List, dict, set comprehensions#
Python поддерживает специальные выражения, которые позволяют компактно создавать списки, словари и множества.
На английском эти выражения называются, соответственно:
К сожалению, официальный перевод на русский звучит как абстракция списков или списковое включение, что не особо помогает понять суть объекта.
В книге использовался перевод «генератор списка», что, к сожалению, тоже не самый удачный вариант, так как в Python есть отдельное понятие генератор и генераторные выражения, но он лучше отображает суть выражения.
Эти выражения не только позволяют более компактно создавать соответствующие объекты, но и создают их быстрее. И хотя поначалу они требуют определенной привычки использования и понимания, они очень часто используются.
List comprehensions (генераторы списков)#
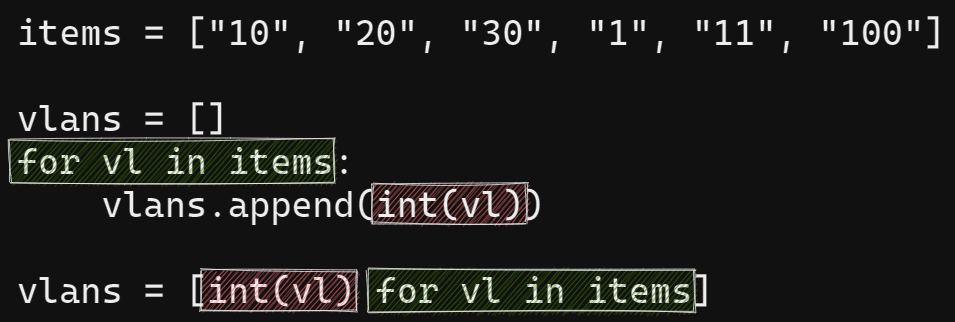
Генератор списка (list comprehensions или list comp) — это выражение вида:
vlans = [int(vl) for vl in items]
В общем случае, list comprehension это выражение, которое преобразует итерируемый объект в список. То есть, последовательность элементов преобразуется и добавляется в новый список.
List comp выше аналогичен такой цикл:
items = ["10", "20", "30", "1", "11", "100"] vlans = [] for vl in items: vlans.append(int(vl)) print(vlans) # [10, 20, 30, 1, 11, 100]
Соответствие между обычным циклом и генератором списка:

В list comprehensions можно использовать выражение if. Таким образом можно добавлять в список только некоторые объекты.
Например, такой цикл отбирает те элементы, которые являются числами, конвертирует их и добавляет в итоговый список only_digits:
items = ['10', '20', 'a', '30', 'b', '40'] only_digits = [] for item in items: if item.isdigit(): only_digits.append(int(item)) In [9]: print(only_digits) [10, 20, 30, 40]
Аналогичный вариант в виде list comprehensions:
items = ['10', '20', 'a', '30', 'b', '40'] only_digits = [int(item) for item in items if item.isdigit()] In [12]: print(only_digits) [10, 20, 30, 40]
Соответствие между циклом с условием и генератором списка с условием:

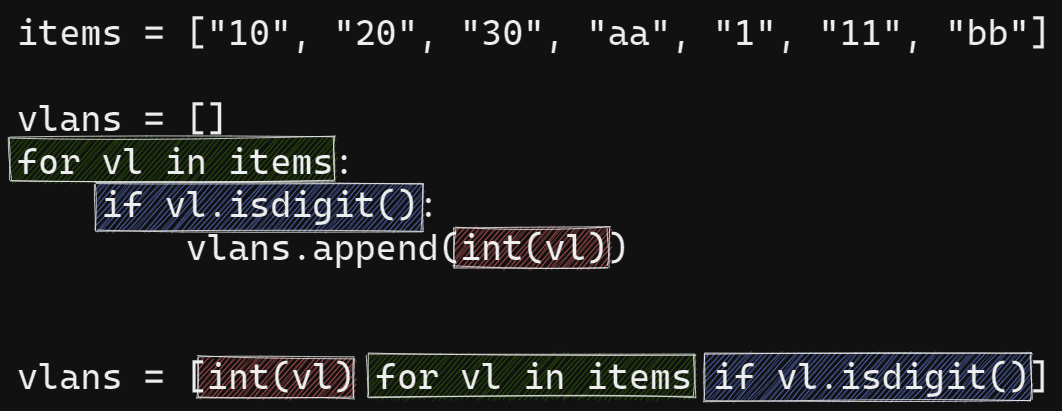
Конечно, далеко не все циклы можно переписать как генератор списка, но когда это можно сделать, и при этом выражение не усложняется, лучше использовать генераторы списка.
