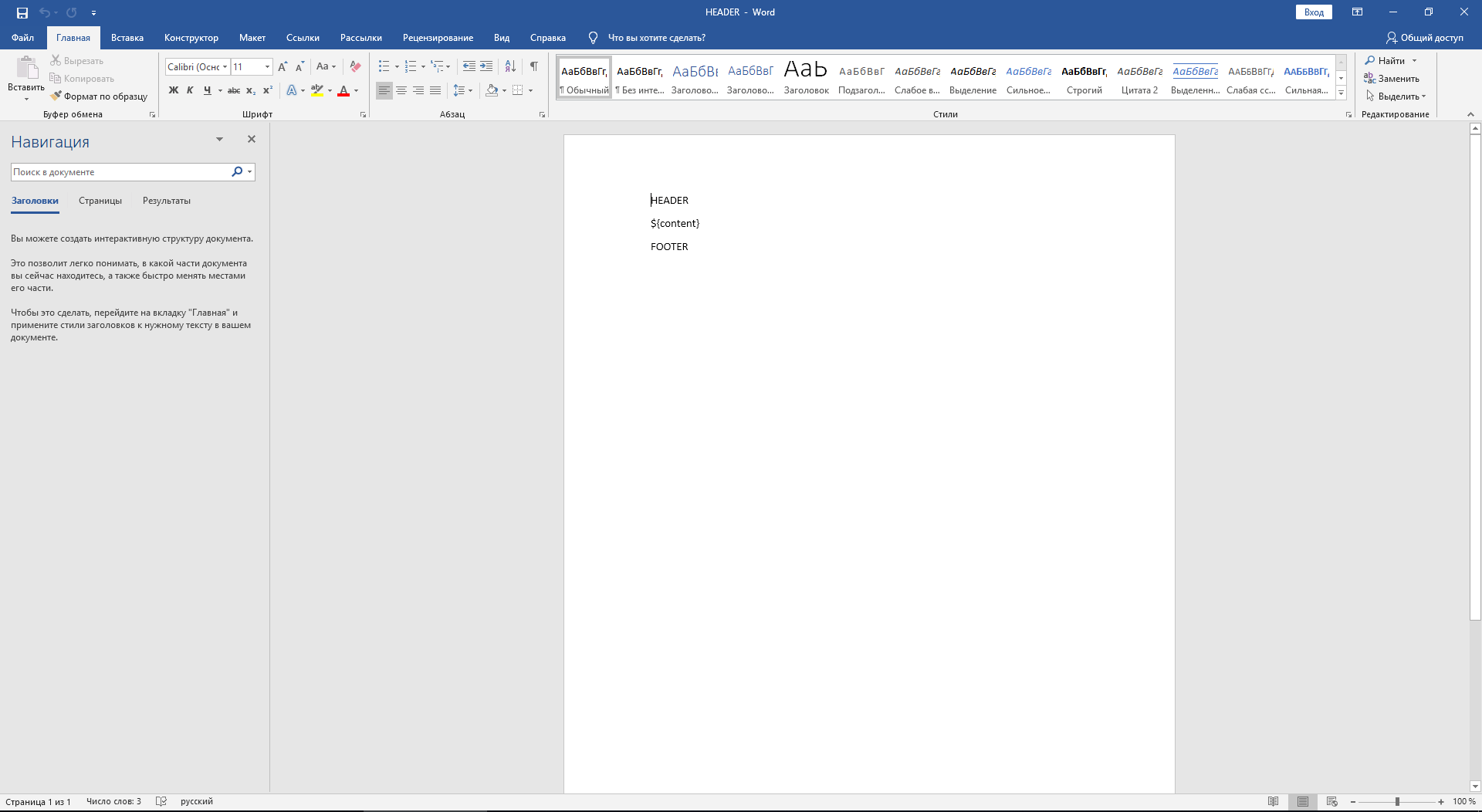
UPD: Файлы шаблонов docx с тегами создаются конечными пользователями с помощью MS Word и выглядят так:
1 ответ
Если «$» находится в своем собственном IBodyElement, то решить это требование, найдя IBodyElement , создавая XmlCursor , вставив altChunk , затем удаляя IBodyElement было бы возможно.
