- Using filters and sorts¶
- Advanced filters¶
- CustomFilter¶
- DateGroupItem¶
- Working with Autofilters
- Applying an autofilter
- Filter data in an autofilter
- Setting a filter criteria for a column
- Setting a column list filter
- Example
- How to Filter Data from an Excel File in Python with Pandas
- Method 1: Use read_excel() and the & operator
- Import the Excel File to Python
- Filter the DataFrame
- Contents of Filtered Excel File
Using filters and sorts¶
It’s possible to filter single range of values in a worksheet by adding an autofilter. If you need to filter multiple ranges, you can use tables and apply a separate filter for each table.
Filters and sorts can only be configured by openpyxl but will need to be applied in applications like Excel. This is because they actually rearrange, format and hide rows in the range.
To add a filter you define a range and then add columns. You set the range over which the filter by setting the ref attribute. Filters are then applied to columns in the range using a zero-based index, eg. in a range from A1:H10, colId 1 refers to column B. Openpyxl does not check the validity of such assignments.
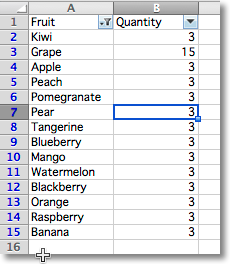
from openpyxl import Workbook from openpyxl.worksheet.filters import ( FilterColumn, CustomFilter, CustomFilters, DateGroupItem, Filters, ) wb = Workbook() ws = wb.active data = [ ["Fruit", "Quantity"], ["Kiwi", 3], ["Grape", 15], ["Apple", 3], ["Peach", 3], ["Pomegranate", 3], ["Pear", 3], ["Tangerine", 3], ["Blueberry", 3], ["Mango", 3], ["Watermelon", 3], ["Blackberry", 3], ["Orange", 3], ["Raspberry", 3], ["Banana", 3] ] for r in data: ws.append(r) filters = ws.auto_filter filters.ref = "A1:B15" col = FilterColumn(colId=0) # for column A col.filters = Filters(filter=["Kiwi", "Apple", "Mango"]) # add selected values filters.filterColumn.append(col) # add filter to the worksheet ws.auto_filter.add_sort_condition("B2:B15") wb.save("filtered.xlsx")
This will add the relevant instructions to the file but will neither actually filter nor sort.
Advanced filters¶
The following predefined filters can be used: CustomFilter, DateGroupItem, DynamicFilter, ColorFilter, IconFilter and Top10 ColorFilter, IconFilter and Top10 all interact with conditional formats.
The signature and structure of the different kinds of filter varies significantly. As such it makes sense to familiarise yourself with either the openpyxl source code or the OOXML specification.
CustomFilter¶
CustomFilters can have one or two conditions which will operate either independently (the default), or combined by setting the and_ attribute. Filter can use the following operators: ‘equal’, ‘lessThan’, ‘lessThanOrEqual’, ‘notEqual’, ‘greaterThanOrEqual’, ‘greaterThan’ .
from openpyxl.worksheet.filters import CustomFilter, CustomFilters flt1 = CustomFilter(operator="lessThan", val=10) flt2 = CustomFilter(operator=greaterThan, val=90) cfs = CustomFilters(customFilter=[flt1, flt2]) col = FilterColumn(colId=2, customFilters=cfs) # apply to **third** column in the range filters.filter.append(col)
In addition, Excel has non-standardised functionality for pattern matching with strings. The options in Excel: begins with, ends with, contains and their negatives are all implemented using the equal (or for negatives notEqual ) operator and wildcard in the value.
For example: for “begins with a”, use a* ; for “ends with a”, use *a ; and for “contains a””, use *a* .
DateGroupItem¶
Date filters can be set to allow filtering by different datetime criteria such as year, month or hour. As they are similar to lists of values you can have multiple items.
To filter by the month of March:
from openpyxl.worksheet.filters import DateGroupItem df1 = DateGroupItem(month=3, dateTimeGrouping="month") col = FilterColumn(colId=1) # second column col.filters.dateGroupItem.append(df1) df2 = DateGroupItem(year=1984, dateTimeGrouping="year") # add another element col.filters.dateGroupItem.append(df2) filters.filter.append(col)
© Copyright 2010 — 2023, See AUTHORS Revision de5eaa97998c .
Versions latest stable 3.1.2 3.1.1 3.1.0 3.1 3.0 2.6 2.5.14 2.5 2.4 Downloads html On Read the Docs Project Home Builds Free document hosting provided by Read the Docs.
Working with Autofilters
An autofilter in Excel is a way of filtering a 2D range of data based on some simple criteria.