В Python генераторы списка могут также заменить функции filter и map и считаются более понятными вариантами решения.
С помощью генератора списка также удобно получать элементы из вложенных словарей:
london_co = 'r1' : 'hostname': 'london_r1', 'location': '21 New Globe Walk', 'vendor': 'Cisco', 'model': '4451', 'ios': '15.4', 'ip': '10.255.0.1' >, 'r2' : 'hostname': 'london_r2', 'location': '21 New Globe Walk', 'vendor': 'Cisco', 'model': '4451', 'ios': '15.4', 'ip': '10.255.0.2' >, 'sw1' : 'hostname': 'london_sw1', 'location': '21 New Globe Walk', 'vendor': 'Cisco', 'model': '3850', 'ios': '3.6.XE', 'ip': '10.255.0.101' > > In [14]: [london_co[device]['ios'] for device in london_co] Out[14]: ['15.4', '15.4', '3.6.XE'] In [15]: [london_co[device]['ip'] for device in london_co] Out[15]: ['10.255.0.1', '10.255.0.2', '10.255.0.101']
Полный синтаксис генератора списка выглядит так:
[expression for item1 in iterable1 if condition1 for item2 in iterable2 if condition2 . for itemN in iterableN if conditionN ]
Это значит, можно использовать несколько for в выражении.
Например, в списке vlans находятся несколько вложенных списков с VLAN’ами:
vlans = [[10, 21, 35], [101, 115, 150], [111, 40, 50]]
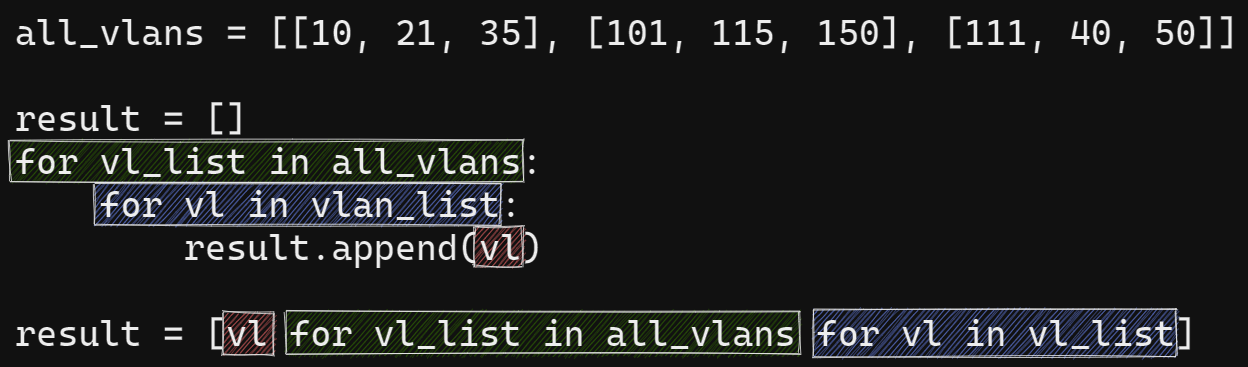
Из этого списка надо сформировать один плоский список с номерами VLAN. Первый вариант — с помощью циклов for:
result = [] for vlan_list in vlans: for vlan in vlan_list: result.append(vlan) In [19]: print(result) [10, 21, 35, 101, 115, 150, 111, 40, 50]
Аналогичный вариант с генератором списков:
vlans = [[10, 21, 35], [101, 115, 150], [111, 40, 50]] result = [vlan for vlan_list in vlans for vlan in vlan_list] In [22]: print(result) [10, 21, 35, 101, 115, 150, 111, 40, 50]
Соответствие между двумя вложенными циклами и генератором списка с двумя циклами:

Можно одновременно проходиться по двум последовательностям, используя zip:
vlans = [100, 110, 150, 200] names = ['mngmt', 'voice', 'video', 'dmz'] result = ['vlan <>\n name <>'.format(vlan, name) for vlan, name in zip(vlans, names)] In [26]: print('\n'.join(result)) vlan 100 name mngmt vlan 110 name voice vlan 150 name video vlan 200 name dmz
Dict comprehensions (генераторы словарей)#
Генераторы словарей аналогичны генераторам списков, но они используются для создания словарей.
