- HTML5 — URL Encoding
- Example
- ASCII control characters encoding
- Non-ASCII control characters encoding
- Reserved characters encoding
- Unsafe characters encoding
- Html encode characters in position
- # UnicodeEncodeError: ‘charmap’ codec can’t encode characters in position
- # Use the correct encoding to solve the error
- # Solving the error when using the BeautifulSoup module
- # Set the encoding keyword argument when opening a file
- # Set the errors keyword argument to ignore to silence the error
- # Setting the encoding globally
- # Discussion
HTML5 — URL Encoding
URL encoding is the practice of translating unprintable characters or characters with special meaning within URLs to a representation that is unambiguous and universally accepted by web browsers and servers. These characters include −
- ASCII control characters − Unprintable characters typically used for output control. Character ranges 00-1F hex (0-31 decimal) and 7F (127 decimal). A complete encoding table is given below.
- Non-ASCII control characters − These are characters beyond the ASCII character set of 128 characters. This range is part of the ISO-Latin character set and ncludes the entire «top half» of the ISO-Latin set 80-FF hex (128-255 decimal). A complete encoding table is given below.
- Reserved characters − These are special characters such as the dollar sign, ampersand, plus, common, forward slash, colon, semi-colon, equals sign, question mark, and «at» symbol. All of these can have different meanings inside a URL so need to be encoded. A complete encoding table is given below.
- Unsafe characters − These are space, quotation marks, less than symbol, greater than symbol, pound character, percent character, Left Curly Brace, Right Curly Brace , Pipe, Backslash, Caret, Tilde, Left Square Bracket , Right Square Bracket, Grave Accent. These character present the possibility of being misunderstood within URLs for various reasons. These characters should also always be encoded. A complete encoding table is given below.
The encoding notation replaces the desired character with three characters: a percent sign and two hexadecimal digits whose correspond to the position of the character in the ASCII character set.
Example
One of the most common special characters is the space. You can’t type a space in a URL directly. A space position in the character set is 20 hexadecimal. So you can use %20 in place a space when passing your request to the server.
http://www.example.com/new%20pricing.html
This URL actually retrieves a document named new pricing.html from the www.example.com
ASCII control characters encoding
This includes the encoding for character ranges 00-1F hex (0-31 decimal) and 7F (127 decimal)
| Decimal | Hex Value | Character | URL Encode |
|---|---|---|---|
| 0 | 00 | %00 | |
| 1 | 01 | %01 | |
| 2 | 02 | %02 | |
| 3 | 03 | %03 | |
| 4 | 04 | %04 | |
| 5 | 05 | %05 | |
| 6 | 06 | %06 | |
| 7 | 07 | %07 | |
| 8 | 08 | backspace | %08 |
| 9 | 09 | tab | %09 |
| 10 | 0a | linefeed | %0a |
| 11 | 0b | %0b | |
| 12 | 0c | %0c | |
| 13 | 0d | carriage return | %0d |
| 14 | 0e | %0e | |
| 15 | 0f | %0f | |
| 16 | 10 | %10 | |
| 17 | 11 | %11 | |
| 18 | 12 | %12 | |
| 19 | 13 | %13 | |
| 20 | 14 | %14 | |
| 21 | 15 | %15 | |
| 22 | 16 | %16 | |
| 23 | 17 | %17 | |
| 24 | 18 | %18 | |
| 25 | 19 | %19 | |
| 26 | 1a | %1a | |
| 27 | 1b | %1b | |
| 28 | 1c | %1c | |
| 29 | 1d | %1d | |
| 30 | 1e | %1e | |
| 31 | 1f | %1f | |
| 127 | 7f | %7f |
Non-ASCII control characters encoding
This includes the encoding for the entire «top half» of the ISO-Latin set 80-FF hex (128-255 decimal.)