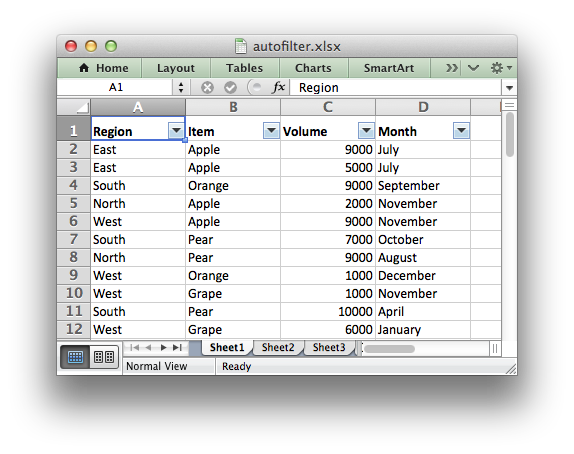
Applying an autofilter
The first step is to apply an autofilter to a cell range in a worksheet using the autofilter() method:
As usual you can also use Row-Column notation:
worksheet.autofilter(0, 0, 10, 3) # Same as above.
Filter data in an autofilter
The autofilter() defines the cell range that the filter applies to and creates drop-down selectors in the heading row. In order to filter out data it is necessary to apply some criteria to the columns using either the filter_column() or filter_column_list() methods.
The filter_column method is used to filter columns in a autofilter range based on simple criteria:
worksheet.filter_column('A', 'x > 2000') worksheet.filter_column('B', 'x > 2000 and x < 5000')
It isn’t sufficient to just specify the filter condition. You must also hide any rows that don’t match the filter condition. Rows are hidden using the set_row() hidden parameter. XlsxWriter cannot filter rows automatically since this isn’t part of the file format.
The following is an example of how you might filter a data range to match an autofilter criteria:
# Set the autofilter. worksheet.autofilter('A1:D51') # Add the filter criteria. The placeholder "Region" in the filter is # ignored and can be any string that adds clarity to the expression. worksheet.filter_column(0, 'Region == East') # Hide the rows that don't match the filter criteria. row = 1 for row_data in (data): region = row_data[0] # Check for rows that match the filter. if region == 'East': # Row matches the filter, display the row as normal. pass else: # We need to hide rows that don't match the filter. worksheet.set_row(row, options='hidden': True>) worksheet.write_row(row, 0, row_data) # Move on to the next worksheet row. row += 1
Setting a filter criteria for a column
The filter_column() method can be used to filter columns in a autofilter range based on simple conditions:
worksheet.filter_column('A', 'x > 2000')
The column parameter can either be a zero indexed column number or a string column name.
The following operators are available for setting the filter criteria:
An expression can comprise a single statement or two statements separated by the and and or operators. For example:
'x < 2000''x > 2000' 'x == 2000' 'x > 2000 and x < 5000''x == 2000 or x == 5000'
Filtering of blank or non-blank data can be achieved by using a value of Blanks or NonBlanks in the expression:
Excel also allows some simple string matching operations:
'x == b*' # begins with b 'x != b*' # doesn't begin with b 'x == *b' # ends with b 'x != *b' # doesn't end with b 'x == *b*' # contains b 'x != *b*' # doesn't contain b
You can also use ‘*’ to match any character or number and ‘?’ to match any single character or number. No other regular expression quantifier is supported by Excel’s filters. Excel’s regular expression characters can be escaped using ‘~’ .
The placeholder variable x in the above examples can be replaced by any simple string. The actual placeholder name is ignored internally so the following are all equivalent:
A filter condition can only be applied to a column in a range specified by the autofilter() method.
Setting a column list filter
Prior to Excel 2007 it was only possible to have either 1 or 2 filter conditions such as the ones shown above in the filter_column() method.
Excel 2007 introduced a new list style filter where it is possible to specify 1 or more ‘or’ style criteria. For example if your column contained data for the months of the year you could filter the data based on certain months:
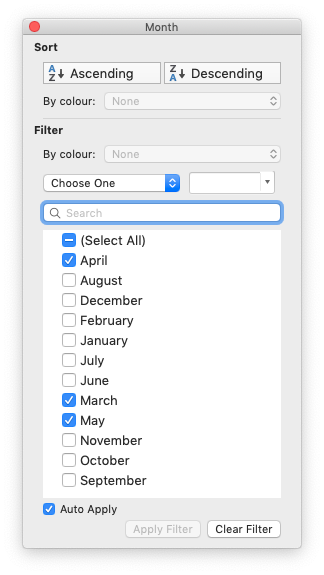
The filter_column_list() method can be used to represent these types of filters:
worksheet.filter_column_list('A', ['March', 'April', 'May'])
One or more criteria can be selected:
worksheet.filter_column_list('A', ['March']) worksheet.filter_column_list('B', [100, 110, 120, 130])
To filter blanks as part of the list use Blanks as a list item:
worksheet.filter_column_list('A', ['March', 'April', 'May', 'Blanks'])
As explained above, it isn’t sufficient to just specify filters. You must also hide any rows that don’t match the filter condition.