d = <> for num in range(1, 11): d[num] = num**2 In [29]: print(d) 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81, 10: 100>
Можно заменить генератором словаря:
d = num: num**2 for num in range(1, 11)> In [31]: print(d) 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81, 10: 100>
Еще один пример, в котором надо преобразовать существующий словарь и перевести все ключи в нижний регистр. Для начала, вариант решения без генератора словаря:
r1 = 'ios': '15.4', 'ip': '10.255.0.1', 'hostname': 'london_r1', 'location': '21 New Globe Walk', 'model': '4451', 'vendor': 'Cisco'> lower_r1 = <> for key, value in r1.items(): lower_r1[key.lower()] = value In [35]: lower_r1 Out[35]: 'hostname': 'london_r1', 'ios': '15.4', 'ip': '10.255.0.1', 'location': '21 New Globe Walk', 'model': '4451', 'vendor': 'Cisco'>
Аналогичный вариант с помощью генератора словаря:
r1 = 'ios': '15.4', 'ip': '10.255.0.1', 'hostname': 'london_r1', 'location': '21 New Globe Walk', 'model': '4451', 'vendor': 'Cisco'> lower_r1 = key.lower(): value for key, value in r1.items()> In [38]: lower_r1 Out[38]: 'hostname': 'london_r1', 'ios': '15.4', 'ip': '10.255.0.1', 'location': '21 New Globe Walk', 'model': '4451', 'vendor': 'Cisco'>
Как и list comprehensions, dict comprehensions можно делать вложенными. Попробуем аналогичным образом преобразовать ключи во вложенных словарях:
london_co = 'r1' : 'hostname': 'london_r1', 'location': '21 New Globe Walk', 'vendor': 'Cisco', 'model': '4451', 'ios': '15.4', 'ip': '10.255.0.1' >, 'r2' : 'hostname': 'london_r2', 'location': '21 New Globe Walk', 'vendor': 'Cisco', 'model': '4451', 'ios': '15.4', 'ip': '10.255.0.2' >, 'sw1' : 'hostname': 'london_sw1', 'location': '21 New Globe Walk', 'vendor': 'Cisco', 'model': '3850', 'ios': '3.6.XE', 'ip': '10.255.0.101' > > lower_london_co = <> for device, params in london_co.items(): lower_london_co[device] = <> for key, value in params.items(): lower_london_co[device][key.lower()] = value In [42]: lower_london_co Out[42]: 'r1': 'hostname': 'london_r1', 'ios': '15.4', 'ip': '10.255.0.1', 'location': '21 New Globe Walk', 'model': '4451', 'vendor': 'Cisco'>, 'r2': 'hostname': 'london_r2', 'ios': '15.4', 'ip': '10.255.0.2', 'location': '21 New Globe Walk', 'model': '4451', 'vendor': 'Cisco'>, 'sw1': 'hostname': 'london_sw1', 'ios': '3.6.XE', 'ip': '10.255.0.101', 'location': '21 New Globe Walk', 'model': '3850', 'vendor': 'Cisco'>>
Аналогичное преобразование с dict comprehensions:
result = device: key.lower(): value for key, value in params.items()> for device, params in london_co.items()> In [44]: result Out[44]: 'r1': 'hostname': 'london_r1', 'ios': '15.4', 'ip': '10.255.0.1', 'location': '21 New Globe Walk', 'model': '4451', 'vendor': 'Cisco'>, 'r2': 'hostname': 'london_r2', 'ios': '15.4', 'ip': '10.255.0.2', 'location': '21 New Globe Walk', 'model': '4451', 'vendor': 'Cisco'>, 'sw1': 'hostname': 'london_sw1', 'ios': '3.6.XE', 'ip': '10.255.0.101', 'location': '21 New Globe Walk', 'model': '3850', 'vendor': 'Cisco'>>
Set comprehensions (генераторы множеств)#
Генераторы множеств в целом аналогичны генераторам списков.