| Decimal | Hex Value | Character | URL Encode |
|---|---|---|---|
| 128 | 80 | | %80 |
| 129 | 81 | | %81 |
| 130 | 82 | | %82 |
| 131 | 83 | | %83 |
| 132 | 84 | | %84 |
| 133 | 85 | %85 | |
| 134 | 86 | | %86 |
| 135 | 87 | | %87 |
| 136 | 88 | | %88 |
| 137 | 89 | | %89 |
| 138 | 8a | | %8a |
| 139 | 8b | | %8b |
| 140 | 8c | | %8c |
| 141 | 8d | | %8d |
| 142 | 8e | | %8e |
| 143 | 8f | | %8f |
| 144 | 90 | | %90 |
| 145 | 91 | | %91 |
| 146 | 92 | | %92 |
| 147 | 93 | | %93 |
| 148 | 94 | | %94 |
| 149 | 95 | | %95 |
| 150 | 96 | | %96 |
| 151 | 97 | | %97 |
| 152 | 98 | | %98 |
| 153 | 99 | | %99 |
| 154 | 9a | | %9a |
| 155 | 9b | | %9b |
| 156 | 9c | | %9c |
| 157 | 9d | | %9d |
| 158 | 9e | | %9e |
| 159 | 9f | | %9f |
| 160 | a0 | %a0 | |
| 161 | a1 | ¡ | %a1 |
| 162 | a2 | ¢ | %a2 |
| 163 | a3 | £ | %a3 |
| 164 | a4 | ¤ | %a4 |
| 165 | a5 | ¥ | %a5 |
| 166 | a6 | ¦ | %a6 |
| 167 | a7 | § | %a7 |
| 168 | a8 | ¨ | %a8 |
| 169 | a9 | © | %a9 |
| 170 | aa | ª | %aa |
| 171 | ab | « | %ab |
| 172 | ac | ¬ | %ac |
| 173 | ad | | %ad |
| 174 | ae | ® | %ae |
| 175 | af | ¯ | %af |
| 176 | b0 | ° | %b0 |
| 177 | b1 | ± | %b1 |
| 178 | b2 | ² | %b2 |
| 179 | b3 | ³ | %b3 |
| 180 | b4 | ´ | %b4 |
| 181 | b5 | µ | %b5 |
| 182 | b6 | ¶ | %b6 |
| 183 | b7 | · | %b7 |
| 184 | b8 | ¸ | %b8 |
| 185 | b9 | ¹ | %b9 |
| 186 | ba | º | %ba |
| 187 | bb | » | %bb |
| 188 | bc | ¼ | %bc |
| 189 | bd | ½ | %bd |
| 190 | be | ¾ | %be |
| 191 | bf | ¿ | %bf |
| 192 | c0 | À | %c0 |
| 193 | c1 | Á | %c1 |
| 194 | c2 | Â | %c2 |
| 195 | c3 | Ã | %c3 |
| 196 | c4 | Ä | %c4 |
| 197 | c5 | Å | %c5 |
| 198 | c6 | Æ | %v6 |
| 199 | c7 | Ç | %c7 |
| 200 | c8 | È | %c8 |
| 201 | c9 | É | %c9 |
| 202 | ca | Ê | %ca |
| 203 | cb | Ë | %cb |
| 204 | cc | Ì | %cc |
| 205 | cd | Í | %cd |
| 206 | ce | Î | %ce |
| 207 | cf | Ï | %cf |
| 208 | d0 | Ð | %d0 |
| 209 | d1 | Ñ | %d1 |
| 210 | d2 | Ò | %d2 |
| 211 | d3 | Ó | %d3 |
| 212 | d4 | Ô | %d4 |
| 213 | d5 | Õ | %d5 |
| 214 | d6 | Ö | %d6 |
| 215 | d7 | × | %d7 |
| 216 | d8 | Ø | %d8 |
| 217 | d9 | Ù | %d9 |
| 218 | da | Ú | %da |
| 219 | db | Û | %db |
| 220 | dc | Ü | %dc |
| 221 | dd | Ý | %dd |
| 222 | de | Þ | %de |
| 223 | df | ß | %df |
| 224 | e0 | à | %e0 |
| 225 | e1 | á | %e1 |
| 226 | e2 | â | %e2 |
| 227 | e3 | ã | %e3 |
| 228 | e4 | ä | %e4 |
| 229 | e5 | å | %e5 |
| 230 | e6 | æ | %e6 |
| 231 | e7 | ç | %e7 |
| 232 | e8 | è | %e8 |
| 233 | e9 | é | %e9 |
| 234 | ea | ê | %ea |
| 235 | eb | ë | %eb |
| 236 | ec | ì | %ec |
| 237 | ed | í | %ed |
| 238 | ee | î | %ee |
| 239 | ef | ï | %ef |
| 240 | f0 | ð | %f0 |
| 241 | f1 | ñ | %f1 |
| 242 | f2 | ò | %f2 |
| 243 | f3 | ó | %f3 |
| 244 | f4 | ô | %f4 |
| 245 | f5 | õ | %f5 |
| 246 | f6 | ö | %f6 |
| 247 | f7 | ÷ | %f7 |
| 248 | f8 | ø | %f8 |
| 249 | f9 | ù | %f9 |
| 250 | fa | ú | %fa |
| 251 | fb | û | %fb |
| 252 | fc | ü | %fc |
| 253 | fd | ý | %fd |
| 254 | fe | þ | %fe |
| 255 | ff | ÿ | %ff |
Reserved characters encoding
Following is the table to be used to encode reserved characters.
| Decimal | Hex Value | Char | URL Encode |
|---|---|---|---|
| 36 | 24 | $ | %24 |
| 38 | 26 | & | %26 |
| 43 | 2b | + | %2b |
| 44 | 2c | , | %2c |
| 47 | 2f | / | %2f |
| 58 | 3a | : | %3a |
| 59 | 3b | ; | %3b |
| 61 | 3d | = | %3d |
| 63 | 3f | ? | %3f |
| 64 | 40 | @ | %40 |
Unsafe characters encoding
Following is the table to be used to encode unsafe characters.
| Decimal | Hex Value | Char | URL Encode |
|---|---|---|---|
| 32 | 20 | space | %20 |
| 34 | 22 | « | %22 |
| 60 | 3c | %3c | |
| 62 | 3e | > | %3e |
| 35 | 23 | # | %23 |
| 37 | 25 | % | %25 |
| 123 | 7b | %7b | |
| 125 | 7d | > | %7d |
| 124 | 7c | | | %7c |
| 92 | 5c | \ | %5c |
| 94 | 5e | ^ | %5e |
| 126 | 7e | ~ | %7e |
| 91 | 5b | [ | %5b |
| 93 | 5d | ] | %5d |
| 96 | 60 | ` | %60 |
Html encode characters in position
Last updated: Feb 18, 2023
Reading time · 3 min

# UnicodeEncodeError: ‘charmap’ codec can’t encode characters in position
The Python «UnicodeEncodeError: ‘charmap’ codec can’t encode characters in position» occurs when we use an incorrect codec to encode a string to bytes.
To solve the error, specify the correct encoding when opening the file or encoding the string, e.g. utf-8 .
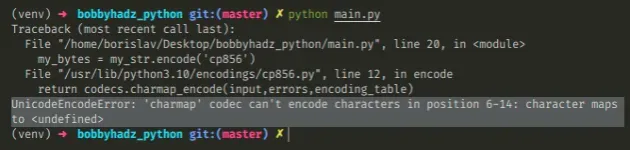
Here is an example of how the error occurs.
Copied!my_str = 'hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ' # ⛔️ UnicodeEncodeError: 'charmap' codec can't encode characters in position 0-8: character maps to my_bytes = my_str.encode('cp856')
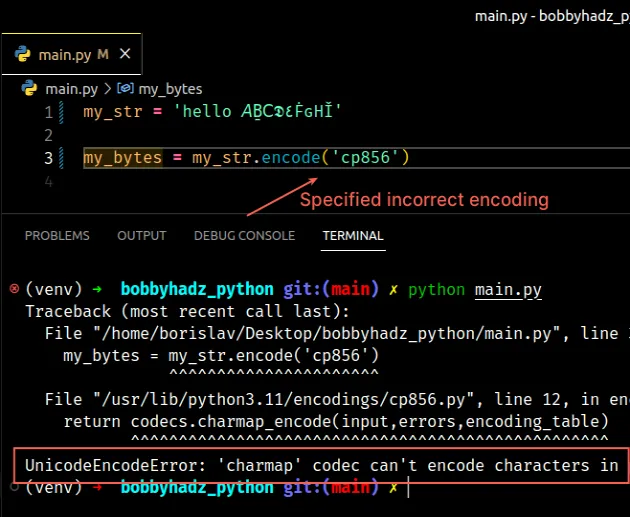
The error is caused because the string cannot be encoded with the specified encoding.
# Use the correct encoding to solve the error
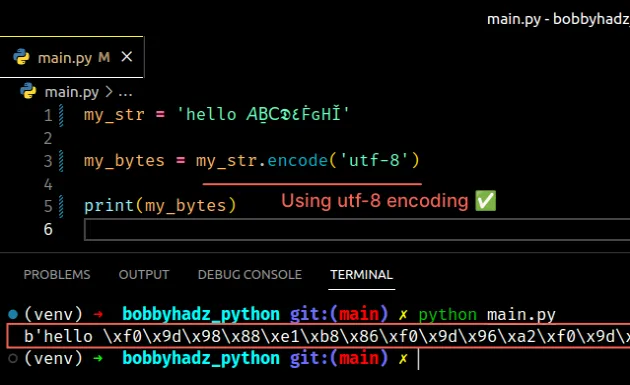
To solve the error, use the correct encoding to encode the string, e.g. utf-8 .
