- Pandas: как использовать Groupby и Count с условием
- Пример: Groupby и Count с условием в Pandas
- Дополнительные ресурсы
- pandas groupby filter by column values and conditional aggregation
- Create a test dataframe
- Groupby continent and sum the GDP of countries who are G20 Member
- Using pandas assign to filter the groupby columns and apply conditional sum
- Pandas — Groupby with conditional formula
- 3 Answers 3
Pandas: как использовать Groupby и Count с условием
Вы можете использовать следующий базовый синтаксис для выполнения группировки и подсчета с условием в кадре данных pandas:
df.groupby('var1')['var2'].apply ( lambda x: (x=='val'). sum ()). reset_index(name='count') Этот конкретный синтаксис группирует строки DataFrame на основе var1 , а затем подсчитывает количество строк, в которых var2 равно «val».
В следующем примере показано, как использовать этот синтаксис на практике.
Пример: Groupby и Count с условием в Pandas
Предположим, у нас есть следующий кадр данных pandas, который содержит информацию о различных баскетболистах:
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame print(df) team pos points 0 A Gu 18 1 A Fo 22 2 A Fo 19 3 A Fo 14 4 B Gu 14 5 B Gu 11 6 B Fo 20 7 B Fo 28 В следующем коде показано, как сгруппировать DataFrame по переменной team и подсчитать количество строк, в которых переменная pos равна ‘Gu’:
#groupby team and count number of 'pos' equal to 'Gu' df_count = df.groupby('team')['pos'].apply ( lambda x: (x=='Gu'). sum ()). reset_index(name='count') #view results print(df_count) team count 0 A 1 1 B 2 - У команды А есть 1 строка, в которой столбец pos равен «Gu».
- У команды Б есть 2 строки, в которых столбец pos равен «Gu».
Мы можем использовать аналогичный синтаксис для выполнения группировки и подсчета с некоторым числовым условием.
Например, следующий код показывает, как выполнить группировку по переменной team и подсчитать количество строк, в которых значение переменной points больше 15:
#groupby team and count number of 'points' greater than 15 df_count = df.groupby('team')['points'].apply ( lambda x: (x>15). sum ()). reset_index(name='count') #view results print(df_count) team count 0 A 3 1 B 2 - У команды А есть 3 строки, в которых столбец очков больше 15.
- У команды Б есть 2 строки, в которых столбец с очками больше 15.
Вы можете использовать аналогичный синтаксис для выполнения группового и подсчета с любым конкретным условием, которое вы хотите.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в pandas:
pandas groupby filter by column values and conditional aggregation
In this post, we will learn how to filter column values in a pandas group by and apply conditional aggregations such as sum, count, average etc.
We will first create a dataframe of 4 columns , first column is continent, second is country and third & fourth column represents their GDP value in trillion and Member of G20 group respectively. These are fake numbers and doesn’t represent their real GDP worth.
Once this dataframe is created then we will group the countries in this dataframe that are in the same continent and apply conditions to determine the GDP sum of countries who are Member of G20 and who aren’t.
Create a test dataframe
Let’s create a dataframe with all the four columns: continent, country, GDP(trillion) and Member_G20
For the third column GDP(trillion), I’m using numpy randint function to create random numbers for all these countries and similarly for fourth column(Member_G20) random choice is used to randomly select from the list [‘Yes’, ‘No’]
import pandas as pd import numpy as np df = pd.DataFrame('continent' : ['Asia','NorthAmerica','NorthAmerica','Europe','Europe', 'Europe','Asia', 'Europe', 'Asia'], 'country' : ['China', 'USA', 'Canada', 'Poland', 'Romania', 'Italy', 'India', 'Germany', 'Russia'], 'GDP(trillion)' : np.random.randint(1, 9 , 9), 'Member_G20' : np.random.choice(['Y', 'N'], 9)>) 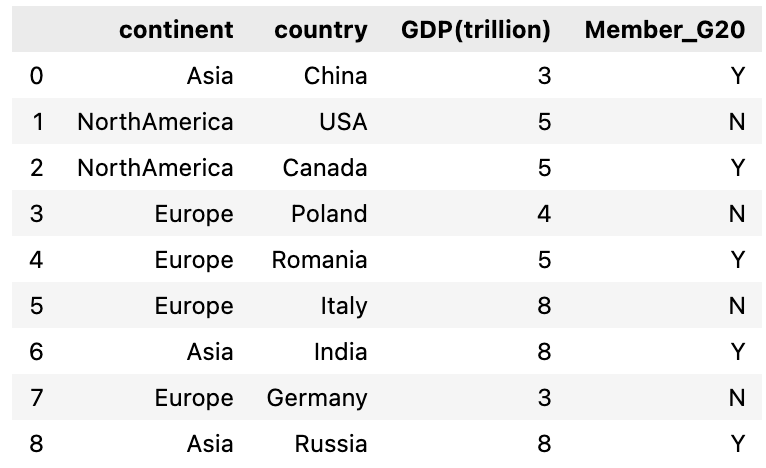
Groupby continent and sum the GDP of countries who are G20 Member
So we will first group by continent and then filter the rows in each group where a country is a G20 member
df.groupby(['continent']).apply(lambda x: x[x['Member_G20'] == 'Y' ]['GDP(trillion)'].sum()) continent Asia 19 Europe 5 NorthAmerica 5 dtype: int64 Let’s understand this by doing one step at a time:
First we group by continent using pandas groupby function
Next, we will select a group from this groupby result, we will choose Europe. we can see all the rows within the group Europe and there are 3 countries in Europe that are not a G20 member
selected_group = grp.get_group('Europe') selected_group 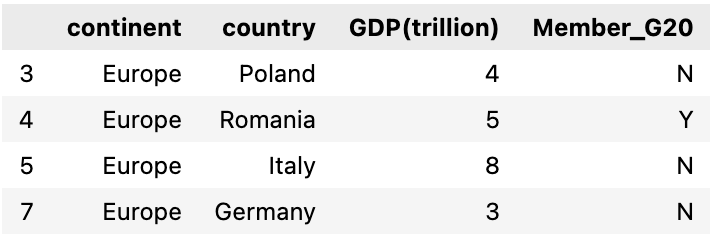
Now filter the rows by column Member_G20 and drop all countries that are not a G20 Member
selected_group[selected_group['Member_G20']=='Y'] continent country GDP(trillion) Member_G20 4 Europe Romania 5 Y At last, we will get the GDP(trillion) column for this filtered group and compute it’ sum
selected_group[selected_group['Member_G20']=='Y']['GDP(trillion)'].sum() Using pandas assign to filter the groupby columns and apply conditional sum
We can use pandas assign, which adds a new column in the dataframe to filter it first by the column values and then apply pandas groupby and finally aggregate the values. Let’s see how it works
here we are using pandas assign to create a new column and update it by column value GDP(trillion) using numpy where() to filter the rows where country is a G20 member otherwise update with 0
df.assign(result = np.where(df['Member_G20']=='Y',df['GDP(trillion)'],0))\ .groupby('continent').agg('result':sum>) 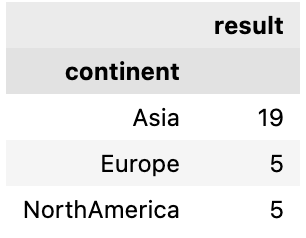
Let’s take another example, if we want to sum up the GDP(trillion) value of the countries who are not a G20 member and also who are a G20 member. We will create two columns in this case and then apply groupby and aggregate(sum) values
df.assign( gdp_sum_non_member_g20 = np.where(df['Member_G20']=='N',df['GDP(trillion)'],0), gdp_sum_member_g20 = np.where(df['Member_G20']=='Y',df['GDP(trillion)'],0) ).groupby('continent').agg('gdp_sum_non_member_g20':sum, 'gdp_sum_member_g20':sum>) 
Updated: January 7, 2022
Pandas — Groupby with conditional formula
Given the above dataframe, is there an elegant way to groupby with a condition? I want to split the data into two groups based on the following conditions:
(df['SibSp'] > 0) | (df['Parch'] > 0) = New Group -"Has Family" (df['SibSp'] == 0) & (df['Parch'] == 0) = New Group - "No Family" SurvivedMean Has Family Mean No Family Mean Can it be done using groupby or would I have to append a new column using the above conditional statement?
Is your df coded in binary? If so, you may be able to use the pandas method get_dummies . Otherwise, yes, I would recommend/think you should create a new column (you would only need one I think) to perform the groupby on. I can help write some code if I have a better idea of what you’re doing! Also, given your desired output, it seems like you will need to pivot the db as well!
3 Answers 3
An easy way to group that is to use the sum of those two columns. If either of them is positive, the result will be greater than 1. And groupby accepts an arbitrary array as long as the length is the same as the DataFrame’s length so you don’t need to add a new column.
family = np.where((df['SibSp'] + df['Parch']) >= 1 , 'Has Family', 'No Family') df.groupby(family)['Survived'].mean() Out: Has Family 0.5 No Family 1.0 Name: Survived, dtype: float64 Use only one condition if never values in columns SibSp and Parch are less as 0 :
m1 = (df['SibSp'] > 0) | (df['Parch'] > 0) df = df.groupby(np.where(m1, 'Has Family', 'No Family'))['Survived'].mean() print (df) Has Family 0.5 No Family 1.0 Name: Survived, dtype: float64 If is impossible use first use both conditions:
m1 = (df['SibSp'] > 0) | (df['Parch'] > 0) m2 = (df['SibSp'] == 0) & (df['Parch'] == 0) a = np.where(m1, 'Has Family', np.where(m2, 'No Family', 'Not')) df = df.groupby(a)['Survived'].mean() print (df) Has Family 0.5 No Family 1.0 Name: Survived, dtype: float64 You could define your conditions in a list and use the function group_by_condition below to create a filtered list for each condition. Afterwards you can select the resulting items using pattern matching:
df = [ , , ] conditions = [ lambda x: (x['SibSp'] > 0) or (x['Parch'] > 0), # has family lambda x: (x['SibSp'] == 0) and (x['Parch'] == 0) # no family ] def group_by_condition(l, conditions): return [[item for item in l if condition(item)] for condition in conditions] [has_family, no_family] = group_by_condition(df, conditions)