Следующий код демонстрирует это, расширяя пример в разделе Как добавить элемент altChunk в XWPFDocument с использованием Apache POI. Предоставляет метод замены найденного IBodyElement , который содержит специальный текст, с altChunk который ссылается на MyXWPFHtmlDocument , Оно использует XmlCursor чтобы получить необходимую позицию в теле текста. Использование XmlCursor комментируется в коде.
import java.io.*; import org.apache.poi.*; import org.apache.poi.ooxml.*; import org.apache.poi.openxml4j.opc.*; import org.apache.poi.xwpf.usermodel.*; import org.apache.xmlbeans.XmlCursor; import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTAltChunk; public class WordInsertHTMLaltChunkInDocument < //a method for creating the htmlDoc /word/htmlDoc#.html in the *.docx ZIP archive //String id will be htmlDoc#. private static MyXWPFHtmlDocument createHtmlDoc(XWPFDocument document, String id) throws Exception < OPCPackage oPCPackage = document.getPackage(); PackagePartName partName = PackagingURIHelper.createPartName("/word/" + id + ".html"); PackagePart part = oPCPackage.createPart(partName, "text/html"); MyXWPFHtmlDocument myXWPFHtmlDocument = new MyXWPFHtmlDocument(part, id); document.addRelation(myXWPFHtmlDocument.getId(), new XWPFHtmlRelation(), myXWPFHtmlDocument); return myXWPFHtmlDocument; >//a method for replacing a IBodyElement containing a special text with CTAltChunk which //references MyXWPFHtmlDocument private static void replaceIBodyElementWithAltChunk(XWPFDocument document, String textToFind, MyXWPFHtmlDocument myXWPFHtmlDocument) throws Exception < int pos = 0; for (IBodyElement bodyElement : document.getBodyElements()) < if (bodyElement instanceof XWPFParagraph) < XWPFParagraph paragraph = (XWPFParagraph)bodyElement; String text = paragraph.getText(); if (text != null && text.contains(textToFind)) < //create XmlCursor at this paragraph XmlCursor cursor = paragraph.getCTP().newCursor(); cursor.toEndToken(); //now we are at end of the paragraph //there always must be a next start token. Either a p or at least sectPr. while(cursor.toNextToken() != org.apache.xmlbeans.XmlCursor.TokenType.START); //now we can insert the CTAltChunk here String uri = CTAltChunk.type.getName().getNamespaceURI(); cursor.beginElement("altChunk", uri); cursor.toParent(); CTAltChunk cTAltChunk = (CTAltChunk)cursor.getObject(); //set the altChunk's Id to reference the given MyXWPFHtmlDocument cTAltChunk.setId(myXWPFHtmlDocument.getId()); //now remove the found IBodyElement document.removeBodyElement(pos); break; //break for each loop >> pos++; > > public static void main(String[] args) throws Exception ", "Simple HTML formatted text
")); replaceIBodyElementWithAltChunk(document, "$", myXWPFHtmlDocument); FileOutputStream out = new FileOutputStream("result.docx"); document.write(out); out.close(); document.close(); > //a wrapper class for the htmlDoc /word/htmlDoc#.html in the *.docx ZIP archive //provides methods for manipulating the HTML //TODO: We should *not* using String methods for manipulating HTML! private static class MyXWPFHtmlDocument extends POIXMLDocumentPart < private String html; private String id; private MyXWPFHtmlDocument(PackagePart part, String id) throws Exception < super(part); this.html = " "; this.id = id; > private String getId() < return id; >private String getHtml() < return html; >private void setHtml(String html) < this.html = html; >@Override protected void commit() throws IOException < PackagePart part = getPackagePart(); OutputStream out = part.getOutputStream(); Writer writer = new OutputStreamWriter(out, "UTF-8"); writer.write(html); writer.close(); out.close(); >> //the XWPFRelation for /word/htmlDoc#.html private final static class XWPFHtmlRelation extends POIXMLRelation < private XWPFHtmlRelation() < super( "text/html", "http://schemas.openxmlformats.org/officeDocument/2006/relationships/aFChunk", "/word/htmlDoc#.html"); >> > Apache poi html to docx
Converts Word files (95-2007) into HTML files. This implementation doesn’t create images or links to them. This can be changed by overriding AbstractWordConverter.processImage(Element, boolean, Picture) method.