Например, надо получить множество с уникальными номерами VLAN’ов:
vlans = [10, '30', 30, 10, '56'] unique_vlans = int(vlan) for vlan in vlans> In [47]: unique_vlans Out[47]: 10, 30, 56>
Аналогичное решение, без использования set comprehensions:
vlans = [10, '30', 30, 10, '56'] unique_vlans = set() for vlan in vlans: unique_vlans.add(int(vlan)) In [51]: unique_vlans Out[51]: 10, 30, 56>
Генераторы словарей
Некоторые замечательные возможности языка Python незаслуженно оставлены без внимания и многие программисты о них не знают. В этот раз речь пойдет о прекрасной возможности языка, делающей код яснее: генераторы словарей — однострочные выражения, возвращающие словарь. Но начнем с компактных генераторов списков и задачи удаления неуникальных элементов коллекций.
Будет интересно в основном новичкам в Python.
Генераторы списков
Самый простой способ создать список — использовать однострочное выражение — генератор списка. Он довольно часто применяется, и я встречал его во многих примерах и в коде многих библиотек.
Предположим, что у нас есть функция возвращающая какой-то список. Хороший пример — функция range(start, end), которая возвращает числа между start и end. Начиная с версии Python 3.0 она реализована как генератор и возвращает не сразу полный список, а выдает число за числом по мере необходимости. В Python 2.* для этого использовалась функция xrange(). Получение списка чисел от 1 до 10 при помощи этой функции могло бы выглядеть так:
numbers = [] for i in range(1, 11): numbers.append(i) numbers = [] for i in range(1, 11): if i % 2 == 0: numbers.append(i) Генераторы списков делают код намного проще. Так выглядит выражение возвращающее список в общем виде:
[ expression for item in list if conditional ] numbers = [i for i in range(1, 11)] numbers = [i for i in range(1, 11) if i % 2 == 0] Конечно такой синтаксис на первый взгляд может показаться странным, но когда к нему привыкнешь — код станет проще и понятнее.
Удаление дубликатов
Другая часто встречающаяся задача при работе с коллекциями — удаление одинаковых элементов. Ее можно решить множеством методов.
Допустим мы работаем с таким списком:
numbers = [i for i in range(1,11)] + [i for i in range(1,6)] unique_numbers = [] for n in numbers: if n not in unique_numbers: unique_numbers.append(n) Конечно и это работает, но есть решения попроще. Вы можете использовать стандартный тип множество(set). Множества не могу содержать одинаковые элементы по определению, таким образом если конвертировать список во множество — дубликаты удалятся. Но мы получим множество а не список, поэтому если мы хотим именно список уникальных значений — нужно сконвертировать еще раз:
unique_numbers = list(set(numbers)) Удаление одинаковых объектов
Совсем другая ситуация с объектами или словарями. Например у нас есть список словарей, в которых одно из значений используется в качестве идентификатора:
Удаление повторов может может быть реализовано большим или меньшим количеством кода. Конечно, чем меньше — тем лучше! Длинный вариант может выглядеть, например, так:
unique_data = [] for d in data: data_exists = False for ud in unique_data: if ud['id'] == d['id']: data_exists = True break if not data_exists: unique_data.append(d) Можно получить то же результат, используя возможность, о которой я узнал пару дней назад: генераторы словарей. Они имеют похожий на генераторы списков синтаксис, но возвращают словарь:
В этой строчке кода создается словарь, ключами которого являются поля, которые мы приняли за уникальный идентификатор, затем с помощью метода values() получаем все значения из созданного словаря. Т.к. словарь может содержать не больше одной записи для каждого ключа — полученный в итоге список не содержит дубликатов, что нам и требовалось.
Данная возможность была добавлена в Python 3.0 и бэкпортирована в Python 2.7, В более ранних версиях для решения подобной задачи можно использовать конструкцию такого вида:
dict((key, value) for item in list if condition) Генерируется список кортежей (пар) и передается их конструктору dict(), который берет первый элемент кортежа как ключ, а второй как значение. При таком подходе решение всё той же задачи будет выглядеть так:
dict((d['id'], d) for d in data).values()