Copied!my_str = 'hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ' my_bytes = my_str.encode('utf-8') # 👇️ b'hello \xf0\x9d\x98\x88\xe1\xb8\x86\xf0\x9d\x96\xa2\xf0\x9d\x95\xaf\xd9\xa4\xe1\xb8\x9e\xd4\x8d\xd0\x9d\xc7\x8f' print(my_bytes)
You can view all of the standard encodings in this table of the official docs.
# Solving the error when using the BeautifulSoup module
If you use the BeautifulSoup module, set the encoding on the object.
Copied!import bs4 as bs import urllib.request source = urllib.request.urlopen('https://example.com').read() soup = bs.BeautifulSoup(source, features="html.parser") # ✅ set encoding to utf-8 here print(soup.encode("utf-8"))
We used the str.encode() method to encode the soup string to bytes.
# Set the encoding keyword argument when opening a file
If you got the error when opening a file, set the encoding keyword argument to utf-8 in the call to the open() function.
Copied!my_str = 'hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ' with open('example.txt', 'w', encoding='utf-8') as f: f.write(my_str)
You can also specify the encoding keyword argument when interacting with CSV files.
Copied!import csv # ✅ specify encoding keyword argument with open('example.csv', 'w', newline='', encoding='utf-8') as csvfile: csv_writer = csv.writer(csvfile, delimiter=',', quoting=csv.QUOTE_MINIMAL) csv_writer.writerow(['Alice', 'Bob', 'Carl'])
The same approach can be used when calling the open() function directly, without the with statement.
Copied!my_str = 'hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ' my_file = open('example.txt', 'w', encoding='utf-8') my_file.write(my_str) my_file.close()
We explicitly set the encoding keyword argument to utf-8 in the call to the open() function.
Encoding is the process of converting a string to a bytes object and decoding is the process of converting a bytes object to a string .
Here is what the complete process looks like.
Copied!my_str = 'hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ' # 👇️ encode str to bytes my_bytes = my_str.encode('utf-8') print(my_bytes) # 👇️ decode bytes to str my_str_again = my_bytes.decode('utf-8') print(my_str_again) # 👉️ "hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ"
When decoding a bytes object, we have to use the same encoding that was used to encode the string to a bytes object.
# Set the errors keyword argument to ignore to silence the error
If the error persists when using the utf-8 encoding, try setting the errors keyword argument to ignore to ignore characters that cannot be encoded.
Copied!my_str = 'hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ' # 👇️ encode str to bytes my_bytes = my_str.encode('utf-8', errors='ignore') print(my_bytes) # 👇️ decode bytes to str my_str_again = my_bytes.decode('utf-8', errors='ignore') print(my_str_again) # 👉️ "hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ"
Note that ignoring characters that cannot be encoded can lead to data loss.
You can also set the errors keyword argument to ignore to ignore any encoding errors when opening a file.
Copied!my_str = 'hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ' with open('example.txt', 'w', encoding='utf-8', errors='ignore') as f: f.write(my_str)
The same approach can be used when calling the open() function directly without the with statement.
Copied!my_str = 'hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ' my_file = open('example.txt', 'w', encoding='utf-8', errors='ignore') my_file.write(my_str) my_file.close()
# Setting the encoding globally
If the error persists, try to set the encoding globally by adding the following 3 lines at the top of your file.
Copied!import sys sys.stdin.reconfigure(encoding='utf-8') sys.stdout.reconfigure(encoding='utf-8')
If the lines are run before any other code in the file, they override the encoding used for stdin/stdout/stderr .
Alternatively, you can set the encoding globally with an environment variable.
Copied!# on Linux and macOS export PYTHONIOENCODING=utf-8 # on Windows setx PYTHONIOENCODING=utf-8 setx PYTHONLEGACYWINDOWSSTDIO=utf-8
If the PYTHONIOENCODING environment variable is set before running the interpreter, it overrides the encoding used for stdin and stdout .
If you are on Windows, you also have to set the PYTHONLEGACYWINDOWSSTDIO environment variable as shown in the example.
If the variable is set to a non-empty string, Unicode characters are encoded according to the active console code page and not utf-8 .
If the error persists, try setting the PYTHONUTF8 to 1 .
Copied!# on Linux and macOS export PYTHONUTF8=1 # on Windows setx PYTHONUTF8=1
If the PYTHONUTF8 variable is set to 1 , then Python UTF-8 mode is enabled.
# Discussion
When you write a string to a file, Python will try to encode the string according to the specified encoding.
If the string contains characters that are not supported by the specified encoding, the error is raised.
If you don’t know what encoding you should specify, your best bet is to try with utf-8 and see if you get legible results.
Python uses utf-8 as the default encoding on most platforms, so it is one of the better options.
I wrote a book in which I share everything I know about how to become a better, more efficient programmer.