Field Summary
Fields inherited from class org.apache.poi.hwpf.converter.AbstractWordConverter
Constructor Summary
Method Summary
Special actions that need to be called after processing complete, like updating stylesheets or building document notes list.
Methods inherited from class org.apache.poi.hwpf.converter.AbstractWordConverter
Methods inherited from class java.lang.Object
Constructor Detail
WordToHtmlConverter
public WordToHtmlConverter(org.w3c.dom.Document document)
Creates new instance of WordToHtmlConverter. Can be used for output several HWPFDocument s into single HTML document.
WordToHtmlConverter
Method Detail
main
public static void main(java.lang.String[] args) throws java.io.IOException, javax.xml.parsers.ParserConfigurationException, javax.xml.transform.TransformerException
Java main() interface to interact with WordToHtmlConverter Usage: WordToHtmlConverter infile outfile Where infile is an input .doc file ( Word 95-2007) which will be rendered as HTML into outfile
afterProcess
protected void afterProcess()
Special actions that need to be called after processing complete, like updating stylesheets or building document notes list. Usually they are called once, but it’s okay to call them several times.
getDocument
public org.w3c.dom.Document getDocument()
outputCharacters
protected void outputCharacters(org.w3c.dom.Element pElement, CharacterRun characterRun, java.lang.String text)
processBookmarks
protected void processBookmarks(HWPFDocumentCore wordDocument, org.w3c.dom.Element currentBlock, Range range, int currentTableLevel, java.util.ListBookmark> rangeBookmarks)
Wrap range into bookmark(s) and process it. All bookmarks have starts equal to range start and ends equal to range end. Usually it’s only one bookmark.
processDocumentInformation
processDocumentPart
processDropDownList
protected void processDropDownList(org.w3c.dom.Element block, CharacterRun characterRun, java.lang.String[] values, int defaultIndex)
processDrawnObject
protected void processDrawnObject(HWPFDocument doc, CharacterRun characterRun, OfficeDrawing officeDrawing, java.lang.String path, org.w3c.dom.Element block)
processEndnoteAutonumbered
protected void processEndnoteAutonumbered(HWPFDocument wordDocument, int noteIndex, org.w3c.dom.Element block, Range endnoteTextRange)
processFootnoteAutonumbered
protected void processFootnoteAutonumbered(HWPFDocument wordDocument, int noteIndex, org.w3c.dom.Element block, Range footnoteTextRange)
processHyperlink
protected void processHyperlink(HWPFDocumentCore wordDocument, org.w3c.dom.Element currentBlock, Range textRange, int currentTableLevel, java.lang.String hyperlink)
processImage
protected void processImage(org.w3c.dom.Element currentBlock, boolean inlined, Picture picture, java.lang.String imageSourcePath)
processImageWithoutPicturesManager
processLineBreak
processNoteAutonumbered
protected void processNoteAutonumbered(HWPFDocument doc, java.lang.String type, int noteIndex, org.w3c.dom.Element block, Range noteTextRange)
processPageBreak
protected void processPageBreak(HWPFDocumentCore wordDocument, org.w3c.dom.Element flow)
processPageref
protected void processPageref(HWPFDocumentCore hwpfDocument, org.w3c.dom.Element currentBlock, Range textRange, int currentTableLevel, java.lang.String pageref)
processParagraph
protected void processParagraph(HWPFDocumentCore hwpfDocument, org.w3c.dom.Element parentElement, int currentTableLevel, Paragraph paragraph, java.lang.String bulletText)
processSection
protected void processSection(HWPFDocumentCore wordDocument, Section section, int sectionCounter)
processSingleSection
protected void processSingleSection(HWPFDocumentCore wordDocument, Section section)
processTable
protected void processTable(HWPFDocumentCore hwpfDocument, org.w3c.dom.Element flow, Table table)
Copyright 2022 The Apache Software Foundation or its licensors, as applicable.