Example
See Example: Applying Autofilters for a full example of all these features.
© Copyright 2013-2023, John McNamara.
Created using Sphinx 1.8.6.
How to Filter Data from an Excel File in Python with Pandas

This article will show different ways to read and filter an Excel file in Python.
To make it more interesting, we have the following scenario:
Sven is a Senior Coder at K-Paddles. K-Paddles manufactures Kayak Paddles made of Kevlar for the White Water Rafting Community. Sven has been asked to read an Excel file and run reports. This Excel file contains two (2) worksheets, Employees and Sales.

To follow along, download the kp_data.xlsx file and place it into the current working directory.
💬 Question: How would we write code to filter an Excel file in Python?
We can accomplish this task by one of the following options:
- Method 1: Use read_excel() and the & operator
- Method 2: Use read_excel() and loc[]
- Method 3: Use read_excel() and iloc[]
- Method 4: Use read_excel() , index[] and loc[]
- Method 5: Use read_excel() and isin()
Method 1: Use read_excel() and the & operator
This method uses the read_excel() function to read an XLSX file into a DataFrame and an expression to filter the results.
This example imports the above-noted Excel file into a DataFrame. The Employees worksheet is accessed, and the following filter is applied:
👀 Give me the DataFrame rows for all employees who work in the Sales Department, and earn more than $55,000/annum.
Let’s convert this to Python code.
import pandas as pd cols = ['First', 'Last', 'Dept', 'Salary'] df_emps = pd.read_excel('kp_data.xlsx', sheet_name='Employees', usecols=cols) df_salary = df_emps[(df_emps['Dept'] == 'Sales') & (df_emps['Salary'] > 55000)] df_salary.to_excel('sales_55.xlsx', sheet_name='Sales Salaries Greater Than 55K') The first line in the above code snippet imports the Pandas library. This allows access to and manipulation of the XLSX file. Just so you know, the openpyxl library must be installed before continuing.
The following line defines the four (4) columns to retrieve from the XLSX file and saves them to the variable cols as a List.
💡Note: Open the Excel file and review the data to follow along.
Import the Excel File to Python
On the next line in the code snippet, read_excel() is called and passed three (3) arguments:
- The name of the Excel file to import ( kp_data.xlsx ).
- The worksheet name. The first worksheet in the Excel file is always read unless stated otherwise. For this example, our Excel file contains two (2) worksheets: Employees and Sales . The Employees worksheet can be referenced using sheet_name=0 or sheet_name=’Employees’ . Both produce the same result.
- The columns to retrieve from the Excel workheet ( usecols=cols ).
The results save to df_emps .
Filter the DataFrame
The highlighted line applies a filter that references the DataFrame columns to base the filter on and the & operator to allow for more than one (1) filter criteria.
df_salary = df_emps[(df_emps['Dept'] == 'Sales') & (df_emps['Salary'] > 55000)]
👀 Give me the DataFrame rows for all employees who work in the Sales Department, and earn more than $55,000/annum.
These results save to sales_55.xlsx with a worksheet ‘ Sales Salaries Greater Than 55K ‘ and placed into the current working directory.
Contents of Filtered Excel File



At university, I found my love of writing and coding. Both of which I was able to use in my career.
During the past 15 years, I have held a number of positions such as:
In-house Corporate Technical Writer for various software programs such as Navision and Microsoft CRM
Corporate Trainer (staff of 30+)
Programming Instructor
Implementation Specialist for Navision and Microsoft CRM
Senior PHP Coder
Be on the Right Side of Change 🚀
- The world is changing exponentially. Disruptive technologies such as AI, crypto, and automation eliminate entire industries. 🤖
- Do you feel uncertain and afraid of being replaced by machines, leaving you without money, purpose, or value? Fear not! There a way to not merely survive but thrive in this new world!
- Finxter is here to help you stay ahead of the curve, so you can keep winning as paradigms shift.
Learning Resources 🧑💻
⭐ Boost your skills. Join our free email academy with daily emails teaching exponential with 1000+ tutorials on AI, data science, Python, freelancing, and Blockchain development!
Join the Finxter Academy and unlock access to premium courses 👑 to certify your skills in exponential technologies and programming.
New Finxter Tutorials:
Finxter Categories: